【场景描述】本文以西瓜视频为例,向大家介绍如何采集直播视频及主播信息。
【使用工具】前嗅ForeSpider数据采集系统,点击下方即可免费下载
【使用工具】前嗅ForeSpider数据采集系统,点击下方链接即可免费下载。
【入口网址】https://live.ixigua.com/category/1/109/
【采集内容】
采集西瓜视频中的所有直播视频及主播信息,包括主播昵称、房间号、视频地址、网站名称、直播网址、直播视频、采集时间、主播热度。

【采集效果】
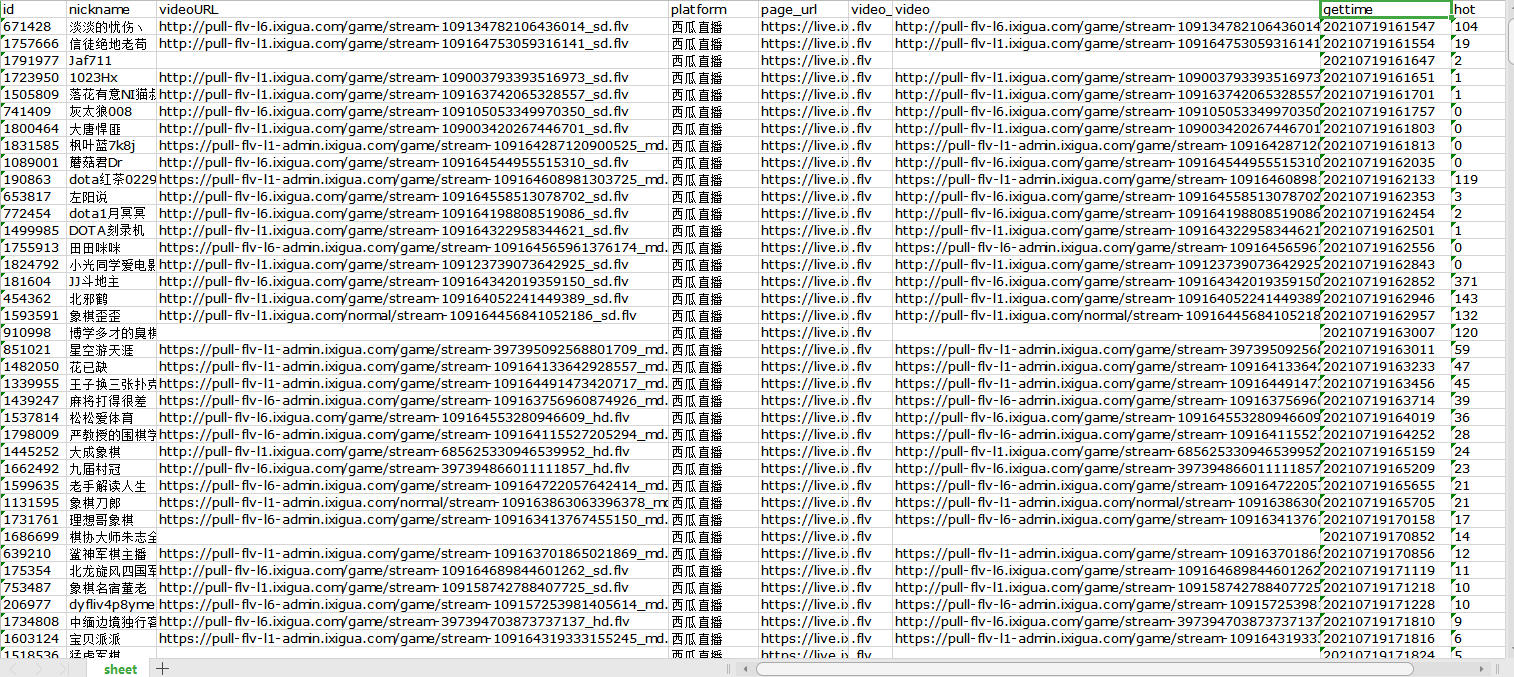
l 思路分析
配置思路概览:

l 配置步骤
1. 新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
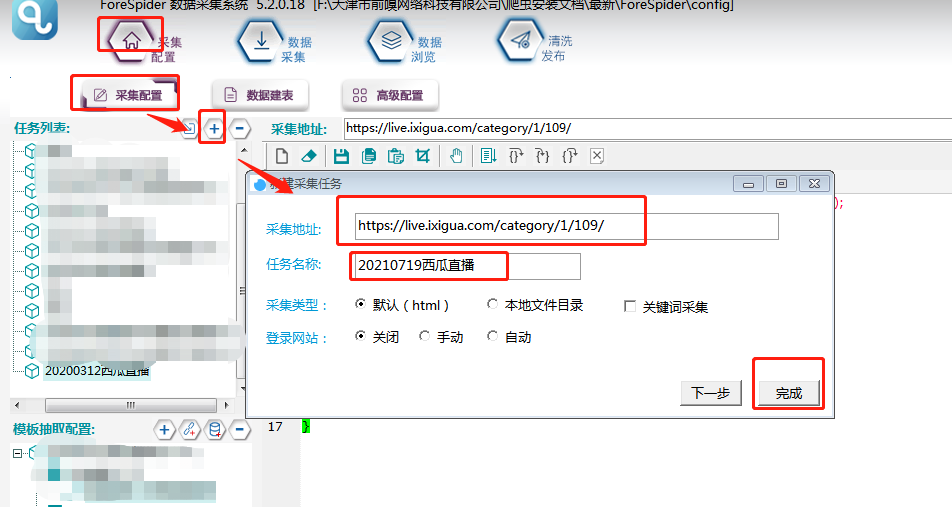
选择普通翻页,点击完成按钮,即创建任务完成。
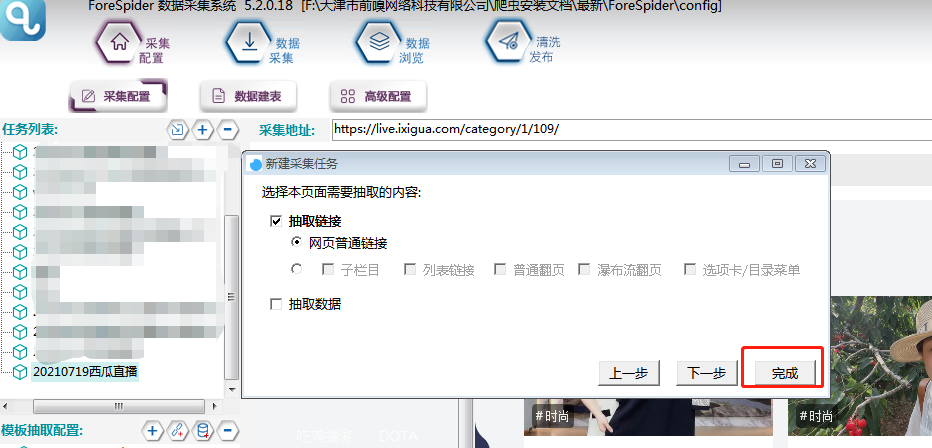
2. 直播分类链接获取
①在浏览器中点击不同分类的直播,将对应链接复制出来,观察链接规律。

发现不同分类直播的链接规律为:
https://live.ixigua.com/category/1/分类id/
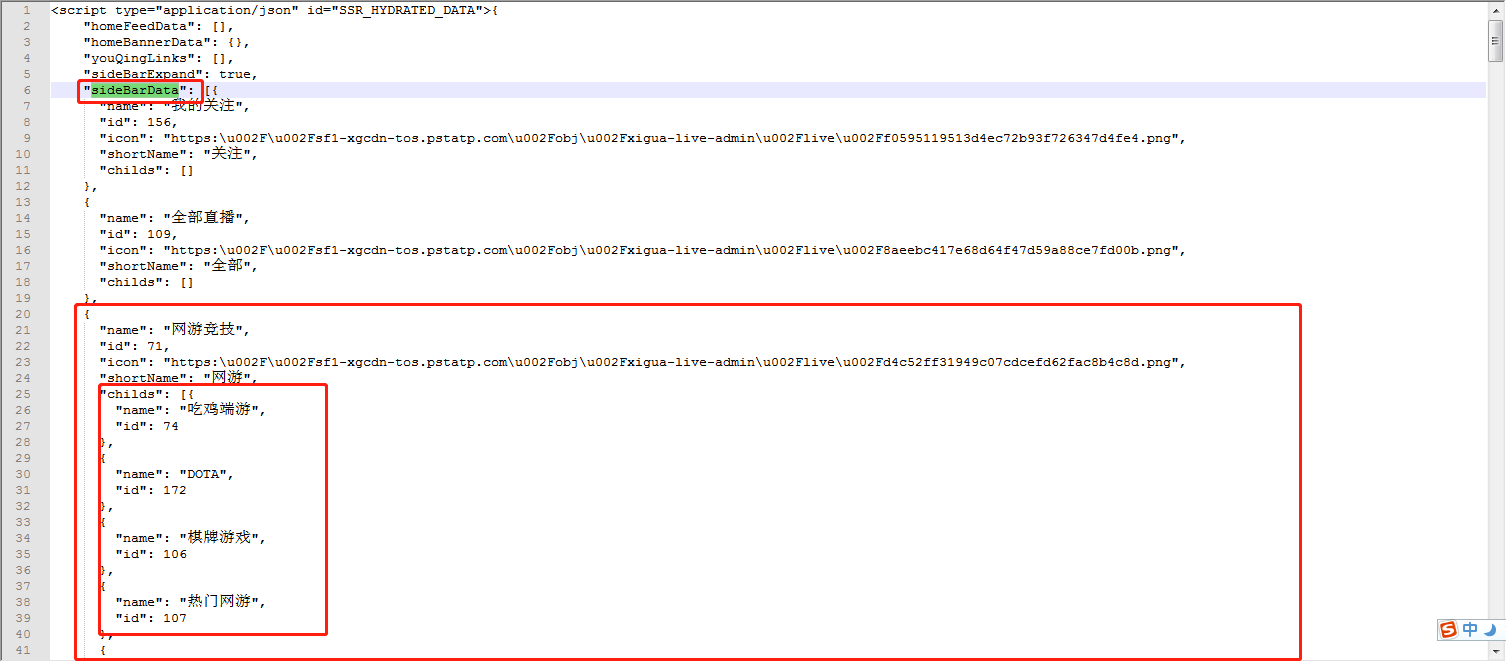
②点击页面右键【查看源文件】,在源码中查找分类id,发现分类id在源码的js中。

将该段源码复制进行js格式化在线转化,可更加清楚的看到结构。如下图所示能够看出,我们需要的分类名称和id是在【sideBarData】数组的第三个对象中的【childs】数组中。
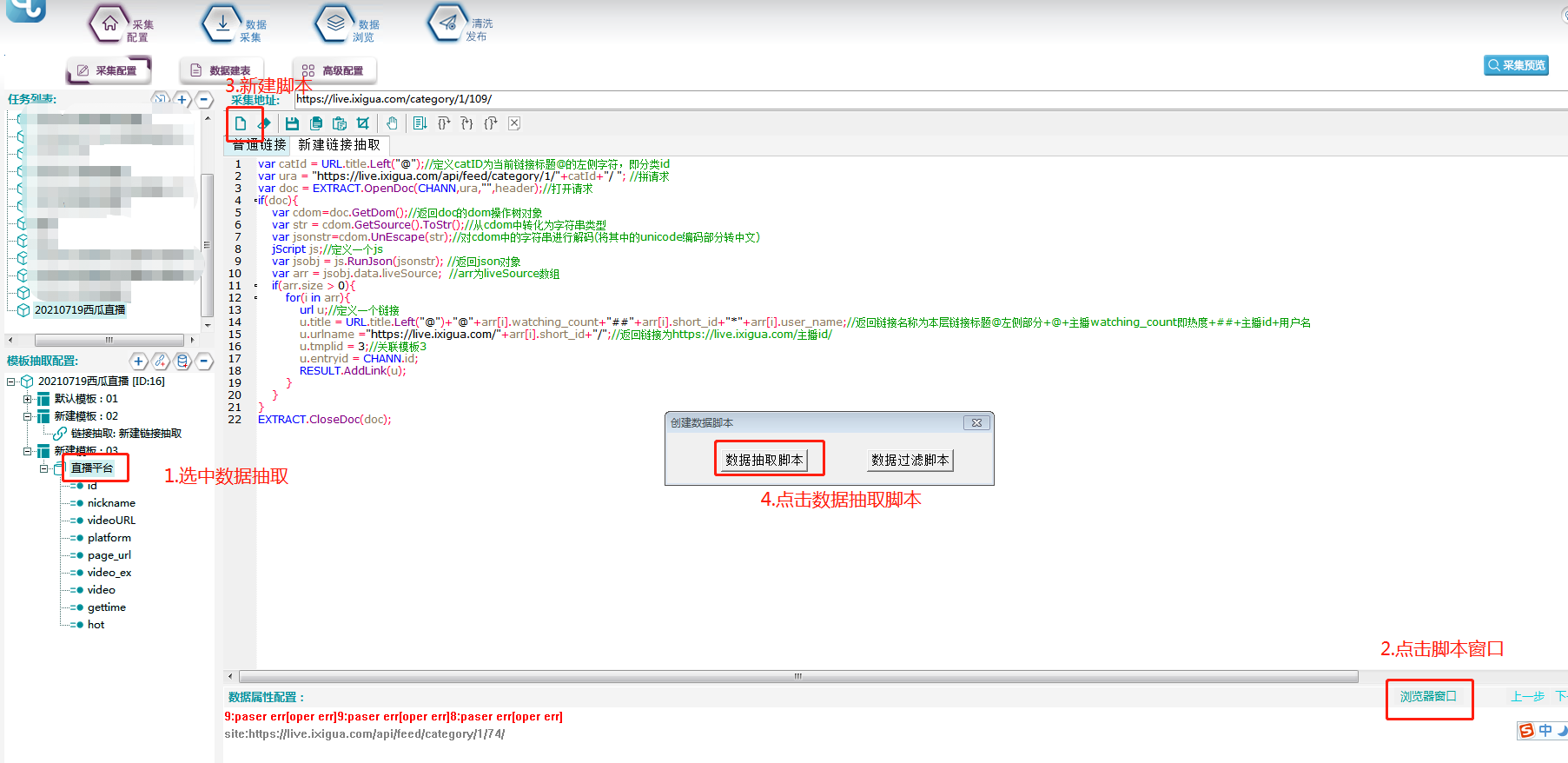
③打开脚本窗口,新建脚本。
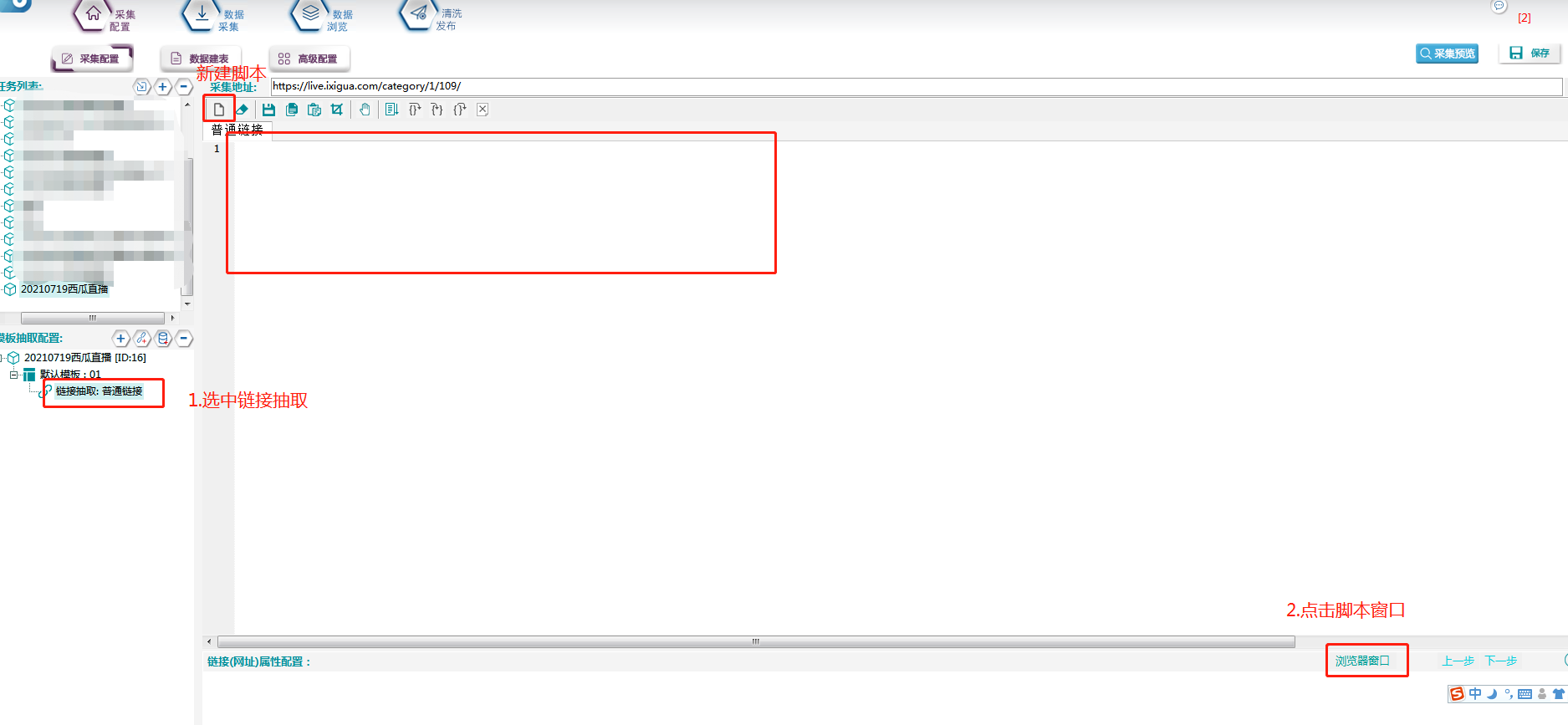
根据刚才发现的规律,用脚本来拼分类链接,编写好后点击右上角保存。
具体如下所示:
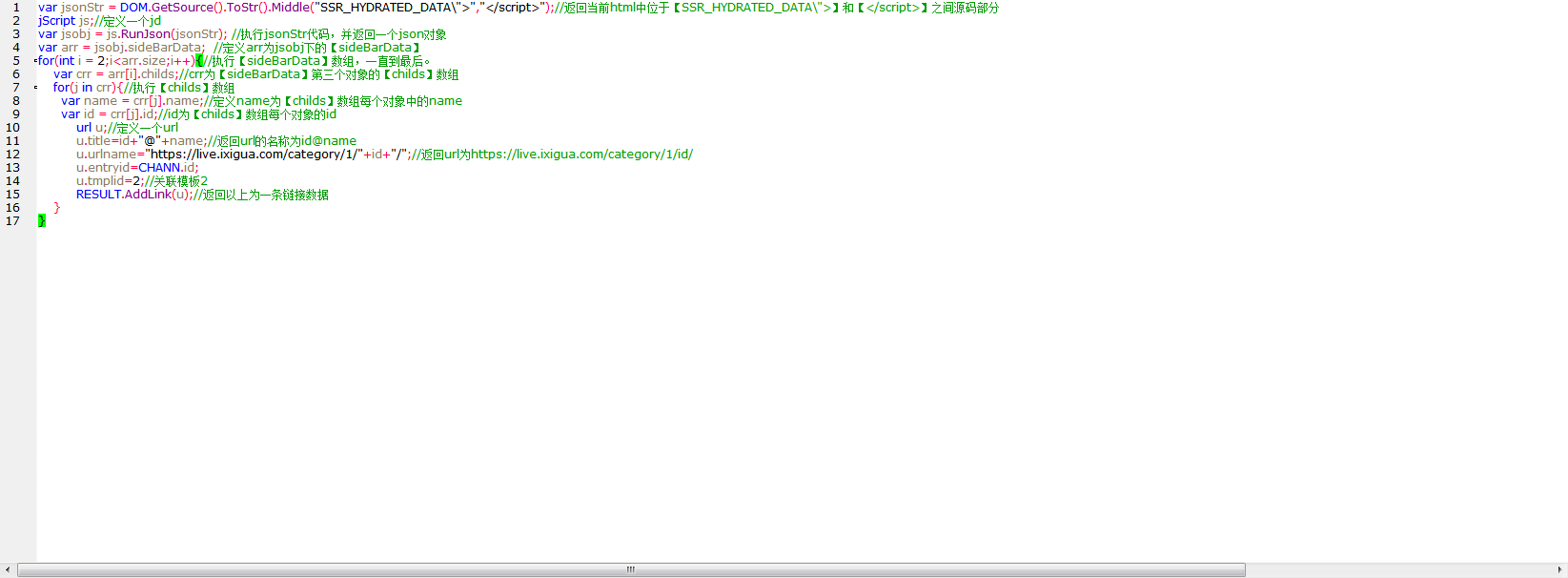
脚本文本:
var jsonStr = DOM.GetSource().ToStr().Middle("SSR_HYDRATED_DATA\">","</script>");//返回当前html中位于【SSR_HYDRATED_DATA\">】和【</script>】之间源码部分
jScript js;//定义一个jd
var jsobj = js.RunJson(jsonStr); //执行jsonStr代码,并返回一个json对象
var arr = jsobj.sideBarData; //定义arr为jsobj下的【sideBarData】
for(int i = 2;i<arr.size;i++){//执行【sideBarData】数组,一直到最后。
var crr = arr[i].childs;//crr为【sideBarData】第三个对象的【childs】数组
for(j in crr){//执行【childs】数组
var name = crr[j].name;//定义name为【childs】数组每个对象中的name
var id = crr[j].id;//id为【childs】数组每个对象的id
url u;//定义一个url
u.title=id+"@"+name;//返回url的名称为id@name
u.urlname="https://live.ixigua.com/category/1/"+id+"/";//返回url为https://live.ixigua.com/category/1/id/
u.entryid=CHANN.id;
u.tmplid=2;//关联模板2
RESULT.AddLink(u);//返回以上为一条链接数据
}
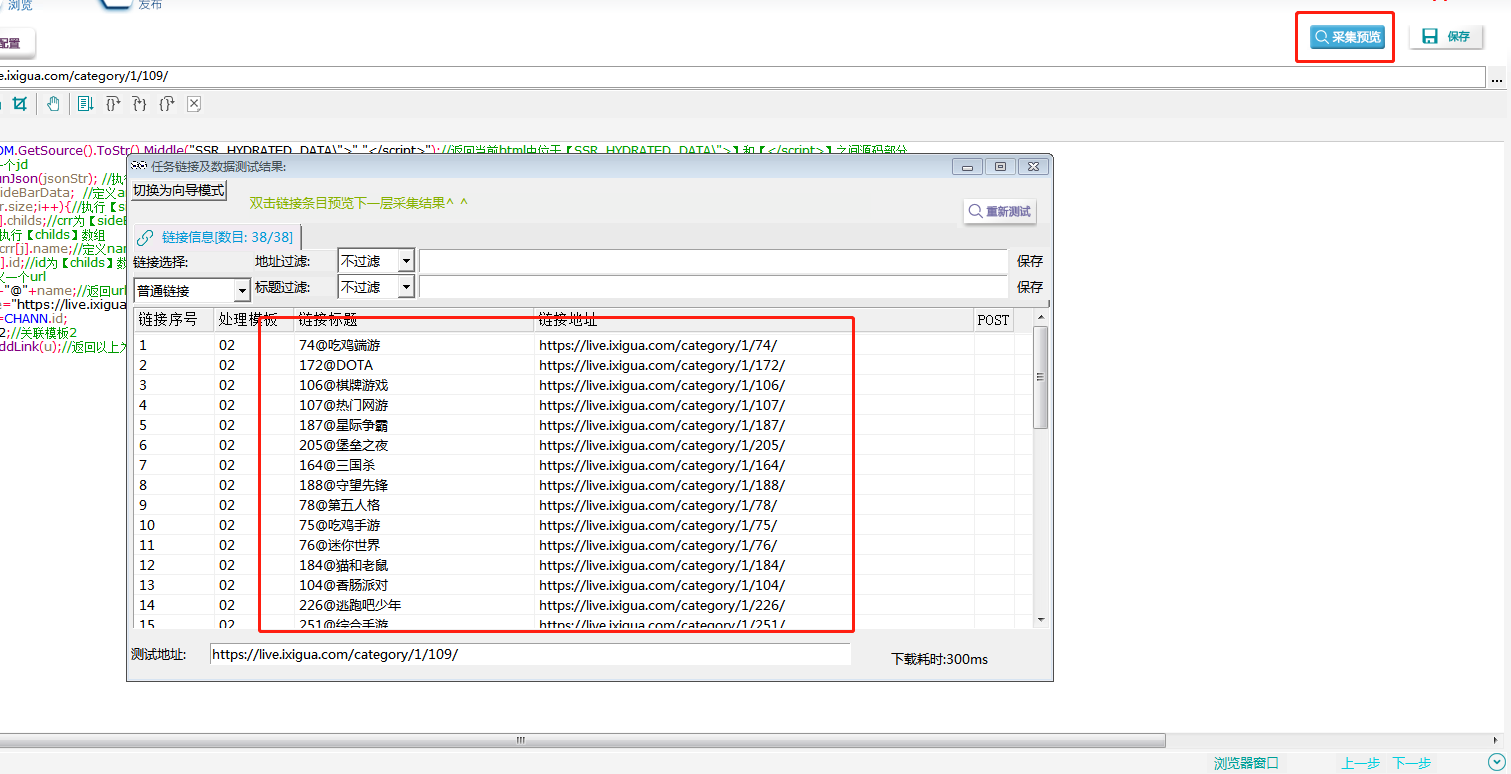
}④采集预览,复制任意一条分类链接,在浏览器中打开,看是否为该页内容。
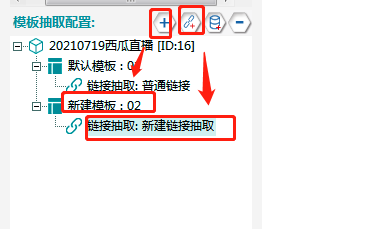
3.各主播直播链接
①新建模板02,在模板02下建一个链接抽取,具体操作如下图所示。
②在浏览器上打开任意一个分类,复制价格主播直播链接,观察其规律,具体如下:

③不难发现主播直播规律为:https://live.ixigua.com/主播id/
④点击F12,查看请求,发现主播id在下图所示请求中https://live.ixigua.com/api/feed/category/1/74?_signature=iYkdqAAgEB7evlXzywm4yYmJHbAAOmK
(测试发现链接后半部分不加也可以打开该请求,故脚本中省略后半部分)
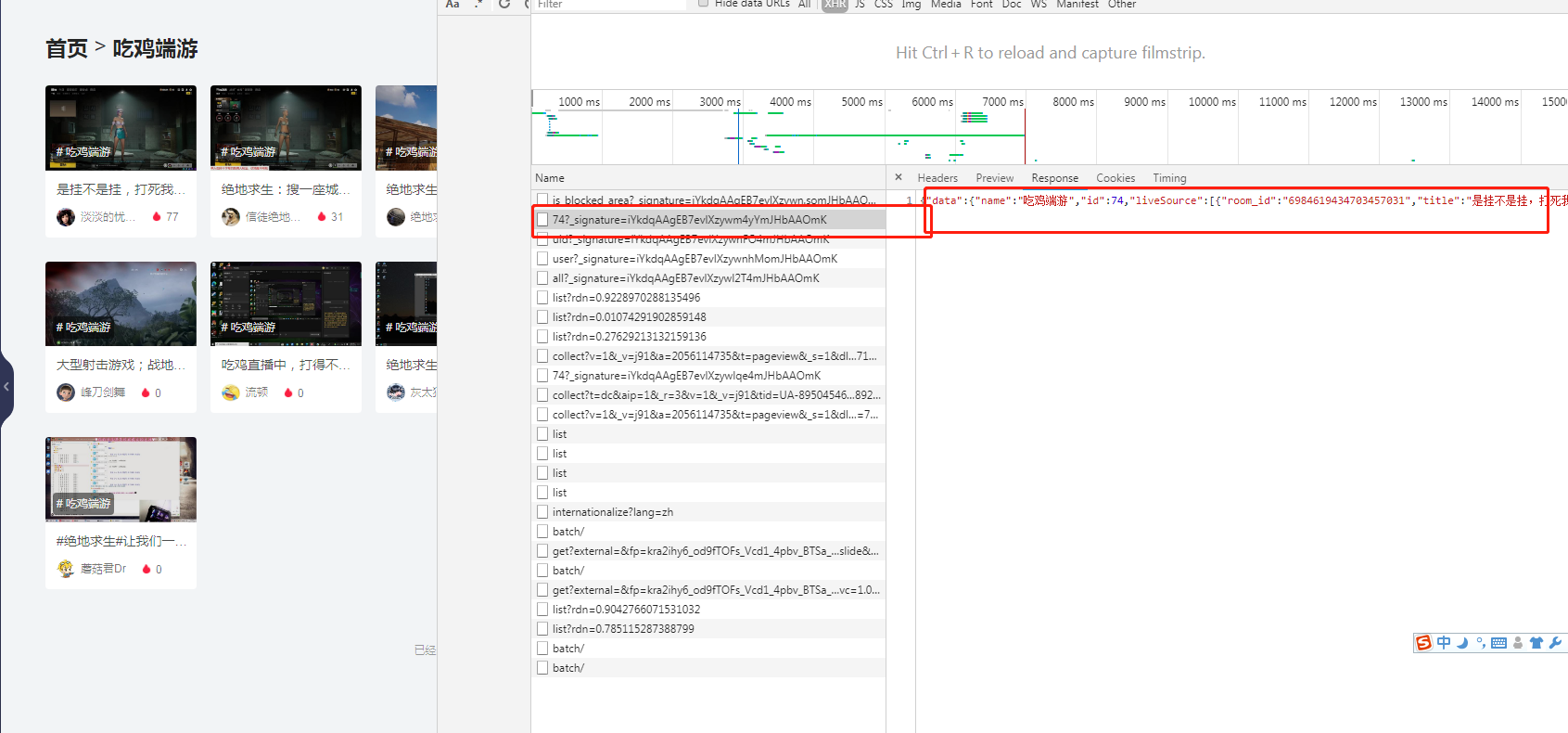
请求地址规律为:https://live.ixigua.com/api/feed/category/1/分类id
⑤根据刚才发现的规律,用脚本来拼分类请求链接,获取到请求中的源码,从而拼出主播页面链接。
具体如下所示:
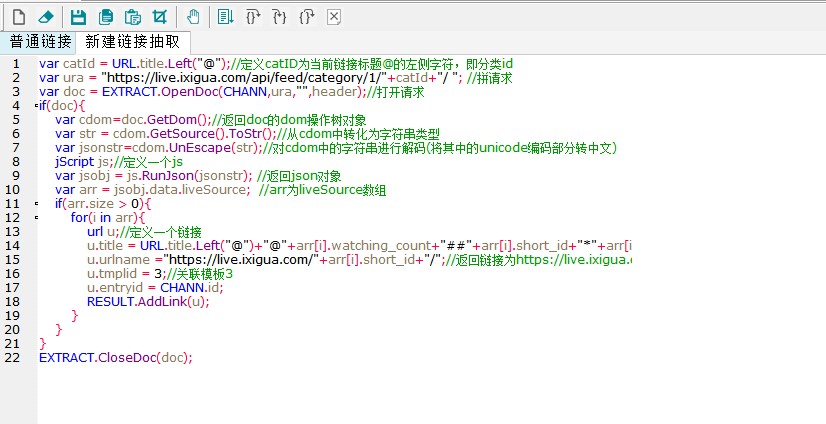
脚本文本:
var catId = URL.title.Left("@");//定义catID为当前链接标题@的左侧字符,即分类id
var ura = "https://live.ixigua.com/api/feed/category/1/"+catId+"/ "; //拼请求
var doc = EXTRACT.OpenDoc(CHANN,ura,"",header);//打开请求
if(doc){
var cdom=doc.GetDom();//返回doc的dom操作树对象
var str = cdom.GetSource().ToStr();//从cdom中转化为字符串类型
var jsonstr=cdom.UnEscape(str);//对cdom中的字符串进行解码(将其中的unicode编码部分转中文)
jScript js;//定义一个js
var jsobj = js.RunJson(jsonstr); //返回json对象
var arr = jsobj.data.liveSource; //arr为liveSource数组
if(arr.size > 0){
for(i in arr){
url u;//定义一个链接
u.title = URL.title.Left("@")+"@"+arr[i].watching_count+"##"+arr[i].short_id+"*"+arr[i].user_name;//返回链接名称为本层链接标题@左侧部分+@+主播watching_count即热度+##+主播id+用户名
u.urlname ="https://live.ixigua.com/"+arr[i].short_id+"/";//返回链接为https://live.ixigua.com/主播id/
u.tmplid = 3;//关联模板3
u.entryid = CHANN.id;
RESULT.AddLink(u);
}
}
}
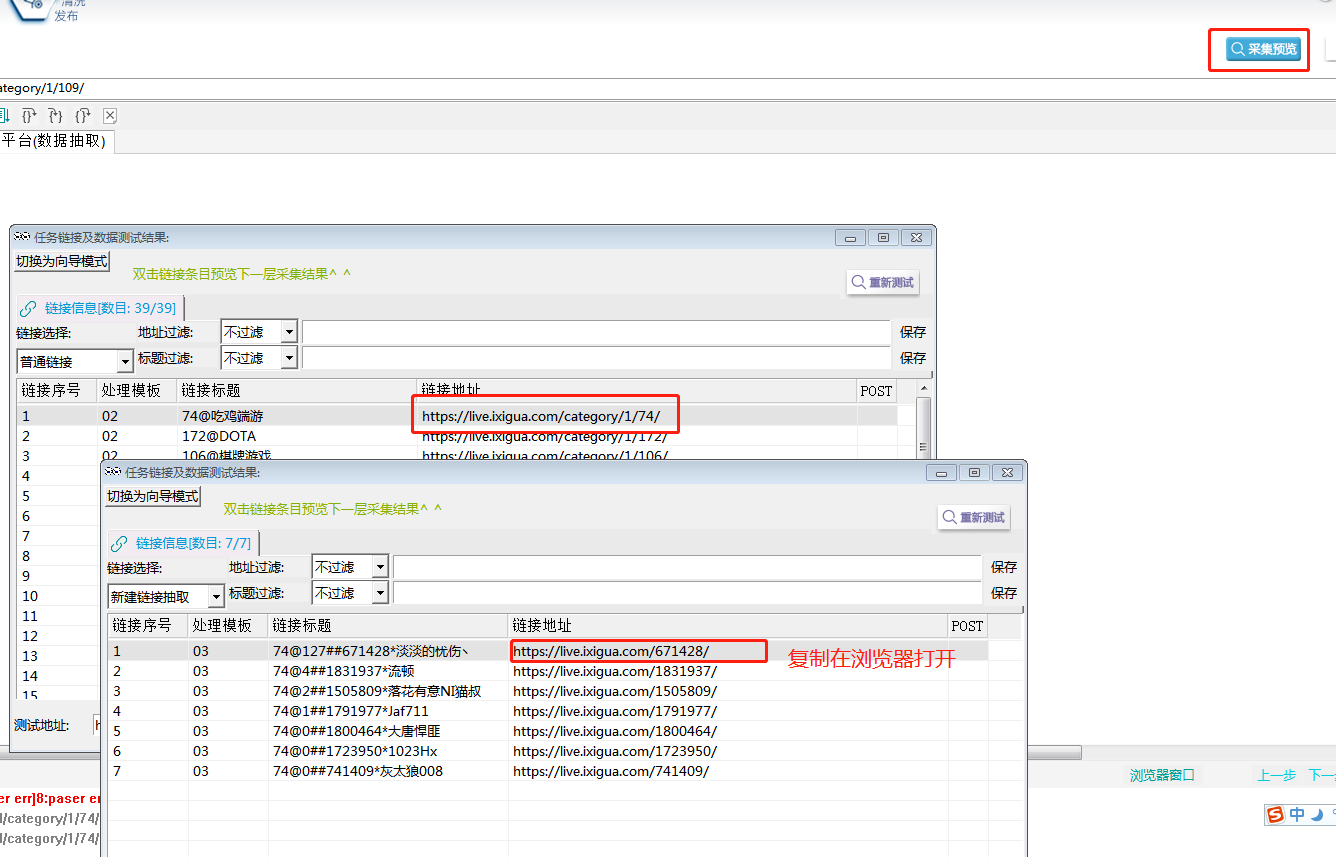
EXTRACT.CloseDoc(doc);⑥保存脚本后,点击右上角【采集预览】按钮,双击任意一条链接,进入下一层,复制任意一条主播链接,在浏览器打开,看是否成功抽取主播链接。

3.抽取主播数据
①新建一个抽取模板,在其下新建一个数据抽取,具体操作如下所示:
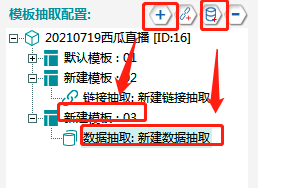
②数据建表
点击图中加号,新建一个数据表,然后添加字段,各字段属性如下图所示:
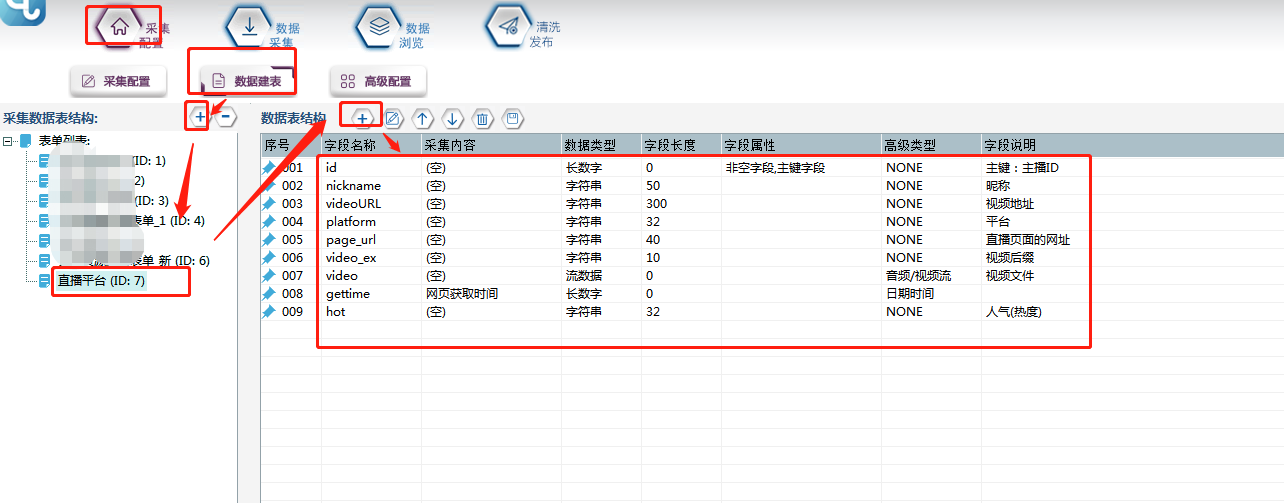
③将新建好的数据表,关联到模板中去,如下图所示:
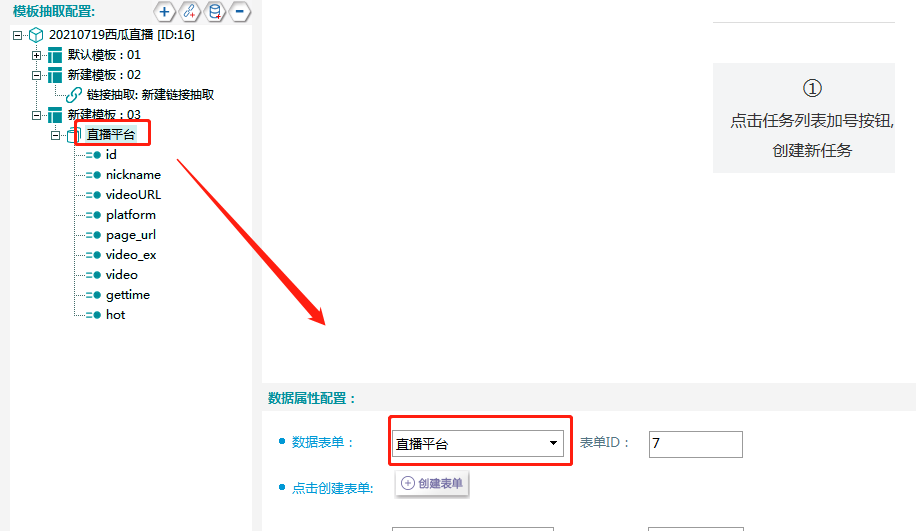
④字段抽取
字段抽取使用脚本抽取的方法,在数据抽取模板中新建一个脚本窗口。
⑤采集预览,复制一条翻页的链接,在浏览器中打开。
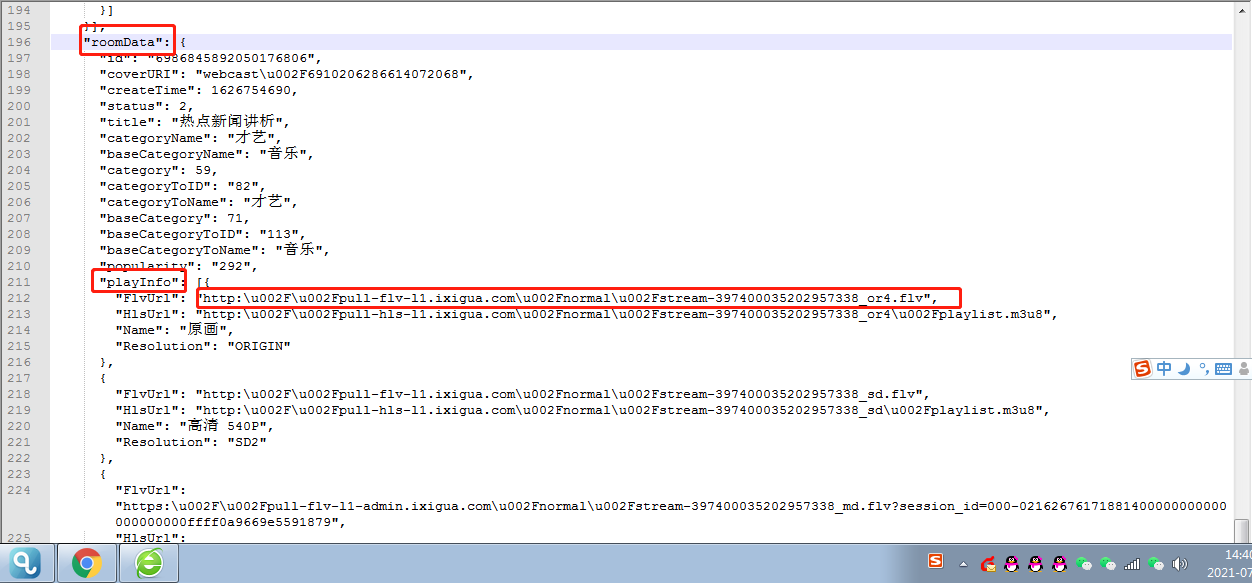
⑥鼠标单击右键,查看源文件,观察可发现直播视频链接在如下图所示位置。

将以上一段js格式化后,观察其位置,为【roomData】节点下的【playInfo】数组的第一个数组对象的FlvUrl。且本视频链接部分为unicode编码,需要转码一下。
⑦根据以上观察,编写数据抽取脚本,具体如下图所示:
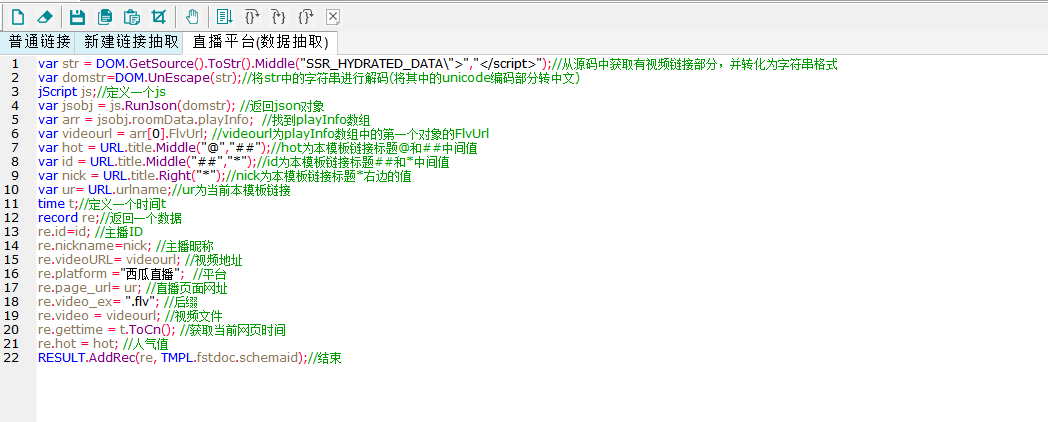
脚本文本如下所示:
var str = DOM.GetSource().ToStr().Middle("SSR_HYDRATED_DATA\">","</script>");//从源码中获取有视频链接部分,并转化为字符串格式
var domstr=DOM.UnEscape(str);//将str中的字符串进行解码(将其中的unicode编码部分转中文)
jScript js;//定义一个js
var jsobj = js.RunJson(domstr); //返回json对象
var arr = jsobj.roomData.playInfo; //找到playInfo数组
var videourl = arr[0].FlvUrl; //videourl为playInfo数组中的第一个对象的FlvUrl
var hot = URL.title.Middle("@","##");//hot为本模板链接标题@和##中间值
var id = URL.title.Middle("##","*");//id为本模板链接标题##和*中间值
var nick = URL.title.Right("*");//nick为本模板链接标题*右边的值
var ur= URL.urlname;//ur为当前本模板链接
time t;//定义一个时间t
record re;//返回一个数据
re.id=id; //主播ID
re.nickname=nick; //主播昵称
re.videoURL= videourl; //视频地址
re.platform ="西瓜直播"; //平台
re.page_url= ur; //直播页面网址
re.video_ex= ".flv"; //后缀
re.video = videourl; //视频文件
re.gettime = t.ToCn(); //获取当前网页时间
re.hot = hot; //人气值
RESULT.AddRec(re, TMPL.fstdoc.schemaid);//结束⑧采集预览
点击右上角采集预览,如下图所示:
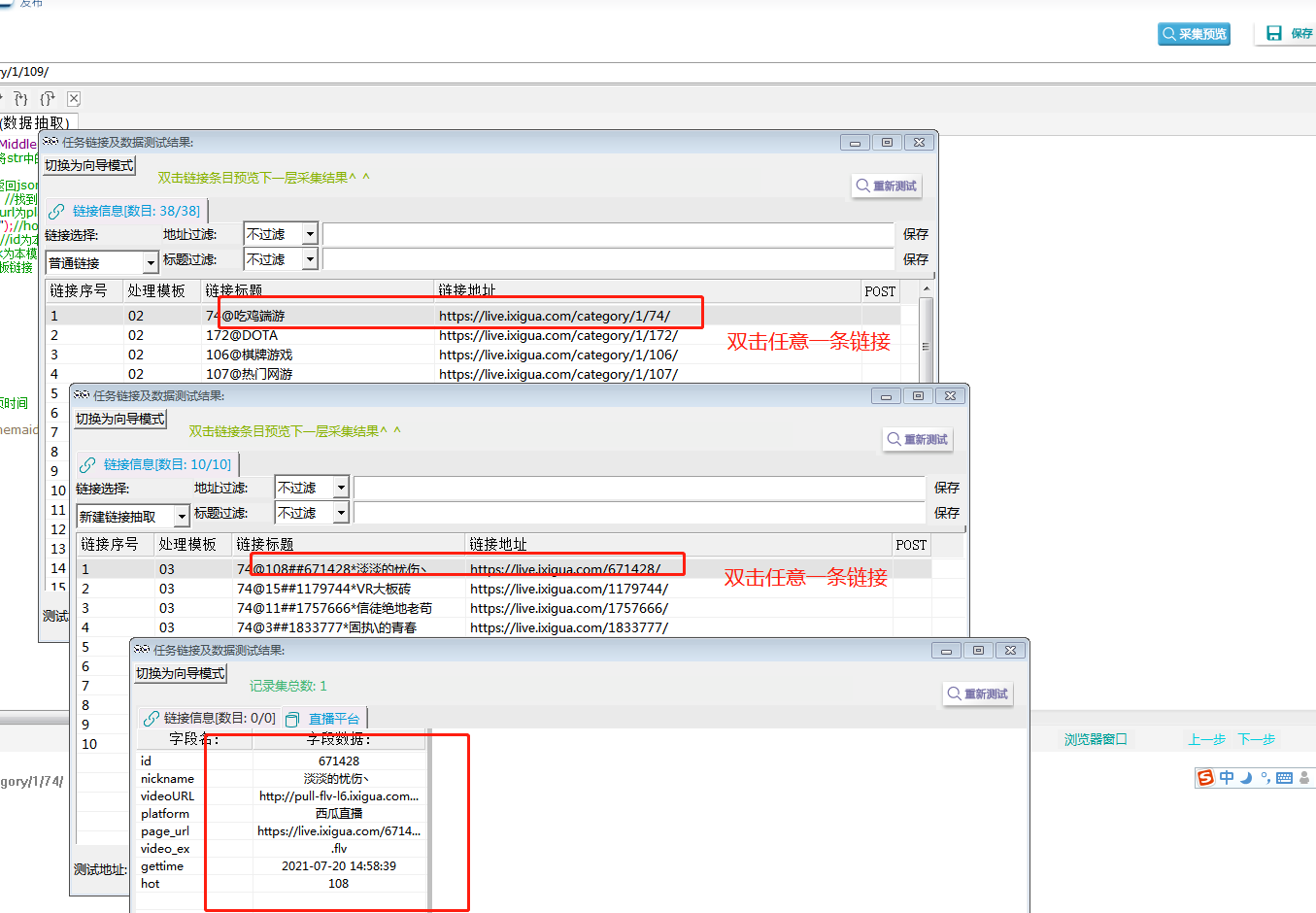
l 采集步骤
模板配置完成,采集预览没有问题后,可以进行数据采集。
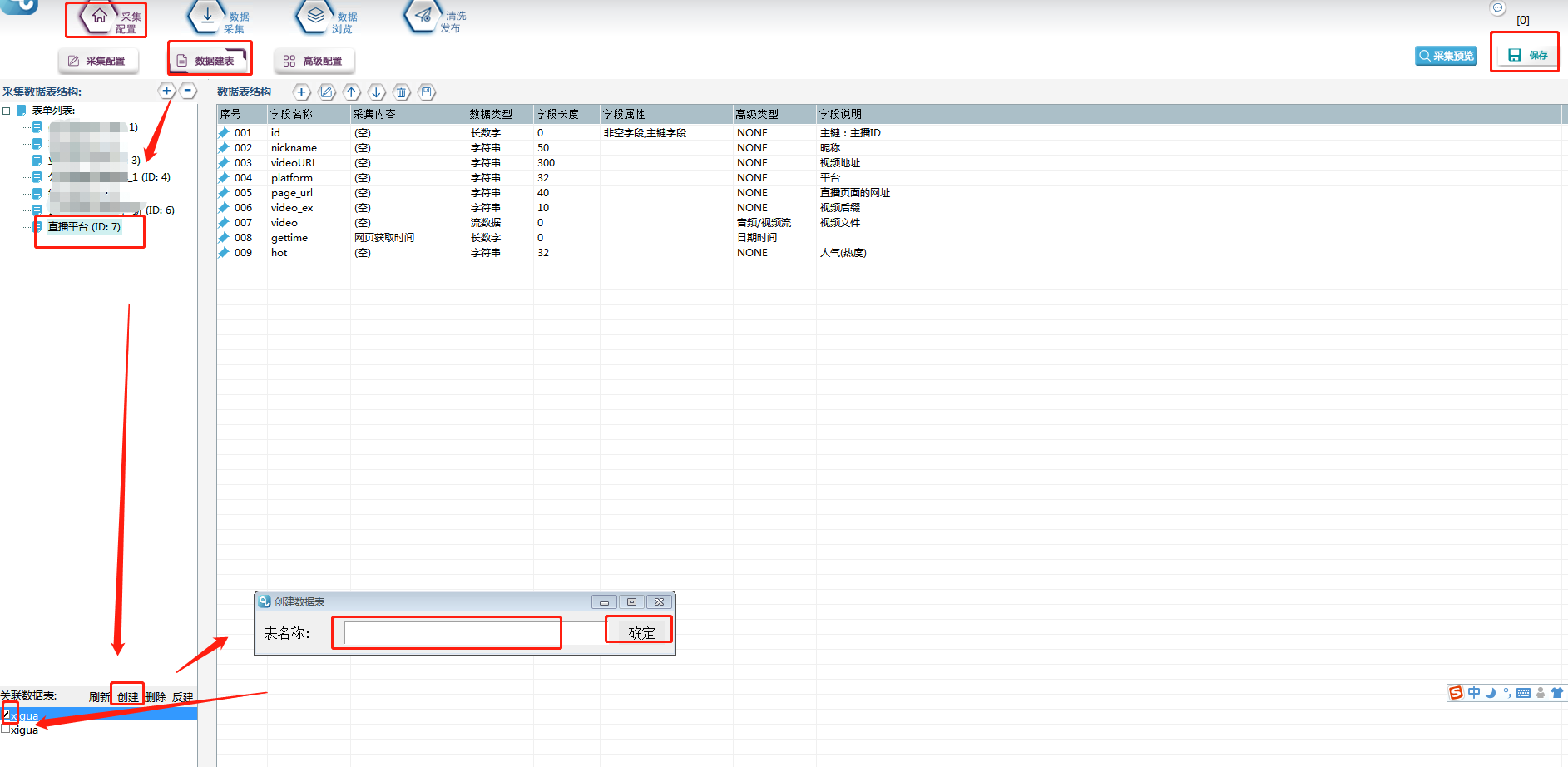
①首先要建立采集数据表:
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为【xigua】(注意命名不能用数字和特殊符号),点击【确定】。创建完成,勾选数据表,并点击右上角保存按钮。
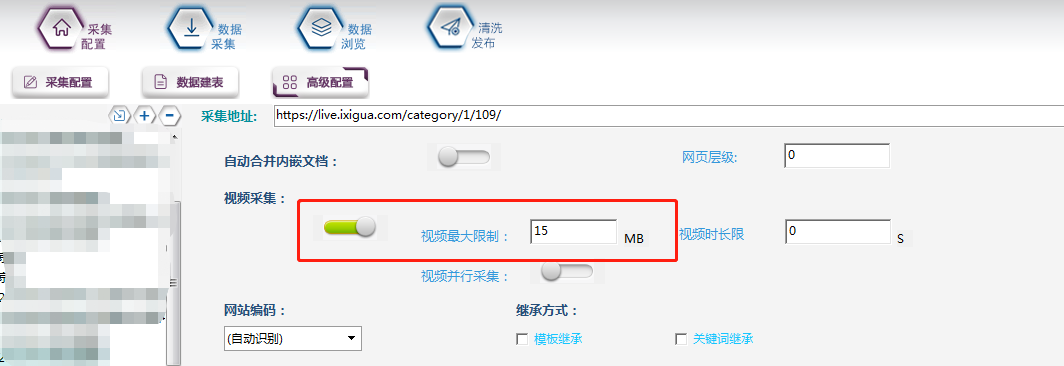
②高级设置,在高级配置中,设置采集视频的最大限制,如下图所示,这样爬虫采集15M就会停止采集,否则爬虫将一直采集一个直播视频直到直播结束。设置好后,点击右上角保存按钮。
③选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。
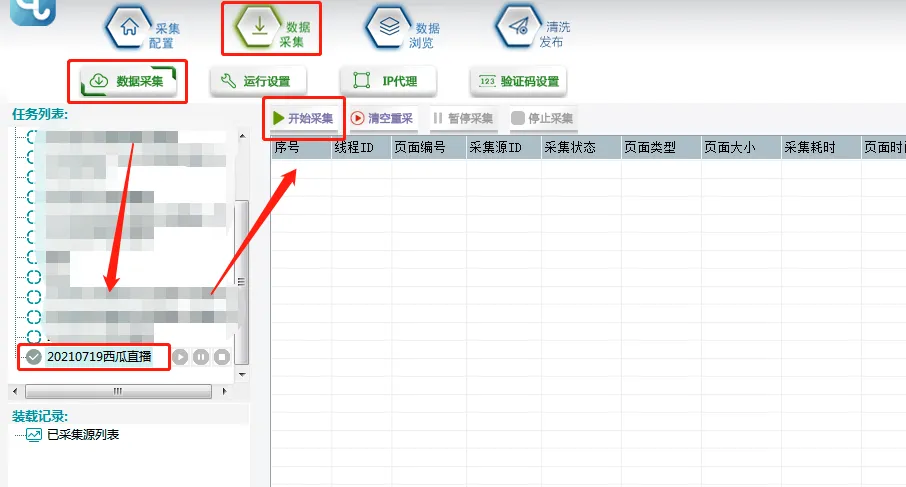
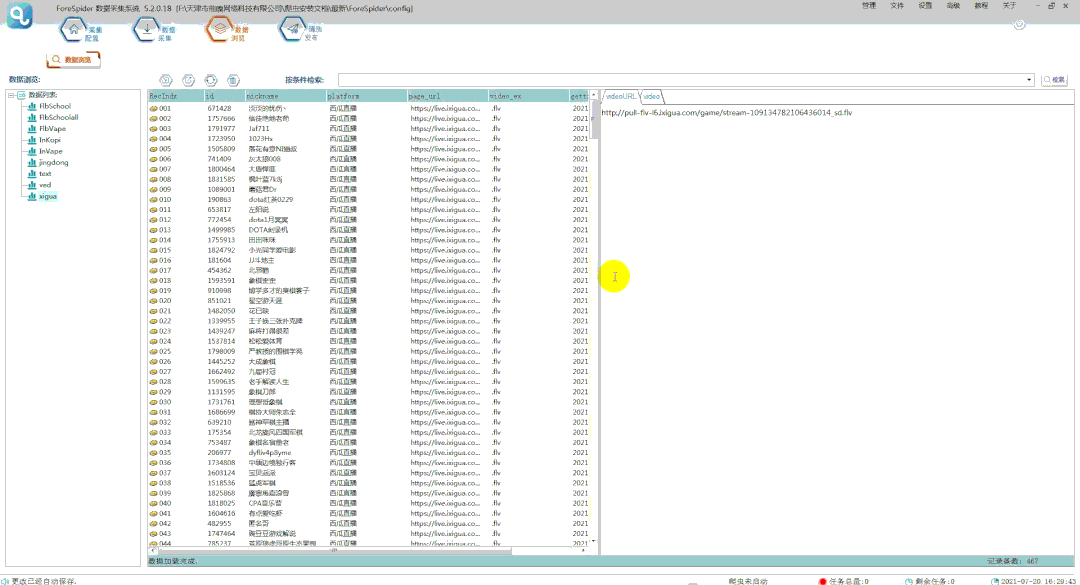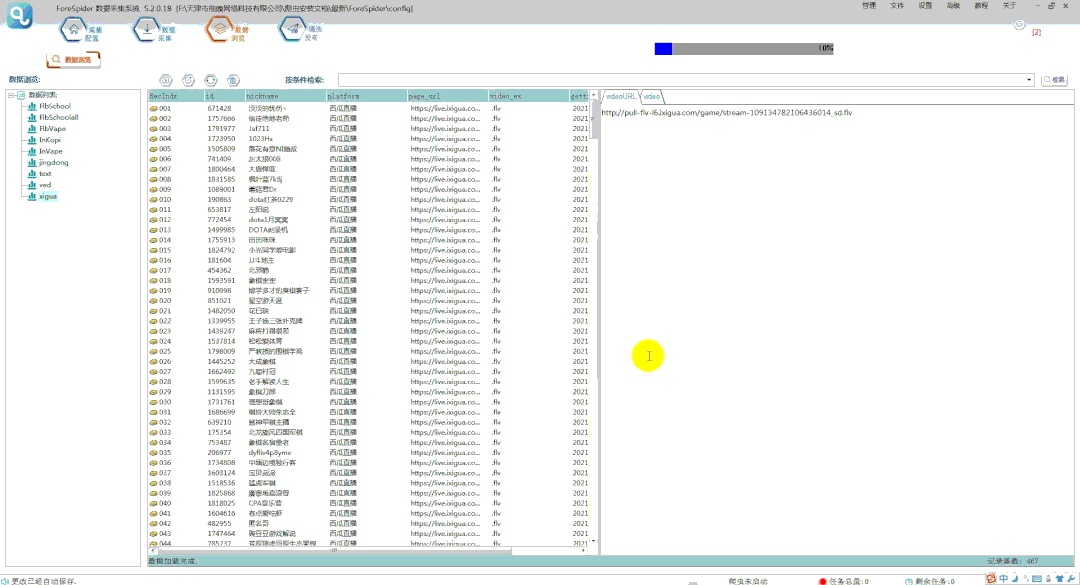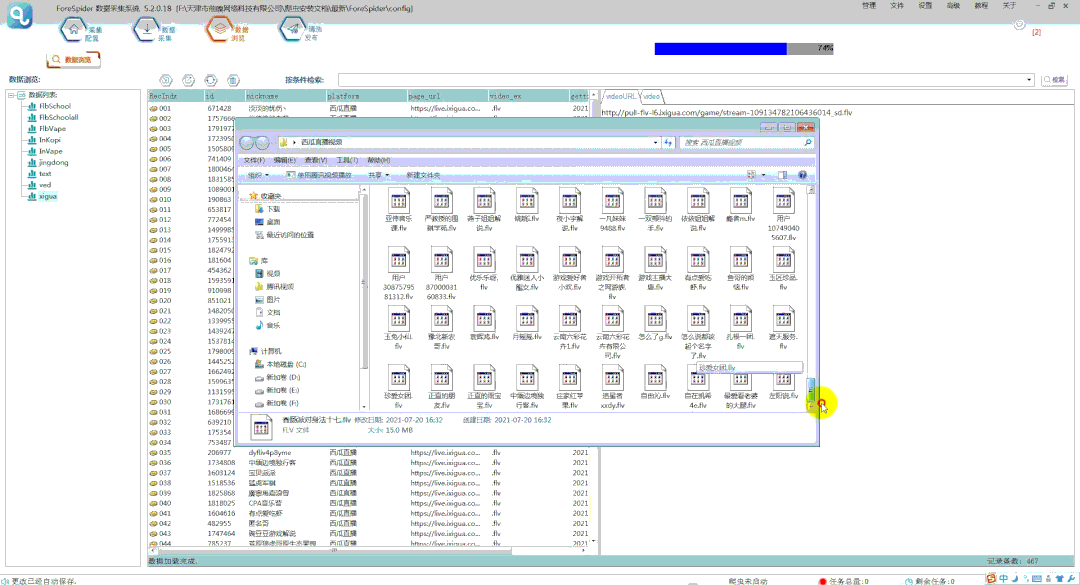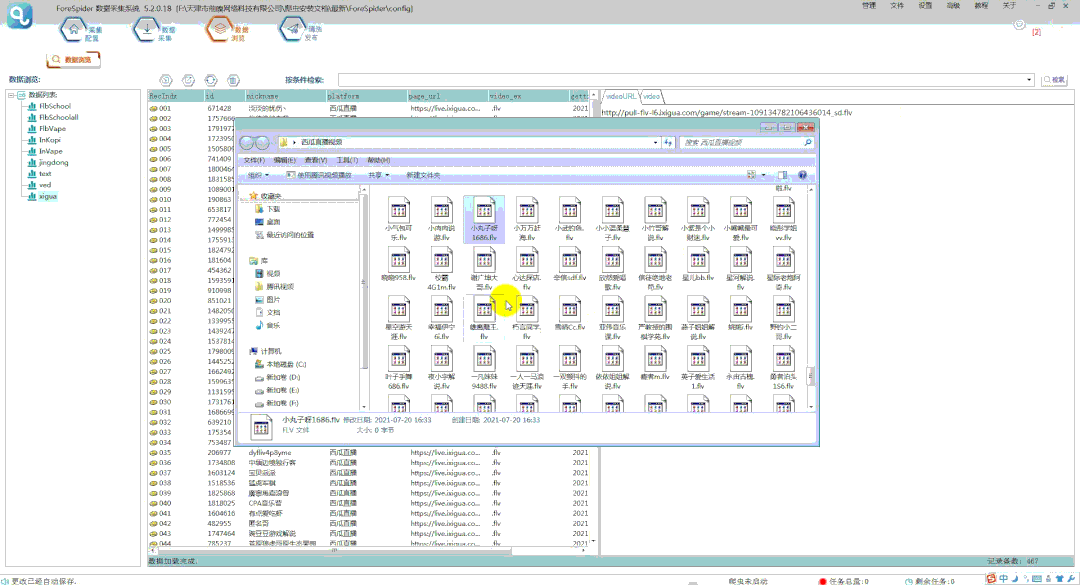
④可以在【数据浏览】中,选择数据表查看采集数据,并可以导出数据。
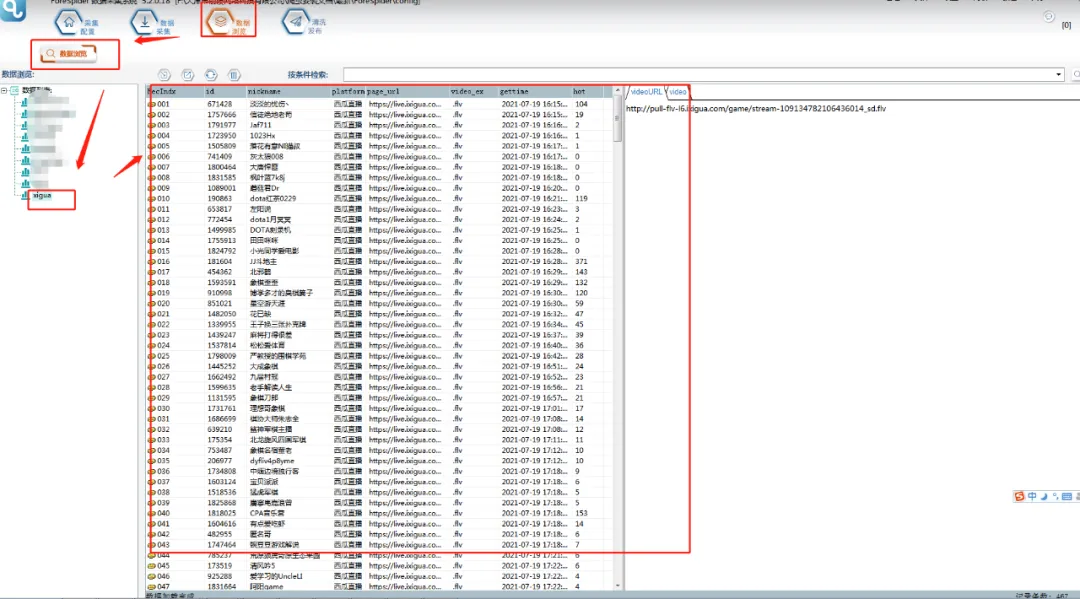
⑤导出的文件打开如下图所示:
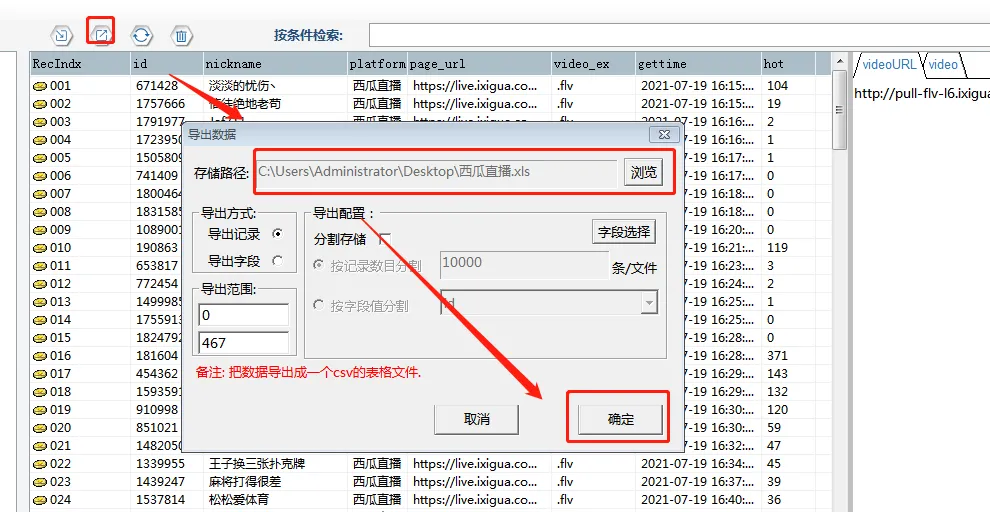
⑥导出视频步骤及结果如下图所示:
*本教程仅供学习交流,严禁用于商业用途!

.png) 大数据引擎
大数据引擎.png) 大数据应用
大数据应用.png) 大数据底层技术
大数据底层技术.png) ForeSpider软件
ForeSpider软件
.png) 采集服务
采集服务.png) 软件学习
软件学习.png) 智能分析
智能分析.png) 特征提取
特征提取.png) 智能计算
智能计算.png) 数据可视化
数据可视化.png) 数据分析应用
数据分析应用.png) 系统集成服务
系统集成服务.png) 代码工具
代码工具.png) 金融方案
金融方案.png) 制造业&物流
制造业&物流.png) 企业数字化
企业数字化.png) 医疗方案
医疗方案.png) 政务方案
政务方案.png) 实时监测
实时监测.png) 智能分析
智能分析.png) 数据智能挖掘
数据智能挖掘.png) 全网自动采集
全网自动采集.png) 场景智慧采集
场景智慧采集.png) 主题识别采集
主题识别采集







 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com









 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com 前嗅大数据
前嗅大数据