「深度学习福利」大神带你进阶工程师,立即查看>>>
在区块链的底层世界里,数据都是非结构化存储的,不支持结构化查询,在查询效率及便利化方面表现不足,所以区块链浏览器就这样应运而生了,通过区块链浏览器可以对区块链上的数据进行复杂化、条件化及个性化查询,同时对外提供了一些公共服务,例如查询区块、交易、地址及对合约事件进行监控或通知等。
本期技术工坊,梁雁明老师将带大家了解,什么是区块链浏览器,开发一款简单的区块浏览器的应用架构及在具体实践中的一些具体示例。
1
时间地点
**时间:**11月07日 18:30 - 21:00
地点 :(上海徐汇)上海市市辖区徐汇区龙华中路596号A308室
线下分享+交流 9.8元/人
参会人员要求:
1) 技术背景人员,对区块链开发有兴趣;
2) 活动限额15人,报满截止;
2
活动流程
18:30-19:30 签到,自我介绍
19:30-20:30 区块链浏览器应用实践
20:30-21:00 互动交流
3
分享主题及嘉宾
分享话题:区块链浏览器应用实践
分享大纲:
1、什么是区块链浏览器? 2、区块链浏览器的应用架构 3、区块链浏览器的具体实践
分享嘉宾:梁雁明
区块链兄弟的高级技术专家 离子链高级研发工程师 区块链Dapp应用开发专家 ,离子链区块链浏览器和钱包系统架构师。精通以太坊智能合约的开发和设计,擅长solidity编程语言,熟悉以太坊ERC系统协议规范,对以太坊ERC系列代币协议有深入的研究和探索。目前就职于上海旺链,从事自有底层公链的DAPP相关的架构设计和开发。
4
报名方式
识别下图二维码或点击“ 阅读原文 ”即可报名参加。
「深度学习福利」大神带你进阶工程师,立即查看>>>
NO.1前言
近几年,基于区块链技术和密码学的数字货币行业,迎来爆发式增长。作为数字货币产业链中最重要的环节之⼀,区块链资产交易所无疑拥有举⾜轻重的地位。 它连接着区块链投资的⼀⼆级市场,也连接着项目方和普通投资者。
据统计,目前被非小号平台收录的交易所已超过300家,未被收录的甚至有数千家之多。即便如此,入局者依然乐此不疲。在人人都来做交易所的背景下, 几乎每家交易所多达几十甚至上百个交易标的 ,那么存量有限的市场,中小型区块链资产和交易所将面临流量匮乏,无价无市的境地。
NO.2
为什么市商策略是刚需
市商机器人的出现改变了这一局面,通过在市场中参与做市,遏制因信息和资源不对称性,导致的市场过度投机行为,维护交易平台的良好运行。并减少传统交易方式中,所谓庄家暗中操纵价格的现象,来增强市场吸引力,提高流动性和成交量,满足普通投资者的买卖需求,稳定市场信心。
在今天,为了使新交易所和新币种更好的建立与普通投资者之间的连接,并解决其上市初期面临的诸多问题,不管是中小交易所还是区块链项目方,都不得不依靠市商机器人。
NO.3
市商策略原理
市商策略通过做市制度,跟踪价格变化,不断地提供买、卖的双向报价。通过高频大量的买入、卖出交易,逐渐积累每笔交易价格和理论价格的差价,并根据持仓头寸特征,动态调整价差。
一般交易所常见的市商策略有两种: 被动做市:市商策略跟踪主流交易所深度数据和成交数据,不做较大的主动选择,而是被动跟随市场,追求的就是最大程度的紧密跟踪和完全复制,试图达到和主流交易所同样的K线数据。
自由做市:这种做市模式不参考其他交易标的,而是根据自己的成本和设定挂单做市。这种模式适合相关币种定价权相对集中的环境,如:小型区块链资产或交易所自己发行的币种。
NO.4
市商策略漏洞
无论是被动做市,还是自由做市,不仅需要解决交易标的价格问题,还需要解决流动性问题。所以为了活跃市场,就需要市商策略可以自买自卖,否则很难形成像样的K线。
常见的方法是,在盘口附近随机指定一个价格卖出,立即同价格买入。或者根据随机价格,先买入后卖出。通常由于买卖间隔的时间很短,在深度数据中往往找不到相应挂单,但是在历史数据中却能留下成交记录,K线就是通过这种做市方法绘制而成的。
请注意!漏洞就是这样出现的。
市商策略为了产生连续的K线,在盘口附近自买自卖挂单,却隐藏了一个漏洞。 虽然策略的买单卖单是同时发出的,但是由于网络问题和撮合速度并不是理想状态,也不可能是理想状态,这就造成市商策略的订单,有一定几率被其他人成交。
设想一下,假如市场上存在另一个高频刷单策略,它总是以更低的价格成交市商策略的卖单,又以更高的价格成交市商策略的买单,只要这个高频刷单策略获得的差价,能覆盖手续费就会产生盈利。 这就造成市商策略低卖高买,细思极恐!
NO.5
实战演示
经过观察,某交易所的ETHUSDT交易对存在做市现象,参考对象可能是币安ETHUSDT数据,通过观察其盘口订单薄数据,发现存在自成交刷单,买卖方向随机,下图为当天该做市策略产生的K线。
通常高频刷单策略并不是在盘口随机定价,而是参考市商策略的上次成交价格随机变动的。这样实际上,成交价很难触及盘口低价和高价,再加上获取做市策略订单的成功率有限,几乎没有利润空间。
甚至还要承担单边持仓风险。这看似无懈可击,但是如果我们利用做市订单必须在盘口中挂单的Bug,即可轻易破解交易所的市商策略,并牟取暴利。
NO.6
具体步骤如下:
当期望低价成交时,就在买一价的基础上加一定的价格挂卖单。当买一价是200,就挂200.1的卖单,然后不停的挂200.09的买单,并立即撤销。当成交后,立即反向操作,将成交的币高价卖出,如此完成一个循环。
虽然这样的成功率并不多,但通过大量频繁挂撤单交易,使得捕捉到这种机会将大大增加,利润依然十分可观。
如上图所示,通过发明者量化交易平台(FMZ)写了一个高频刷单策略,实盘运行几乎没有回撤。 只用一个晚上的时间,就从1000USDT,刷到了4000USDT的利润。
这还是温和的刷,如果用上多账户、多合约、多线程会跟加暴利。高频刷单策略利用这个漏洞后,窃取的是巨额资金,留下的是糟粕的K线,如下图:
NO.7
基于交易所市商漏洞的刷单策略源码
以上策略源码基于发明者量化平台( www.fmz.com )
NO.8
防范的方法
针对这种做市策略,知道原理后解决起来就简单了, 如做市策略的自成交价格在低位时只先挂买单然后挂卖单,反之亦然,这样就不会被别人低买高卖。或者将所有的成交和挂单都放在可以在其它交易所对冲的范围内。
写在后面的话
尽管交易所身处整个区块链产业的顶端,但它就像一个置身在外的巨人,透露了更多的攻击面和可利用的漏洞点。
客观的说,能通过订单薄反推出来的不合理,都可能存在更隐蔽的Bug。就比如利用上文明显的交易所市商策略漏洞,攻击者可巧妙地设计出各种隐匿攻击策略,还能做到不知不觉。
如今,数字货币已成为投资新靶标,交易所也成为众多黑客的角斗场。 隐匿在暗处的黑客如饿狼一般,伺机而动,紧盯着交易所的破绽,准备一击致命 。区块链中心化交易所只能加强自身防御部署,让客户真正做到交易无忧。
阅读原文
「深度学习福利」大神带你进阶工程师,立即查看>>>
对于以太坊来说 2018 年是着力基础建设的一年( https://twitter.com/L4ventures/status/953041925241757697)。今年是初期用户来测试网络极限的一年,并将重新关注一些扩展以太坊的技术。
以太坊至今仍处于成长初期。 现今,它还不是安全的或者可扩展的( https://twitter.com/VladZamfir/status/838006311598030848)。技术人员能够很清楚的认识到这一点。但是在去年,大量 ICO 所导致的炒作已经开始夸大目前的网络能力。构建一个安全,易于使用的去中心化互联网,受约于一套通用经济规范并被无数人使用,以太坊和 web3 提出的这一美好承诺就在眼前,但只有在建立关键基础设施的前提下才能够实现( https://twitter.com/granthummer/status/957353619736559616)。
致力于构建这种基础架构和扩展以太坊性能的项目通常被称为 扩展方案(scaling solutions) 。这些项目有着不同的形式,并且通常相互兼容或互补。
在这篇长帖中,我想要深入讲解一种扩展方案:“off-chain” 或 “第二层(layer 2)” 方案。
首先,我们会全面的讨论下以太坊(以及所有公有的区块链)的扩展难题。
其次,我们将介绍解决扩展难题的不同方法,区分 “layer 1” 和 “layer 2” 解决方案。
最后,我们会深入了解第二层(layer 2)解决方案并详细解释它是怎样运作的,我们会谈及 状态通道(state channels)( https://medium.com/l4-media/generalized-state-channels-on-ethereum-de0357f5fb44),Plasma(http://plasma.io/) 和 Truebit( http://truebit.io/)。
本文的重点在于给读者全面而详细的讲解第二层(layer 2)解决方案的概念与工作原理。但我们不会深入研究代码或特定实现。相反,我们专注理解用于构建这些系统的经济机制以及所有第二层技术之间共同的思维模式。
1
公有区块链的扩展难题
首先,你要知道“扩展”不是一个单一的、特定的问题,它涉及了一系列难题,必须解决这些难题才能使以太坊对全球无数用户可用。
最常讨论的扩展难题是交易通量。目前,以太坊每秒可以处理大约 15 笔交易,而 Visa 的处理能力则大约在 45,000/tps。在去年,一些应用程序(比如 Cryptokitties: http://cryptokitties.co/ 或偶尔的 ICO)已经足够流行以至于“放缓了”网络速度并提升了挖矿费用(gas: https://myetherwallet.github.io/knowledge-base/gas/what-is-gas-ethereum.html) 的价格。
公有区块链(比如以太坊)最核心的缺陷是要求每一笔交易要被网络中的每一个节点处理。一笔支付,Cryptokitty 的诞生,部署新的 ERC20 合约,每一个以太坊区块链上发生的操作都必须由网络中的每个节点并行执行。这是设计理念所决定的,也正是由于这种设计理念才使得公有区块链具有权威性。节点不需要依赖其他节点来告诉他们当前区块链的当前状态,它们会自己计算出来。
这给以太坊的交易通量带来了根本性的限制:它不能超过我们对于单个节点的设计要求。。
我们可以要求每个节点做更多的工作,如果我们将块大小加倍(例如,区块 gas 限制),这意味着每个节点处理每个区块的工作量大致是之前的两倍。但是这样就减弱了系统的分散化理念:节点要做更多的工作意味着性能较差的计算机(比如用户设备)可能会从网络中退出,并且挖矿也会更向性能强大的节点运营者集中。
相反,我们需要一种方式使区块链做更多有用的事,但并不是增加单个节点的工作量。
从概念上来说,有两种可能解决这个问题的方法( https://blog.ethereum.org/2018/01/02/ethereum-scalability-research-development-subsidy-programs/):
1.1 如果每个节点不必并行处理每个操作,会怎样?
第一种方法是抛弃我们的前提,如果我们可以构建一个每个节点不必处理每个操作的区块链,会怎样?如果网络分为两个部分代替原有网络,每一个部分都可以独立运行,会怎样?
A 部分可以处理一批交易,而同时 B 部分可以处理另一批。这实际上会使区块链的交易通量翻倍。因为我们的限制现在能够被两个节点同时处理。如果我们可以将区块链分为许多不同的部分,那么我们可以将区块链的通量提高很多倍。
这是分片(sharding)的思维模式,也是 Vitalik 的以太坊研究小组(Ethereum Research group)( http://ethereumresearch.org/) 和其他社群正在研究的一种扩展方案。一个区块链被分割成叫做 shards 的不同部分,每一个部分都可以独立处理交易。因为分片是在以太坊的基础级协议中实现的,所以通常被也称为第一层(layer 1)扩展解决方案,如果你想了解更多有关分片的内容,请查看 extensive FAQ( https://github.com/ethereum/wiki/wiki/Sharding-FAQ) 和这篇博文( https://medium.com/@icebearhww/ethereum-sharding-and-finality-65248951f649)。
1.2 如果我们能够从以太坊现有能力中压榨出更多有用的业务操作
第二种选择的方向则相反:不是增加以太坊区块链本身的容量,如果我们可以通过我们已经拥有的能力来做更多的事情,会怎样?在基础级别以太坊区块链的生产力都是相同的,但是实际上,我们可以做更多对人和应用程序有用的操作,比如交易,游戏中的状态更新,或者简单的计算。
这是 “链下(off-chain)” 技术背后的思维逻辑,比如 状态通道(state channels),Plasma 和 Truebit。虽然其中每个解决方案都在解决一个不同的问题,它们都通过执行“链下”操作而且能够不在以太坊区块链上运行的同时,仍然保证足够的安全性和权威性。
这些也被称为 第二层(layer 2) 解决方案,因为它们建立在以太坊主链“之上”。他们不需要更改基本级别的协议,相反,它们只是作为作为以太坊上的智能合约,用于与链下软件进行交互。
2
第二层(layer 2)解决方案是加密经济解决方案
在深入了解第二层解决方案的细节之前,了解下使其可行的潜在细节是非常重要的。
公有区块链的动力源泉在于加密经济合约( https://hackernoon.com/making-sense-of-cryptoeconomics-5edea77e4e8d)。通过调整激励措施并用软件和加密措施保护激励,我们可以创建一个就内部状态达成一致的稳定计算机网络。这是中本聪的白皮书(https://bitcoin.org/bitcoin.pdf)的关键内容,现已应用于许多不同的公有区块链(包括比特币和以太坊)的设计中。
除了一些极端的情况下(比如 51% 攻击),加密经济合约给了我们一个稳固的核心 。我们知道链上(on-chain)操作(比如支付,智能合约)可以被看做是写入去执行。
第二层(layer 2)解决方案背后的关键是我们可以将这个稳固的内核用作锚点,一个可以附加其他经济机制的固定点。这种 第二层 经济机制可以扩展公有区块链的可用性。让我们脱离区块链进行交互操作,并且在需要的情况下仍能可靠地重归到核心链上。
这些构建在以太坊“之上”的层并不总是与链上操作具有相同的保障。但是,它们仍然具备足够的权威性,安全性以及可用性,特别是在终端略微减少时,我们能够更快的执行操作或维持更低的日常成本。
加密经济并不是随着中本聪的白皮书而开始或结束,它是最适合我们去学习与应用的技术主体。不仅存在于核心协议的设计中,也存在于第二层系统的设计中,它们扩展了底层区块链的功能性。
2.1 状态通道(State channels)
状态通道(State Channel)是一种用于执行交易和其他状态更新的“off-chain”技术。可是,一个状态通道“中”发生的事务仍保持了很高的安全性和权威性。如果出现任何问题,我们仍然可以选择重归到“稳固内核”上,它的权威性是建立在链上交易基础上。
大部分读者会熟悉存在多年的概念——支付通道(payment channel),它最近通过在比特币上借助闪电网络(lightning network)( http://lightning.network/)实现了。状态通道是支付通道泛化出来的形式,它不仅可用于支付,还可用于区块链上任意的“状态更新”,比如智能合约中的更改。在 2015 年,Jeff Coleman 第一次详细介绍了状态通道( http://www.jeffcoleman.ca/state-channels/)。
解释状态通道的运作方式的最佳方法就是来看一个样例。请记住这是一个概念性的解释,也就是说我们不会牵涉到具体实现的技术细节。
现在试想一下,爱丽丝和鲍勃想玩一场井字游戏,赢家可以获得一个以太币。实现这一目的的最简单方法就是在以太坊上创建一个智能合约,实现井字游戏规则并跟踪每个玩家的动作。每次玩家想要移动时,他们都会向合约发送一个交易。当一名玩家获胜时,根据规则,合约会付给赢家一个以太币。
这样是可行的,但是效率低下且速度慢。爱丽丝和鲍勃正在使用整个以太网络处理他们的游戏过程,这对于他们的需求来说有点不合时宜。他们每一步都需要支付挖矿费用(gas),并且还要在进行游戏的下一步之前都要等待挖矿完成。
不过,我们可以设计一个新的系统,它能使爱丽丝和鲍勃在井字游戏的过程中产生尽可能少的链上操作。 爱丽丝和鲍勃能够以链下的方式更新游戏状态,同时在需要时仍能将其重归到以太坊主链上。我们将这样一个系统称之为“状态通道”。
首先,我们在以太坊主链上创建一个能够理解井字游戏规则的智能合约 “Judge”,同时它也能够认定爱丽丝和鲍勃是我们游戏中的两位玩家。该合约持有一个以太的奖励。
然后,爱丽丝和鲍勃开始玩游戏。爱丽丝创建并签署一个交易,它描述了她游戏的第一步,然后将其发送给鲍勃,鲍勃也签署了它,再将签名后的版本发回并保留一份副本。然后鲍勃也创建并签署一个描述他游戏中第一步的交易,并发送给爱丽丝,她也会签署它,再将其返回,并保留一份副本,他们每一次都会这样互相更新游戏的当前状态。每一笔交易都包含一个“随机数”,这样我们就可以直接知道游戏中走棋的顺序。
到目前为止,还没有发生任何链上的操作。爱丽丝和鲍勃只是通过互联网向彼此发送交易,但没有任何事情涉及到区块链。但是,所有交易都可以发送给 Judge 合约,也就是说,它们是有效的以太坊交易。你可以把这看做两人在彼此来回填写了一系列经过区块链认证的支票。实际上,并没有钱从银行中存入或取出,但是他俩都有一堆可以随时存入的支票。
当爱丽丝和鲍勃结束游戏时(可能是因为爱丽丝赢了),他们可以通过向 Judge 合约提交最终状态(比如,交易列表)来关闭该通道,这样就只用付一次交易费用。Judge 会确定双方都签署了这个“最终状态”,并等待一段时间来确保没人会对结果提出合理质疑,然后向爱丽丝支付一个以太币的奖励。
为什么我们需要设置一个让 Judge 合约等待一下的"质疑时间"
假设,鲍勃并没有给 Judge 发送一份真实的最终状态,而是发送一份之前他赢了爱丽丝的状态。这时如果 Judge 是一个非智能合约,它自己根本无法得知这个状态是否是最近的状态。
而质疑时间给了爱丽丝一个机会能够证明鲍勃提交了虚假的游戏最终状态。如果有更近期的状态,她就会有一份已签名交易的副本,并可以将其提供给 Judge。Judge 可以通过检查随机数来判断爱丽丝的版本是否更新,然后鲍勃盗取胜利的企图就能被驳回了。
特性和限制
状态通道在许多应用中都很有用,它们对于在链上执行操作是一种严密的改进。但在决定应用程序是否适合被通道化时,请特别注意需要做出的一些特定折中:
状态通道依赖于可靠性。如果爱丽丝在质疑时间内掉线了(也许是鲍勃不顾一切地想要赢下奖品,而破坏了她家的互联网连接),她可能无法在质疑时间内做出回应。但是,爱丽丝可以付款给其他人,让其保存一份她的状态副本,并作为她的权益代表,以保持系统的可靠性。
状态通道在需要长期交换大量状态更新的情况下非常有用。这是因为部署 Judge 合约时创建一个通道会产生初始成本。但是一旦部署完成,该通道内每一个状态更新的成本都会很低
状态通道最适于有一组明确参与者的应用程序。这是因为 Judge 合约必须始终知晓所有参与到给定通道的实体(比如,地址)。我们可以增加或删除用户,但是每次都需要更改合约。
状态通道有很强的隐私属性。因为一切都发生在参与者之间的通道“内”,而不是公共广播并记录在链上。只有开启和关闭交易必须公开。
状态通道的权威性是即时生效的。这意味着只要双方签署了一个状态更新,它可以被认为是最终状态。双方都有明确保证,在必要的情况下,他们可以将状态“执行”到链上。
我们 L4 团队正致力于创建 Counterfactual( https://counterfactual.com/),它是一个能在以太坊上推行使用状态通道的框架。我们的目标是使开发者可以在他们的项目中模块化地使用状态通道,而不需要成为状态通道专家。你可以通过这里(https://medium.com/l4-media/generalized-state-channels-on-ethereum-de0357f5fb44)了解更多该项目的信息。我们将在 2018 年的第一季度发布技术细节文件。
另一个值得注意的针对以太坊的状态通道项目是 Raiden( https://raiden.network/),目前正主要致力于构建支付通道网络,它使用了和 闪电网络类似的范式。这意味着你不必与想要交易的特定人员搭建通道。你可以与一个连接到更大型通道网络的实体架设一个单独的通道,这样你就能够向连接到同一网络的任何人付款而无需额外费用。
除了 Counterfactual 和 Raiden,在以太坊上还有几个应用程序特定的通道实现。例如,Funfair ( https://funfair.io/state-channels-in-disguise/)就为他们的去中心化赌博平台搭建了一套他们称之为 “Fate channels” 的状态通道,SpainChain 为成人项目演员构建了一套 one-way payment channels( https://twitter.com/SpankChain/status/932801441793585152)(他们还在他们的 ICO 中使用了状态通道: https://github.com/SpankChain/old-sc_auction),还有 Horizon Games( https://horizongames.co/) 也在他们的第一款基于以太坊的游戏中使用了状态通道。
2.2 Plasma
2017 年 8 月 11 日,Vitalik Buterin 和 Joseph Poon 发表了一篇题为 Plasma: Autonomous Smart Contracts的文档( http://plasma.io/plasma.pdf)。这份文档介绍了一种新技术,它能使以太坊每秒可以处理的远比现在更多的事务。
和状态通道一样,Plasma 是一种用于管理链下交易的技术,同时依靠底层的以太坊区块链来实现其安全性。但是 Plasma 采用了一种新思路,它是通过创建依附于“主”以太坊区块链的“子”区块链。这些子链又可以循序产生它们自己的子链,并能依次循环往复。
其结果是我们可以在子链层级中执行许多复杂的操作,在与以太坊主链保持最低限度交互的情况下,运行拥有数千名用户的完整应用程序。Plasma 子链可以更快迁移,并承担更低的交易费用,因为其上的操作无需在整个以太坊区块链上进行重复。
plasma.io/plasma.pdf
为了弄清楚 Plasma 的运行原理,我们来看一个其如何被运用的样例。
试想你正在创建一个基于以太坊的卡牌交换游戏。这些卡牌是一些 ERC 721 不可替代的令牌(比如 Cryptokitties),但是拥有一些可以让玩家相互对战的特征和属性,这有点像炉石传说或者万智牌。这些类型的复杂操作在链上执行代价非常大,所以你决定在你的应用程序中使用 Plasma 作为替代方案。
首先,我们在以太坊主链上创建一系列的智能合约,它们可作为 Plasma 子链的“根节点”。Plasma 根节点包含了子链的一些基本“状态交易规则”(诸如“交易无法消费已消费过的资产”),也记录了子链状态的哈希值,并建立一种允许用户在以太坊主链和子链间转移资产的“桥接”服务。
然后,创建我们的子链。子链可以拥有自己的共识算法,在这个例子中,我们假设它使用了 Proof of Authority (PoA)( https://en.wikipedia.org/wiki/Proof-of-authority),这是一种依赖可信区块生产者(比如,验证者)的简单共识机制。在“工作量证明”系统中,区块生产者和矿工的功能类似,它们接收交易,形成区块并收取交易费用的节点。为了让样例简单点,我们假设你(也就是创建游戏的公司)是创建区块的唯一实体,即你的公司运营几个节点,这些节点就是子链的区块生产者。
一旦子链创建好并生效后,区块生产者会周期性的向根节点合约发出提交。也就是他们实际上在说“我提交的 X 是子链中当前最新的区块”。这些提交被当做子链中事务的证明,记录在链上的 Plasma 根节点里。
现在子链也准备好了,我们可以创建卡牌交换游戏的基本组件。这些卡片遵循 ERC721,在以太坊主链上初始化,然后由 Plasma 根节点转移到子链上。这里引入了一个关键点:Plasma 可以扩展我们与基于区块链的数字资产之间的交互,但是这些资产应当是首先由以太坊主链创建的。然后,我们将实际的游戏应用程序以智能合约的方式部署到子链上,这样子链就包含了游戏所有的逻辑和规则。
当用户想要玩游戏时,他们只需要和子链进行交互。他们可以持有财产(ERC721 卡牌),为了以太币购买并交换它们,与其他用户对战,以及其他游戏中允许的行为,而这些过程都不需要与主链进行交互。因为只有很少的节点(比如,区块生产者)才需要处理交易,这样费用就会降低很多,操作也能更快。
3
但是这种模式安全吗?
通过将操作从主链迁移到子链上的方式,我们明显可以执行更多的操作了。但是这样安全吗?发生在子链上的交易是否具备权威性?毕竟,我们方才描述的系统只有一个中心实体控制着子链的区块生产。这样不是中心化吗?这样公司不是随时都能窃取你的资产或者拿走你的收藏卡牌吗?
简单来说,即使是在子链中完全由一个实体完全控制区块生产的情景下,Plasma 也能做出你可以随时将你的资产收回到主链上的基本承诺。如果一个区块生产者开始表现出敌意,最坏的情况也只是强迫你离开这个子链。
让我们来看下区块生产者表现恶劣的几种方式,同时看下 Plasma 会怎样处理这些情景。
首先,假设一个区块生产者试图通过说谎欺骗你,他们可以通过创建一个伪造的新区块,声称你的资产被他们接管了。由于他们是唯一的区块生产者,所以他们可以自由引入一个并不遵循区块链规则的新区块。和其他区块一样,他们也得将这个区块存在的证据作为提交推送给 Plasma 根节点合约。
如上所述,用户有能将他们的资产随时收回到主链上的基本保障。在这个情景下,用户(或者代表他们权益的应用程序)会侦测到这种盗窃的企图,并在区块生产者尝试和使用他们的“被盗”资产之前撤回到主链上。
Plasma 还创建了一种防止利用欺诈的机制。Plasma 包含了一种任何人(包括你)都可以向根节点合约发布欺诈证明(fraud proof)的机制,这样就可以证明区块生产者作弊了。这个欺诈证明会包含之前区块的信息,并且允许我们根据子链中的状态交易规则,错误的区块并不能正确接上之前的状态。如果欺诈被证实,则子链回滚到前一个区块。更妙的是,我们还构建了一种签出错误区块的区块生产者会被处罚的体系,这些区块生产者会因此丢失一个链上押金。
plasma.io/plasma.pdf
但是提交欺诈证明需要访问底层数据,即需要用之前的实际历史区块来证明欺诈。如果区块生产者为了防止爱丽丝能够向根节点合约提交欺诈证明,并不分享之前区块的信息怎么办?
在这种情况下,这个方案就是为了让爱丽丝收回资产并脱离子链而准备的。根本上来说,爱丽丝向根节点合约提交了一份“欺诈证明”。在一段任何人都可以质疑证明(比如,显示一些后面的合法区块证明实际上她消费了这些资产)的延迟时段后,爱丽丝的资产将会被移回到以太坊主链上。
plasma.io/plasma.pdf
最后,区块生产者可以监察子链中的用户。如果区块生成者愿意,他们可以直接不在其区块中不包含实际事务,从而有效阻止用户在子链上执行任何操作。如上所述,这个解决方案再一次的直接将我们所有的资产收回到以太坊主链上。
但是,取出资产本身也会带来风险。其中一个忧虑就是如果所有使用这一子链的用户在同一时刻都要取出资产会怎样。在这样一个大量取出的情况下,以太坊主链主链上可能没有足够的能力处理每个人在质疑期内的交易,也就意味着用户可能会失去资金( https://www.reddit.com/r/ethereum/comments/6sqca5/plasma_scalable_autonomous_smart_contracts/dlex5pa/?utm_content=permalink&utm_medium=front&utm_source=reddit&utm_name=ethereum)。虽然有许多可行的技术能够防止这种情况发生,例如,通过延长质疑时间来适应取出资产的需求。
值得注意的是,所有区块生产者都是由一个实体控制这种情况并不是必定的,这只是我们案例中的极端个例。我们可以创建创建区块生产者分布在不同实体间的子链,即像公有区块一样真正地去中心化。在这些情况下,区块链生产者按照上述方式交互的风险更小,而且用户必须将资产转移回以太坊主链的风险也更小。
现在我们已经介绍了状态通道和 Plasma,有几点值得比较下。
它们之间一个不同之处在于,当状态通道中所有利益方都一致同意提现,它可以立即提现。如果爱丽丝和鲍勃同意关闭通道并撤回它们的资金。只要他们都认同最终状态,他们就可以立即取得他们的资产。这在 Plasma 上并不可能实现,如上所述,用户在取出资产的过程中必须包含一个质疑时间。
与 Plasma 相比,状态通道在每笔交易上更便宜,而且速度更快。这意味着我们可以在 Plasma 子链上建立状态通道( https://www.reddit.com/r/ethereum/comments/7jzx51/scaling_ethereum_hundreds_to_thousands_of/drb930m/?context=1)。例如,一个应用程序中两个用户在进行一系列的小型交易。在子链上建立一个状态通道应该会比直接在子链上执行每个交易更加便宜和迅速。
最后,需要注意的是这部分讲解缺失了大量细节。Plasma 本身还处于非常起始的阶段。如果你有兴趣了解 Plasma 现在的情况,请查看 Vitalik 最近的一个关于 “Minimal Viable plasma”( https://ethresear.ch/t/minimal-viable-plasma/426) 的提议(即抽离出 plasma 的实现过程)。一个台湾的团队正在进行这项工作,可以在这个分支( https://github.com/ethereum-plasma)中查看。OmiseGo 正在研究他们的分布式交易的实现,他们在这里( https://blog.omisego.network/construction-of-a-plasma-chain-0x1-614f6ebd1612)发布了最近更新进展信息。
III. Truebit
Truebit( https://truebit.io/) 是一种帮助以太坊在链下进行繁重或者复杂 运算的技术。它对于提高以太坊区块链的总交易通量更有效,这使得它与状态通道和 Plasma 不一样。正如我们在开篇部分讨论的那样,扩展是一个多方面的难题,需要的不仅仅是更高的交易通量。Truebit 不会让我们做更多的交易,但是它可以让基于以太坊的应用程序处理更复杂的事务并仍能被主链验证。
这就让我们能够对以太坊应用程序做一些有用的操作,这些操作的计算成本太高,无法在链上执行。例如,验证来自其他区块链的简单支付验证(SPV)证明,以太坊智能合约可以通过这个验证“检查”交易是否发生在另一个链上(比如比特币或者狗币: https://twitter.com/Truebitprotocol/status/960662648193888256)。
我们来看一个例子。试想你有一些高代价计算(比如 SPV 证明)需要作为一个以太坊应用程序的一部分执行。因为 SPV 证明的计算成本太高了,你不能简单地将其作为以太坊主链上的智能合约的一部分。请牢记,因为每个节点必须并行执行该操作,所以在以太坊上执行任何计算的成本都非常高。以太坊中的区块都有最大费用(gas)限制,它用于限制该区块中所有事务组合在一起能够完成的计算总量。但是,SPV 证明的计算量实在太大,即使它只是其中仅有的交易,仍需要许多倍单个区块的全部费用限制。
相反,链下你只需要支付很少的费用就可以完成计算。让你为此付费完成计算的这个人被称作解算机。
首先,解算机支付给智能合约一份押金。然后,你给解算机一份计算的详细描述,它们运行计算,并返回结果。如果结果是正确的(大部分情况下发生在一秒钟之内),它们的押金将被退回。如果解算机被证实没有正确执行运算(比如,它们欺诈或者犯错了),它们会失去押金。
但是,我们如何判断结果是否正确呢?Truebit 使用了一种叫做“验证游戏(verification game)”的经济机制。本质上我们创建了一种激励机制,它叫做挑战者(challengers)来检查解算机的结果。如果挑战者能够通过验证游戏证明解算计提交了错误结果,那么他们就可以收取奖励,而解算计则丢失他们的押金。
由于验证游戏是在链上执行的,因此它不能简单地计算结果(这会推翻整个系统的设计初衷,如果可以在链上执行计算,我们也就不需要 Truebit 了)。相反,我们要求解算机和挑战者确定他们意见不一致的特定操作。实际上,我们支持双方到一个角落,找出导致它们对结果不一致的具体代码行。
Truebit 的简化概念图。
一旦确定了具体的操作,它就小到可以由以太坊主链来执行了。然后,我们通过以太坊智能合约来执行这一行动,该合约一劳永逸地解决了哪一方说了真话,哪些又是谎言或错误。
如果你想了解更多关于 Truebit 的信息,你可以查看这份文档( https://people.cs.uchicago.edu/~teutsch/papers/truebit.pdf),或者 Simon de la Rouviere 写的这篇博文( https://medium.com/@simondlr/an-intro-to-truebit-a-scalable-decentralized-computational-court-1475531400c3)。
4
总结
第二层解决方案有着共同的远见。一旦我们得到由公有区块链提供的稳定内核,就可以将其作为加密经济的锚点,扩展出无限的区块链应用。
现在我们已经对一些样例进行了调查,这样就可以更具体地了解第二层解决方案怎么实现这种远见。第二层解决方案中运用的经济机制通常是交互游戏:它们通过为各方创造激励以使其相互竞争或彼此“检查”工作。由于我们激发了另一方出示证实错误信息的强烈动机,因此区块链应用程序可以假定某个给定的声明是正确的。
在状态通道方案中,就是通过给各方一个“反驳”对方的机会,来确定通道的最终状态。在 Plasma 方案中,就是如何管理欺诈证明和提现。在 Truebit 方案中,就是通过激励挑战者证明解算机是错误的,从而保证解算机给出正确结果。
这些系统将有助于解决将以太坊扩展到全球用户群过程中所涉及的一系列挑战。一些系统,像状态通道和 Plasma ,将会增加平台的交易通量。其他系统,像 Truebit,将能够作为智能合约的一部分进行更多的复杂计算,创建出新的使用案例。
这三个例子只能代表加密经济扩展方案可能性设计的一小部分。我们甚至还没有谈到像 Cosmos( https://cosmos.network/) 或 Polkadot ( https://blog.stephantual.com/web-three-revisited-part-two-introduction-to-polkadot-what-it-is-what-it-aint-657782051d34)这样的“区块链间协议”(尽管这是“第二层”解决方案或另一篇博文的内容)。我们还是应该期待能够发明出意想不到的新型第二层系统,来改进现有模型或在速度,终端和开销做出新的权衡。
比任何独特的第二层解决方案更重要的是进一步发展潜在的技术和机制,使这些加密经济设计成为可能。
这些第二层扩展方案有力证明了像以太坊这样的可编程区块链的长期价值。只有在程序化区块链上才有可能建立基于第二层解决方案的经济机制:你需要用脚本语言实现执行交互式游戏的程序。因为比特币等区块链只提供了有限的脚本功能,这对于它们来说很困难(或者有些情况下,比如 Plasma,这是完全不可能实现的)。
以太坊第二层方案的出现让我们能在速度、终端和开销间做出新的权衡。这是底层区块链能够适用于更多种类的应用程序。因此面对不同威胁模型的不同类型应用程序会自然的选择不同的权衡模式。对于需要保障区域性(乃至国家性的)范围内的大规模交易时,我们使用主链。对于更偏重速度的数字资产交易,我们可以使用 Plasma。第二层方案让我们能够在不损害底层区块链的前提下做出这些折中措施,并保持去中心化和权威性。
而且,很难事先预测给定的扩展方案需要哪些脚本功能。当以太坊被设计出来时, Plasma 和 Truebit 还尚未发明。但是由于以太坊是完全可编程的,它能够实现我们能发明的任何经济机制。
区块链技术的价值是建立在加密经济合约的稳定内核上,而诸如以太坊这样可编程区块链才是能够充分利用这种价值的唯一途径。
感谢 Vitalik Buterin,Jon Choi,Matt Condon,Chris Dixon,Hudson Jameson,Denis Nazarov 和 Jesse Walden 对于本文初稿的意见。 原文地址:Making Sense of Ethereum’s Layer 2 Scaling Solutions: State Channels, Plasma, and Truebit 原文作者:Josh Stark 译文出自:掘金翻译计划 本文永久链接:github.com/xitu/gold-m… 译者:JohnJiangLA 校对者:foxxnuaa Zheaoli 版权属于原作者。
「深度学习福利」大神带你进阶工程师,立即查看>>>
这一系列文章将围绕以太坊的二层扩容框架,介绍其基本运行原理,具体操作细节,安全性讨论以及未来研究方向等。本篇文章主要介绍 Plasma 的一个最小实现 Plasma MVP(Minima Viable Plasma)。
在 上一篇文章中 我们已经理解了 Plasma 中的一些关键操作,但是 Plasma 是一套框架,如果脱离了实际的应用,仍然很难彻底理解它。因此本篇将详细介绍 Plama 的第一个项目 Plasma MVP(Minimal Viable Plasma),即在 Plasma 框架下的最基础的实现。Plasma MVP 是 Vitalic 和他的团队在 2018 年初提出的基于 UTXO 模型实现的 Plasma 设计标准[1],它以最简单的方式实现了链下交易,但无法支持复杂的计算,例如脚本(Script)和智能合约。在阅读下面的内容之前,请确保已经理解了这个系列之前的文章。
深入理解Plasma(1):Plasma 框架
深入理解Plasma(2):Plasma 细节剖析
整个 Plasma MVP 的生命周期可以通过下面这幅图表现出来:
1
Plasma 合约
首先需要将 Plasma 合约部署到主链(以太坊)上作为主链和子链沟通的媒介。Plasma 合约会处理由子链提交的区块,并且将区块的哈希值存在主链上。除此之外,还会处理用户的存款(deposit)、取款(withdrawal/exit)以及争议(challenge)操作。
Plasma 合约中主要包括的数据结构有: Owner:合约的拥有者(即部署合约交易的发送者)的地址,即部署合约交易的发送者; Plasma 区块列表:每个 Plasma 区块中存储了(1)区块的 Merkle root(2)区块提交的时间; 退出列表:即提交了退出申请的列表,每个退出申请存储了(1)申请者的地址(2)申请退出的 UTXO 的位置。
Plasma 合约中主要包括的函数有: submitBlock(bytes32 root):向主链提交一个区块,仅仅提交区块中所有交易的 Merkle root; deposit():生成一个只包含一个交易的区块,这个交易中包含与 msg.value 值相等的 UTXO; startExit():执行给定 UTXO 的退出操作; challengeExit():向某个正在执行的退出提出争议。
2
Operator
在前面的文章中我们已经知道 Plasma 子链是一个独立的区块链,那么也就有独立的共识机制。在 Plasma MVP 中采用的共识机制就是 PoA(Proof of Authority),即参与共识的只有唯一一个矿工,称为 Operator。Operator 负责处理所有子链上发生的交易,将其打包成区块存储在子链上,并且周期性地向 Plasma 合约提交区块,将子链上的状态(区块的哈希值)提交到主链共识。那么,既然 Operator 是唯一的矿工,这不就意味着 Plasma 违背了去中心化的初衷了吗?其实,这是去中心化向执行效率的妥协。在之前的文章中也提到过,Plasma 的安全基础依赖于底层的区块链,只要底层的区块链能够保证安全,那么在 Plasma 子链上发生的最差结果也只是迫使用户退出子链,而不会造成资产损失。
Operator 可以采用最简单的 REST API 方式实现,子链中的用户可以通过调用简单的 API 获取到子链中区块的数据。
3
存款(Deposit)
用户 Alice 通过存款(deposit)操作向 Plasma 合约发送带有一定数额的以太币或 ERC20 token 加入 Plasma Chain,这时 Plasma 合约会执行 deposit() 函数,生成一个只包含一个交易的区块,这个交易的 UTXO 记录了 Alice 从主链转移到子链的数额。当这个区块被主链确认后,Alice 就可以使用新生成的 UTXO 向其它用户发送交易了。
4
交易(transaction)
在 Plasma MVP 中,所有用户发送的交易都是直接发送给 Operator,当积累了一定数量的交易后,由 Operator 将交易打包成区块。这里需要注意的是,由于 Plasma MVP 采用的是 UTXO 模型,所以即使交易的收款方不存在,交易也是成立的。
在子链上 Alice 向 Bob 发送一个交易的流程如下: Alice 首先需要得到 Bob 在子链上的地址; Alice 将一个或多个 UTXO 作为输入构造交易发送到 Bob 的地址,并对交易签名; 等待该交易被打包到区块中; Alice 向 Bob 发送确认消息,并且使用相同的私钥签名。
5
生成区块
在 Plasma MVP 中,一个 Plasma 区块产生的情况只有两种:一种是 Operator 打包生成区块,另外一种是当用户执行 deposit 操作时,由 Plasma 合约直接生成一个只包含一个交易的区块。
6
监视子链
为了保证子链上资产的安全,用户需要周期性地检查子链上的数据,保证没有恶意交易产生。用户需要运行一种自动化的软件(例如钱包),每隔一段时间下载子链中的区块数据,检查每个区块中的交易,如果有恶意交易产生,立即退出子链。
7
取款/退出(withdrawal/exit)
当 Alice 想要退出子链时,需要向 Plasma 合约发送一个 exit 交易,申请中需要包含(1)所要退出的 UTXO 的位置,包括区块号(blknum)、区块内交易号(txindex)以及交易内输出号(outindex)(2)包含该 UTXO 的交易(3)该交易的 Merkle proof(4)用于生成该 UTXO 所涉及的之前一系列交易的确认签名。除此之外,exit 交易中还要包含“退出押金(exit bond)”。如果这个 exit 被 challenge 成功,那么取款的操作将被取消,而且退出押金将被发送给提出 challenge 的用户。
之后这个申请会被放入一个优先队列中,通过这个公式计算优先级: Priority = blknum * 1000000000 + txindex * 10000 + oindex
之所以采用这种优先队列的方式处理取款顺序的原因是保证旧的 UTXO 总能优先于新的 UTXO 被取出。也就是说,当有恶意交易(例如双花等)产生时,所有在恶意交易发生之前的交易都可以被优先取出。那么如何解决在恶意交易之后被确认的交易的取款问题呢?Plasma MVP 采用了“确认签名(Confirmation Signatures)”的机制,在下一小节我们将介绍这一机制是如何工作的。
8
确认签名(Confirmation Signatures)
在 Plasma MVP 中,用户的退出顺序以所要退出的 UTXO 所在的交易的位置为准。假如 operator 作恶,在一个合法的交易之前插入一个非法的交易,那么当用户执行取款时,由于非法交易可以先被取出,因此当执行到该用户的交易时,可能 Plasma 合约中的资产已经被取空。为了解决这个问题,Plasma MVP 采用了“确认签名”机制,例如当 Alice 产生一个交易时,她首先会对交易签名。当该交易被打包入区块后,Alice 还需要对该交易进行一次签名,即“确认签名”。
引入确认签名机制后,当 Alice 发现在一个区块中自己的合法交易之前存在非法交易时,可以拒绝对自己的交易进行“确认签名”,同时申请取款。这样可以使得当前的交易失效,保证自己之前“确认签名”后的交易可以优先于非法交易之前取出。
这种确认签名机制极大地破坏了用户体验,用户每产生一个交易都要经历签名->等待确认->确认签名。而且由于确认签名也需要占据 Plasma 区块的空间,因此也降低了子链的可扩展性。为了解决这个问题,Plasma 的研究人员提出了扩展版本 More Viable Plasma 移除了确认签名的要求[2]。
9
争议(Challenge)
每个取款操作都会经历一个争议期。例如在 Alice 的某个 UTXO 退出子链的过程中,如果 Bob 在争议期内发现有恶意行为发生,他可以提出一个争议(challenge)。一个争议需要给出针对的 UTXO 的位置,以及该 UTXO 被花费的证明,即该 UTXO 已经存在于某个交易中,且这个交易已经被打包到区块。
合约通过调用 challengeExit() 函数执行一个争议,争议成功后会取消正在执行的取款操作,并将提交取款申请所冻结的押金发送给 Bob。
10
攻击场景
在 Plasma 子链中主要存在两种攻击场景: Alice 试图忽视在子链中转移给 Bob 的资产,使用最初加入 Plasma 子链时的交易证明向主链提出取款申请。 Operator 生成一个恶意交易,占有其他用户的资产,并且尝试退出子链。
下面对这两个攻击场景进行分析,观察 Plasma MVP 如何保证资产的安全性:
场景1 Alice 使用最初加入子链时生成的交易作为证据向主链提出取款申请; Bob(或者其他任意用户)拥有 Alice 申请退出的 UTXO 被花费的交易证明,并将此作为证据向主链提出一个争议; 争议生效,Alice 的退出申请被驳回,同时将 Alice 申请退出的押金发送给 Bob; Alice 的攻击失效。
场景2 Operator 创建了一个非法交易,并且将其打包生成区块之后在主链得到确认; Operator 提交取款申请,打算将 Alice 的资产取走; 在争议期内,Alice 发现了 Operator 的恶意行为,立即提出取款申请,退出子链; 由于 Alice 的申请优先级较高,因此会在 Operator 之前退出; Operator 的攻击失效。
11
相关项目 Talk is cheap, show me your code.
目前已经有许多机构和公司已经实现了 Plasma MVP,但实现的语言和细节有所不同: FourthState Lab[3] Omisego[4] Kyokan[5]
12
总结
本文介绍了 Plasma 的最小实现版本 Plasma MVP,虽然采用最简单的 UTXO 模型,但已经足够体现出 Plasma 的核心思想。在 Plasma MVP 中,用户资产的安全主要依赖于用户及时发现恶意行为,并退出子链。接下来的文章将会介绍另外一个稍微复杂一点的项目,Plasma Cash。
13 相关资源
相关资源 https://ethresear.ch/t/minimal-viable-plasma/426 https://ethresear.ch/t/more-viable-plasma/2160 https://github.com/fourthstate https://github.com/omisego/plasma-mvp https://github.com/kyokan/plasma 内容首发:Github 原文作者:盖盖
扩展阅读:
深入理解Plasma(1):Plasma 框架
深入理解Plasma(2):Plasma 细节剖析
「深度学习福利」大神带你进阶工程师,立即查看>>>
btcd p2p 网络分析
比特币依赖于对等网络来实现信息的共享与传输,网络中的每个节点即可以是客户端也可以是服务端,本篇文章基于比特币go版本btcd探索比特币对等网络的实现原理,整个实现从底层到上层可以分为地址,连接,节点三层,每层都有自己的功能与职责。下面逐一的分析这三个部分的构成与功能
地址管理
连接管理对象结构,其中重要的两个成员是addrNew和addTried,前者维护了1024个地址桶,每个桶的尺寸为64,地址经过一个散列算法放入到桶里面,保存的是已经添加尚未确认的连接,后者则维护了64个list,每个确定完好的连接hash散列后放到里面。 type AddrManager struct { mtx sync.Mutex peersFile string lookupFunc func(string) ([]net.IP, error) rand *rand.Rand key [32]byte addrIndex map[string]*KnownAddress // address key to ka for all addrs. addrNew [newBucketCount]map[string]*KnownAddress addrTried [triedBucketCount]*list.List started int32 shutdown int32 wg sync.WaitGroup quit chan struct{} nTried int nNew int lamtx sync.Mutex localAddresses map[string]*localAddress }
当通过AddLocalAddress函数添加一个新的地址的时候,这个地址会先加到addrNew里面,GetAddress会有一半的几率从addrNew里面随机选取一个地址上来尝试进行网络连接校验,如果检验完成,则会调用Good方法,将这个地址从New移动到tred里面。
GetAddress函数选择addrNew和选择addrTried的几率一半一半,选择addrTried用于更新老的可用性差的节点。for循环保证能获取到节点,chance()用于用于桶内位置调整,访问的越频繁这个值越大,选中的可能性越小,这是为了避免多次访问重复的节点。为了防止经过多轮次也无法选中地址,通过factor变量来控制,随着轮次的增加factor增加进而减少上面的限制,意思是实在是找不到没用过的点到用老的也行了。 func (a *AddrManager) GetAddress() *KnownAddress { //省略 // Use a 50% chance for choosing between tried and new table entries. if a.nTried > 0 && (a.nNew == 0 || a.rand.Intn(2) == 0) { // Tried entry. large := 1 << 30 factor := 1.0 for { // pick a random bucket. bucket := a.rand.Intn(len(a.addrTried)) if a.addrTried[bucket].Len() == 0 { continue } randval := a.rand.Intn(large) //控制几率避免段时间访问重复节点 if float64(randval) < (factor * ka.chance() * float64(large)) { log.Tracef("Selected %v from tried bucket", NetAddressKey(ka.na)) return ka } factor *= 1.2 } } else { // new node. // XXX use a closure/function to avoid repeating this. large := 1 << 30 factor := 1.0 for { // Pick a random bucket. bucket := a.rand.Intn(len(a.addrNew)) if len(a.addrNew[bucket]) == 0 { continue } // Then, a random entry in it. var ka *KnownAddress nth := a.rand.Intn(len(a.addrNew[bucket])) for _, value := range a.addrNew[bucket] { if nth == 0 { ka = value } nth-- } randval := a.rand.Intn(large) if float64(randval) < (factor * ka.chance() * float64(large)) { log.Tracef("Selected %v from new bucket", NetAddressKey(ka.na)) return ka } factor *= 1.2 } } }
连接管理
连接主要控制地址的可达性,通过一个状态即来控制连接的生命周期,每个连接都有如下五种状态, ConnPending ConnState = iota ConnFailing ConnCanceled ConnEstablished ConnDisconnected
函数connHandler监控几个chanel()的变化来对应处理连接的状态。
1)ConnPending 通过NewConn函数创建的对象进入该分支处理,将这个新的连接状态标记为ConnPending,并把连接挂到挂起连接里面 case registerPending: connReq := msg.c connReq.updateState(ConnPending) pending[msg.c.id] = connReq close(msg.done)
2)ConnFailing 当Connect函数确认连接出现错误的时候会进入handfail分支标记连接错误 case handleFailed: connReq := msg.c //一种特殊情况,当存在的peer过少,为了保证系统可用会把这个操作当作失败的情况处理 if _, ok := pending[connReq.id]; !ok { log.Debugf("Ignoring connection for "+ "canceled conn req: %v", connReq) continue } connReq.updateState(ConnFailing) log.Debugf("Failed to connect to %v: %v", connReq, msg.err) cm.handleFailedConn(connReq)
3)ConnCanceled 当用户主动断开连接且该连接尚未完全建立的时候视为ConnCanceled状态 case handleDisconnected: connReq, ok := conns[msg.id] if !ok { connReq, ok = pending[msg.id] if !ok { log.Errorf("Unknown connid=%d", msg.id) continue } // Pending connection was found, remove // it from pending map if we should // ignore a later, successful // connection. connReq.updateState(ConnCanceled) log.Debugf("Canceling: %v", connReq) delete(pending, msg.id) continue }
4)ConnEstablished 连接通过函数Connect确认建立成功后变成ConnEstablished case handleConnected: connReq := msg.c if _, ok := pending[connReq.id]; !ok { if msg.conn != nil { msg.conn.Close() } log.Debugf("Ignoring connection for "+ "canceled connreq=%v", connReq) continue } connReq.updateState(ConnEstablished) connReq.conn = msg.conn conns[connReq.id] = connReq log.Debugf("Connected to %v", connReq) connReq.retryCount = 0 cm.failedAttempts = 0 delete(pending, connReq.id) if cm.cfg.OnConnection != nil { go cm.cfg.OnConnection(connReq, msg.conn) }
5)ConnDisconnected 用户主动断开已经建立好的连接,该连接状态会变成ConnDisconnected case handleDisconnected: if connReq.conn != nil { connReq.conn.Close() } if cm.cfg.OnDisconnection != nil { go cm.cfg.OnDisconnection(connReq) } // All internal state has been cleaned up, if // this connection is being removed, we will // make no further attempts with this request. if !msg.retry { connReq.updateState(ConnDisconnected) continue }
连接管理里面还附带了一个用于考评连接质量的估分函数,该数值累加函数如下 func (s *DynamicBanScore) increase(persistent, transient uint32, t time.Time) uint32 { s.persistent += persistent tu := t.Unix() dt := tu - s.lastUnix if transient > 0 { if Lifetime < dt { s.transient = 0 } else if s.transient > 1 && dt > 0 { s.transient *= decayFactor(dt) } s.transient += float64(transient) s.lastUnix = tu } return s.persistent + uint32(s.transient) }
参数和具体的操作有关系,大致来说会随着操作不断累加,操作越多增长的越快,当超过一定阈值后,该peer会休息一段时间,主要是为了防止恶意流量攻击。调用increase的位置都是可能出现大流量的位置(GetData,MemPool...)。
协议
协议层定义了网络消息的读写格式与应答方式,该协议定义了如下的消息类型. CmdVersion = "version" 版本 CmdVerAck = "verack" 联通 CmdGetAddr = "getaddr" 获取地址 CmdAddr = "addr" 发送地址 CmdGetBlocks = "getblocks" 获取区块 CmdInv = "inv" 发送inv(交易/区块) CmdGetData = "getdata" 发送区块数据 CmdNotFound = "notfound" CmdBlock = "block" 发送区块 CmdTx = "tx" 发送交易 CmdGetHeaders = "getheaders"获取区块头 CmdHeaders = "headers" 发送区块头 CmdPing = "ping" CmdPong = "pong" 和ping成对使用 维护连接 CmdAlert = "alert" 无用 CmdMemPool = "mempool" 交易池(代码上看没有用处) CmdFilterAdd = "filteradd" CmdFilterClear = "filterclear" CmdFilterLoad = "filterload" CmdMerkleBlock = "merkleblock" CmdReject = "reject" CmdSendHeaders = "sendheaders" CmdFeeFilter = "feefilter" CmdGetCFilters = "getcfilters" CmdGetCFHeaders = "getcfheaders" CmdGetCFCheckpt = "getcfcheckpt" CmdCFilter = "cfilter" CmdCFHeaders = "cfheaders" CmdCFCheckpt = "cfcheckpt"
inHandler
负责收消息,收到消息解析具体的消息类型,在调用一个更加具体的函数来处理这些消息,这个具体的函数常常是通过配置从上层传递下来的. for atomic.LoadInt32(&p.disconnect) == 0 { rmsg, buf, err := p.readMessage(p.wireEncoding) idleTimer.Stop() //略 atomic.StoreInt64(&p.lastRecv, time.Now().Unix()) p.stallControl <- stallControlMsg{sccReceiveMessage, rmsg} // Handle each supported message type. p.stallControl <- stallControlMsg{sccHandlerStart, rmsg} switch msg := rmsg.(type) { case *wire.MsgVersion: // Limit to one version message per peer. p.PushRejectMsg(msg.Command(), wire.RejectDuplicate, "duplicate version message", nil, true) break out case *wire.MsgVerAck: // No read lock is necessary because verAckReceived is not written // to in any other goroutine. if p.verAckReceived { log.Infof("Already received 'verack' from peer %v -- "+ "disconnecting", p) break out } p.flagsMtx.Lock() p.verAckReceived = true p.flagsMtx.Unlock() if p.cfg.Listeners.OnVerAck != nil { p.cfg.Listeners.OnVerAck(p, msg) } ///略 case *wire.MsgSendHeaders: p.flagsMtx.Lock() p.sendHeadersPreferred = true p.flagsMtx.Unlock() if p.cfg.Listeners.OnSendHeaders != nil { p.cfg.Listeners.OnSendHeaders(p, msg) } default: log.Debugf("Received unhandled message of type %v "+ "from %v", rmsg.Command(), p) } p.stallControl <- stallControlMsg{sccHandlerDone, rmsg} // A message was received so reset the idle timer. idleTimer.Reset(idleTimeout) }
outHandler
通过for select监听sendQueue,如果有新消息进来调用writeMessage发送消息
序列化,反序列化
每条消息都是由消息头和消息体构成。每个消息都实现有一个Message接口, type Message interface { BtcDecode(io.Reader, uint32, MessageEncoding) error BtcEncode(io.Writer, uint32, MessageEncoding) error Command() string MaxPayloadLength(uint32) uint32 }
序列化的过程中先调用BtcDecode方法序列化一个二进制消息体,这里逐个写入消息字段,有兴趣的看wire文件夹下面的每个消息的BtcDecode消息的具体实现。然后双重hash该消息体取其前四位作为消息体校验位,在把网络号,消息名,消息长度,校验位置合起来构成一个消息头。反序列化则是个相反的过程 err := msg.BtcEncode(&bw, pver, encoding) if err != nil { return totalBytes, err } payload := bw.Bytes() lenp := len(payload) //略 // Create header for the message. hdr := messageHeader{} hdr.magic = btcnet hdr.command = cmd hdr.length = uint32(lenp) copy(hdr.checksum[:], chainhash.DoubleHashB(payload)[0:4])
交易控制
在实际应用中节点之间互相广播交易会占用很多流量,为了提高网路性能,节点会控制交易的重发,具体实现为每个peer带有一个knownInventory对象,记录已经发送过的交易Id,发送的时候会检查是否发过,发过的不会在重发发送.这个机制有时候会带来些奇怪的问题.之前在部署网络时候遇到个奇怪的现象就是矿机断电重启后,有些交易需要很久才能打包,原因则在于该机器直接相连的机器认为已经发送过交易,不会在二次重发。 for e := invSendQueue.Front(); e != nil; e = invSendQueue.Front() { iv := invSendQueue.Remove(e).(*wire.InvVect) // Don't send inventory that became known after // the initial check. if p.knownInventory.Exists(iv) { continue } invMsg.AddInvVect(iv) if len(invMsg.InvList) >= maxInvTrickleSize { waiting = queuePacket( outMsg{msg: invMsg}, pendingMsgs, waiting) invMsg = wire.NewMsgInvSizeHint(uint(invSendQueue.Len())) } // Add the inventory that is being relayed to // the known inventory for the peer. p.AddKnownInventory(iv) }
peer管理
peer管理主要负责peer节点的维护,消息的应答方式等
peer维护
peerHandler中for select 监听几个chanel,每个chanel对应几种操作,增删改查之类的,即在系统内部使用也提供外部rpc功能. for { select { // New peers connected to the server. case p := <-s.newPeers: s.handleAddPeerMsg(state, p) // Disconnected peers. case p := <-s.donePeers: s.handleDonePeerMsg(state, p) // Block accepted in mainchain or orphan, update peer height. case umsg := <-s.peerHeightsUpdate: s.handleUpdatePeerHeights(state, umsg) // Peer to ban. case p := <-s.banPeers: s.handleBanPeerMsg(state, p) // New inventory to potentially be relayed to other peers. case invMsg := <-s.relayInv: s.handleRelayInvMsg(state, invMsg) // Message to broadcast to all connected peers except those // which are excluded by the message. case bmsg := <-s.broadcast: s.handleBroadcastMsg(state, &bmsg) case qmsg := <-s.query: s.handleQuery(state, qmsg) case <-s.quit: // Disconnect all peers on server shutdown. state.forAllPeers(func(sp *serverPeer) { srvrLog.Tracef("Shutdown peer %s", sp) sp.Disconnect() }) break out } }
这里有个可以说下的是交易重发机制,主要是解决节点刚启动时候同步交易池的问题,只要连接到节点,等待一段时间,周边的节点就会进行广播,这时候就能得到交易了,考虑到上面说过的knownInv问题,这时候最好是找个新的节点连接比较安全
peer的产生
server 启动时候会调用connManager的Start方法,其中会产生许多的连接对象, for i := atomic.LoadUint64(&cm.connReqCount); i < uint64 (cm.cfg.TargetOutbound); i++ { go cm.NewConnReq() }
NewConnReq函数里面会走上面提过的几种状态变化,最后进到ConnEstablished状态分支里面,该分支会调用OnConnection函数,这个函数就是outboundPeerConnected函数。这里结构有点差,整体上是这样子的,connManager中配置了一个函数变量OnConnect,而在p2p servver启动的时候会赋值connManager的函数,这里就是把outboundPeerConnected函数赋值给connManager的OnConnection变量(OnConnect:PeerConnected)。 func (s *server) outboundPeerConnected(c *connmgr.ConnReq, conn net.Conn) { sp := newServerPeer(s, c.Permanent) p, err := peer.NewOutboundPeer(newPeerConfig(sp), c.Addr.String()) if err != nil { srvrLog.Debugf("Cannot create outbound peer %s: %v", c.Addr, err) s.connManager.Disconnect(c.ID()) } sp.Peer = p sp.connReq = c sp.isWhitelisted = isWhitelisted(conn.RemoteAddr()) sp.AssociateConnection(conn) go s.peerDoneHandler(sp) s.addrManager.Attempt(sp.NA()) }
peer产生之后在调用AssociateConnection关联连接对象的时候就开始进行信息沟通. 调用流程是:AssociateConnection -> start -> negotiateOutboundProtocol -> readRemoteVersionMsg 具体代码就不贴了,该函数最后又会调用到server的OnVersion函数(OnVersion和OnConnect是相同的做法),该函数主要就是校验版本,服务之类的功能是否完整匹配,此后节点就建立成功,之后就可以进行数据的广播同步了. if !cfg.SimNet && !isInbound { addrManager.SetServices(remoteAddr, msg.Services) //服务校验 } // Ignore peers that have a protcol version that is too old. The peer // negotiation logic will disconnect it after this callback returns. if msg.ProtocolVersion < int32(peer.MinAcceptableProtocolVersion) { //版本校验 return nil } //这里是交换地址用的 协议是 getaddr/addr 当你连到一个点的时候互相交换地址, hasTimestamp := sp.ProtocolVersion() >= wire.NetAddressTimeVersion if addrManager.NeedMoreAddresses() && hasTimestamp { sp.QueueMessage(wire.NewMsgGetAddr(), nil) } //这句上面说过会把newAddr移动到triedAddr 这句通过了才说能对象节点是完全可用的 // Mark the address as a known good address. addrManager.Good(remoteAddr)
peer同步维持
有个SyncManager结构体负责区块,交易同步的维护,接上文,新的节点加进来之后刷新bestPeer(原则是高度最高的节点),之后向该节点发送getblocks请求,参数则是自己的高度状态 if sm.nextCheckpoint != nil && best.Height < sm.nextCheckpoint.Height && sm.chainParams != &chaincfg.RegressionNetParams { bestPeer.PushGetHeadersMsg(locator, sm.nextCheckpoint.Hash) sm.headersFirstMode = true log.Infof("Downloading headers for blocks %d to "+ "%d from peer %s", best.Height+1, sm.nextCheckpoint.Height, bestPeer.Addr()) } else { bestPeer.PushGetBlocksMsg(locator, &zeroHash) }
对方收到请求之后,比对高度,查找到自己的BlockHash构造InvTypeBlock类型NewMsgInv消息返回,然后在逐个的请求区块
发送方 接收方 PushGetBlocksMsg(当前自己高度) InvTypeBlock类型NewMsgInv(返回对方没有的高度hash))
OnInv处理后发送NewMsgGetData(接受message后逐个getdata) OnBlock处理附加到链上
MsgBlock(区块详细信息)
「深度学习福利」大神带你进阶工程师,立即查看>>>
10月19-21日,Blockathon2018(上海)在黄浦区P2联合创业办公社举办,这是Blockathon2018在中国区的第三场区块链黑客马拉松竞赛。本次活动由Bitfwd技术社区、HiBlock区块链社区和区块链兄弟联合主办, 获得了来自NEM、澳中理事会、离子链、Olympus Labs、HPB芯链、Tenzorum等的赞助支持,P2联合创业办公社提供场地支持,以太坊爱好者社区、掘金、活动行、it大咖说、飞马网、机械工业出版社华章分社、登链学院等15家合作伙伴以及世链财经、共享财经、铱科技、陀螺财经等20家媒体对活动给予宣传支持。
Blockathon是全球性的区块链开发者竞赛,48小时内,开发者自由组队进行现场开发,完成一个区块链项目的完整交付。Blockathon2018(上海)选拔出50名区块链爱好者组成9支队伍参赛,并邀请到20余位来自全球优秀项目的技术专家担任嘉宾评审,对项目进行指导与点评。
10月20日上午,主办方开放了以“降低区块链应用使用门槛”为主题的开发培训活动,由OlympusLabs、Tenzorum及NEM三个优秀区块链开发团队的核心开发者从各自经验分享如何降低区块链Dapp在大众应用时的技术门槛。同时在10月21日的项目路演环节,邀请60余位观众到场观看路演并进行交流,从现场开发的项目中了解区块链,探讨区块链技术的落地应用思路。通过48小时的活动,50名参赛者共计产生了9个参赛项目。 来自野狼队的Asset Trust 数字资产生态平台获得第一名。
野狼队,由欧阳新民担任队长,队员包括钟冰、朱斌。
项目设计的理念 是由Asset Trust通过NEM公链开发,解决数字资产的防伪交易,实现无缝上链。该项目以艺术品交易作为案例,通过Asset
Trust 数字资产生态平台可以看到艺术品创作过程中的视频,将成品和过程视频上传IPFS实现数字资产防伪。
赛后,欧阳新民从管理的角度做了一些总结,如下是他的原话: 对于这次比赛,就探讨一下我们自己做的好与不好的的方面。
做的不够是:第一,从项目开发完整性的角度看,由于时间关系,欧阳的后端对接异步交易通知程序没来得及写完整,以致于不能开源到Github;第二、演示时间紧,朱斌没能对于自己负责部分讲上话。
做个小结,就是我们组织得不够好,没有提前开项目需求评审会,以致于大家在一开始重视度不够高。
不过我们团队也有做得比较好的地方:队伍三个人,各自分工明确。
1、NEM架构理解得透彻,(钟冰辛苦了,给钟冰点赞),模板素材选得合适;项目路演效果好,PPT讲得好
2、前端UI效果很酷炫(给朱斌点赞);
3、首页图片改成本地路径换来了短时间的好的用户体验(给朱斌点赞);
4、提前对议题做了分析,包括UI原型初步确定,项目前后端协调,准备工作还算充分(给自己点赞);
5、项目开发结束后其他团队在路演时,想到了将项目简介和二维码拼成一张图片发群里,让大家参与进来体验很便利;
6、团队配合度高,项目开发过程中,接口制定和联调比较顺利,包括每天都能在9点左右到达比赛现场。”
欧阳新民说:“之所以能拿到奖,PPT和项目最终呈现效果还是相得益彰,达到了令人满意的效果,退一步说,就算没拿到奖,两天时间内开发到这个程度已经不易。所以,在此感谢两位好友 ! 以及感谢给与机会创办这次活动的主办方与赞助方!!”
附:项目路演PPT,如有投资兴趣请添加微信EF0815联系参赛团队。
如有投资兴趣请添加微信EF0815联系参赛团队。
「深度学习福利」大神带你进阶工程师,立即查看>>>
1
以太坊开发与传统应用开发的差异
相比起传统应用而言,以太坊开发引入了新的基础设施,由此必不可少的带来了部署和运维的复杂度,比如作为系统设计者,我们需要做出选择: 自建节点,还是信任第三方节点? 公有链、联盟链、私有链?
由于加入了新的设计单元:智能合约,我们将面对 设计的复杂度
合约的升级问题:因为智能合约一旦发布就无法更改,万一需要更新合约错误或规则,怎么办?
合约的组织问题。 与一般代码不同,合约的好坏直接与金钱挂钩
不安全的合约会造成客户的金钱损失,立竿见影。
合约的每一步都需要消耗gas,不讲究的合约会造成执行成本高居不下。
并且,以太坊本身的限制同样也会影响到整个应用系统的设计和选型: 交易确认需要时间:20笔/秒 交易易受外界影响
交易费的高低
流行应用会造成网络拥堵,从影响交易的确认
相比起传统CS编程,与以太坊进行交互要复杂得多: 需要有钱包账户 发出去的交易需要签名 由于整个过程是异步为主,因此交易需要验证
对于区块链本身的定位,同样也会影响设计: 仅仅用作数据共享和防篡改的基础设施? 围绕区块链打造价值网络?
Token设计模式
Token引入对于业务本身带来的影响
这一点尤其差异巨大,不单单像传统开发那样仅仅只需要了解用户的业务就可以开足马力前进。Token设计本身需要一定的经济常识,虽说这部分可以由专业背景的人来设计,但对于开发者和架构师而言,不了解必要的基础知识肯定会对开发的顺利进行有阻碍。
2
以太坊Dapp的典型技术架构
Serverless风格
这种架构非常明了,客户端直接与部署在以太坊节点上的智能合约打交道就好了。它的优点和缺点都很明显:
优点: 轻量级 运维简单 彻底的去中心化
缺点: 胖客户端:交互 + 业务逻辑 智能合约难以承载复杂业务逻辑
典型场景:投票、博彩、小游戏等
CS + 区块链
这种架构相当于传统CS(注:这里的传统相对于区块链应用而言,因此像桌面客户端 + 服务器、Web系统、前后端、移动互联网应用等都属于本文中所说的传统应用。)融入了区块链,客户端和服务器都和区块链直接交互。
为什么客户端也需要跟区块链直接交互?原因很简单:区块链应用的账户信息(尤其是私钥)一般都由用户自己保管,不会放在服务器上。服务器上只会存放系统自己的账户信息。
这种系统的优缺点如下:
优点: 传统应用和区块链融合 适用复杂业务逻辑,服务器完全可以包含复杂业务逻辑,合约只承载与价值流转相关的商业规则。
缺点 重量级 运维负担重 部分中心化,话说回来,在我看来,中心化算不上太坏,因为中心化本身代表了专业化。
典型场景:具有复杂业务逻辑的应用系统,如物品溯源、信用质押、供应链金融等等。
Server + 区块链
这种架构相当于上面的一种变体:客户端委托服务器完成与区块链相关的交互,甚至于客户端完全都不知道区块链的存在。为何不推荐采用这种架构呢?原因很明显:它要求客户端绝对信任服务器。
这种架构的优缺点如下:
优点: 对客户端屏蔽了区块链的复杂度
缺点: 私钥中心化管理
典型场景:客户端绝对信任服务器
最后,说说关于 密钥的存放: 若合约部署于第三方节点,如Infura,毫无疑问只能是自己管理。 假如是自建节点,那么你有两种选择
方式1:托管
方式2:自管
同时 出于保障资金安全的角度: 控制托管账户的可用资金,每当可用资金用完,从自管账户中转入 对于自管账户,最好也分散风险,建立多个自管账户,将资金分散其中,避免被一锅端。
3
以太坊应用的开发流程
以太坊应用的开发流程如下图,相比起传统开发流程没有本质的区别,只是测试过程相对繁琐:先本地环境测试,再上测试网试运行,最后部署于主网。只是由于合约的更新麻烦,因此建议尽量提前多做一些测试,将问题提前消灭掉。
4
以太坊开发注意事项
谈完差异,看过架构和展示了开发流程之后,接下来就进入正题,说说本文的重点:以太坊开发的那些坑。
智能合约
智能合约开发的常用工具: Solidity + Truffle + VS Code 常用类库:
Token和ICO相关:OpenZepplin和TokenMarketNet/ICO
可升级合约:ZOS
关于合约的执行成本,我之前写过一篇文章( https://www.jianshu.com/p/cfaa4fdb32ac)有详细介绍,这里就不再赘述,请参见原文,避免不必要的金钱损失。
关于合约的安全,我在这篇文章中( https://www.jianshu.com/p/ec5ad71e28aa)略有提及。但远远不够,这段时间以来,我也翻阅了相关资料,整理如下: Overflow & Underflow,使用OpenZeppelin的SafeMath lib 可见性和delegatecall说明如下,相关推荐:优先external, 并留意避免在delegatecall中包含恶意代码
public,无限制
external,仅外部调用
private,仅本合约内
internal,类似protect
delegatecall,类似js中的apply,被调用代码和调用合约处于一个上下文 可重入性(DAO攻击),利用CDI模式
检查 -> 更改合约状态 -> 支付 优先使用pull模式,而非push/send模式
withdraw 优于 send/transfer 避免使用随机数、now和block.blockhash作为合约逻辑
分布式网络的时钟问题 注意短地址攻击,检查message.data的合法性
地址不足会用金额部分数据补0 利用Modifier完成权限方面的校验
至于合约的设计和组织: 单一大合约 VS 合约模块化 Hub – Spoke模式 使用mapping保存合约数据 合约升级的主要模式
Proxy
数据合约 + 控制合约
Truffle
Truffle作为开发智能合约的利器,不仅仅提供了对于合约开发和测试的支持,它还可以作为合约迁移和部署的工具。这里主要讲讲部署的常用套路。
一般的Truffle例子中大多只是部署单个合约,但有时我们需要部署多个合约,并且这些合约之间有先后依赖关系时,需要顺序部署: var Storage = artifacts.require("./Storage.sol"); var InfoManager = artifacts.require("./InfoManager.sol"); module.exports = function(deployer) { deployer.deploy(Storage) .then(() => Storage.deployed()) // deployer.deploy(`ContractName`, [`constructor params`]) .then(() => deployer.deploy(InfoManager, Storage.address)); }
假如要在部署之后立即执行合约代码: deployer.deploy(Storage) .then(() => Storage.deployed()) .then((instance) => { instance.addData("Hello", "world") })
如果要部署到不同的网络环境,可以采用如下命令: truffle migrate --network network_id
此时需要在truffle.js中设置好合适的network_id,部署脚本如下: module.exports = function(deployer, network) { if (network == "live") { // do one thing } else if (network == "development") { // do other thing } }
如果要换账户部署,则: module.exports = function(deployer, network, accounts) { var defaultAccount; if (network == "live") { defaultAccount = accounts[0] } else { defaultAccount = accounts[1] } }
并且往往会跟HDWalletProvider结合使用。
同时把合约部署到Infura上也会用到它: const HDWalletProvider = require("truffle-hdwallet-provider"); module.exports = { networks: { "ropsten-infura": { provider: () => new HDWalletProvider("
", "https://ropsten.infura.io/"), network_id: 3, gas: 4700000 } } };
如果合约用到了lib,则: deployer.deploy(MyLibrary); deployer.link(MyLibrary, MyContract); deployer.deploy(MyContract);
WEB3J
对于Java和Android开发者,如果要开发以太坊应用,离不开web3j,它的大致使用流程如下:
但请 注意 : 合约的部署建议直接用Truffle完成,如前所述,Truffle不仅仅只是开发,它提供了对于合约的一整套生命周期管理。 生成钱包可选步骤,可以使用外部现有钱包账户 合约本身的测试建议用Truffle 此处测试专注于应用本身逻辑和合约逻辑的集成测试 测试建议用Ganache
对于新手,一个常常犯的错误就是选错TransactionManager,它一旦选错,将交易导致。假如你发起交易,而交易没有发出去,同时报诸如:TransactionHashMissMatched,那么十有八九就是这个问题。
TransactionManager有两种: ClientTransactionManager,适用于私钥放在以太坊客户端,由它来签名并发送交易的场合。典型如:geth和ganache中账户。 RawTransactionManager,适用于由应用客户端自己签名并发送交易的场合。典型如:私钥不在自有geth节点和使用第三方节点。
在使用RawTransactionManager时,需要注意设置好合适的chainid。
有时,交易发出之后,发现长时间处于Pending状态,那么请检查(假如不是网络拥堵的情况): 是否设置了合适的gasprice 是否设置了合适的nonce,它有点类似数据库中的sequence,一旦用过就不能再被使用。
同时,还需要留意有多少节点接受了交易所在区块。接受的节点越多,交易越不可能被回滚。确认算法:当前区块高度 - TX所处区块高度 > 指定块数,对于Ganache测试环境,这个值可以是0。
假如你的交易比较重要,可能需要根据交易的重要程度,动态调整这个值。
最后,避免使用send方法,使用sendAsync,并结合CompletableFuture。
其他工具
假如你的工具栈是javascript/typescript,那么: web3.js,基础 truffle-contract,更好的合约抽象 ethers.js,更高抽象层次的以太坊交互接口
从某些方面来讲,ethers.js与web3.js有重叠,但前者对钱包开发提供了更友好的接口。
假如前端页面想将MetaMask直接集成进来,即遇到以太坊交互时直接激活MetaMask,那么可以用下面的代码: // Adapted from https://github.com/MetaMask/faq/blob/master/DEVELOPERS.md#partly_sunny-web3---ethereum-browser-environment-check window.addEventListener('load', function() { // Checking if Web3 has been injected by the browser (Mist/MetaMask) if (typeof web3 !== 'undefined') { // Use Mist/MetaMask's provider window.web3 = new Web3(web3.currentProvider); } else { // fallback - use your fallback strategy (local node / hosted node + in-dapp id mgmt / fail) window.web3 = new Web3(new Web3.providers.HttpProvider("http://localhost:8545")); } // Now you can start your app & access web3 freely: startApp() })
合约部署
从大的方面讲,合约部署有两种选择,但各自都有其优缺点:
私有节点
优点: 完全掌控 适用于应用不能随意访问第三方节点的场合
缺点: 节点安全自我保证 账本同步问题,如断电重启;节点与外部断开一段时间才发现,由此导致的分叉 若私钥寄存在节点,存在安全风险
第三方(如infura)
优点: 运维负担甩给第三方 不需分享私钥
缺点: 需要信任第三方节点,因为第三方有可能不把交易发出去,返回伪造信息。 非完整API,如infura不支持filter API调用频率有限制
这里没有谁优谁劣,只能根据自己的需求权衡后选择。
5
总结
总的来讲: 区块链开发与传统应用开发差异很大 智能合约设计不等同于
数据库设计
传统OO设计 与以太坊的交互不是简单的请求调用 实践出真知
多看、多听、多交流
选择优秀类库
测试、测试、再测试
6
参考资料
参考链接: Web3J文档: https://web3j.readthedocs.io/ Trffule文档: https://truffleframework.com/docs OpenZeppelin文档: https://openzeppelin.org/api/ 以太坊开发极简入门: https://www.jianshu.com/p/bec173e6cf73 面向老程序员的Solidity摘要: https://www.jianshu.com/p/ec5ad71e28aa OpenZeppelin周记:打开地图: https://www.jianshu.com/p/3d09bbafd8f2 Designing the architecture for your Ethereum application: https://blog.zeppelin.solutions/designing-the-architecture-for-your-ethereum-application-9cec086f8317 Dapp Architecture Designs: https://github.com/ConsenSys/Ethereum-Development-Best-Practices/wiki/Dapp-Architecture-Designs How to Secure Your Smart Contracts: 6 Solidity Vulnerabilities and how to avoid them (Part 1): https://medium.com/loom-network/how-to-secure-your-smart-contracts-6-solidity-vulnerabilities-and-how-to-avoid-them-part-1-c33048d4d17d How to Secure Your Smart Contracts: 6 Solidity Vulnerabilities and how to avoid them (Part 2): https://medium.com/loom-network/how-to-secure-your-smart-contracts-6-solidity-vulnerabilities-and-how-to-avoid-them-part-2-730db0aa4834 遗忘的亚特兰蒂斯:以太坊短地址攻击详解: https://www.anquanke.com/post/id/159453 内容来源:简书
作者 | 胡键
本文源自我在10月27日HiBlock线下沙龙的分享,同时也可以算是到目前为止来自实际项目的一线总结,希望其中的内容能够帮助后来者少踩些坑,节约宝贵的时间。
「深度学习福利」大神带你进阶工程师,立即查看>>>
1. 发起转账的地址上必须要有btc作为费用
2. 但是,usdt和btc的交易有可能会把这个地址上的btc给charge到其他地址上
3. 所以你得给这个地址时不时的补充btc
以上是用的纯钱包方式,还可以不依赖于钱包,用rawtransaction方式,这个稍复杂,每个转账,都需要获得这个地址的所有utxo,然后从这些utxo算出足够多的utxo用户支付手续费 和 转账时浪费的btc,这里浪费的btc,最低是546个satoshi,低于这个值就交易发不出,节点会认为是dust txout
「深度学习福利」大神带你进阶工程师,立即查看>>>
本文面向以太坊智能合约应用程序开发人员,并讨论如何在密码保护后,安全地运行你的以太坊节点,以便通过Internet进行安全输出。
Go Ethereum(geth)是以太坊节点最受欢迎的软件。其他流行的以太坊实现是Parity和cpp-ethereum等。分布式应用程序(Dapps)是JavaScript编码的网页,通过JSON-RPC API协议连接到任何这些以太坊节点软件,该协议是在HTTP协议之上自行运行的。
geth或没有节点软件本身不提供安全网络。将Ethereum JSON-RPC API暴露给公共Internet是不安全的,因为即使禁用私有API,这也会为琐碎的拒绝服务攻击打开一扇门。节点软件本身不需要提供安全的网络原语,因为这种内置功能会增加复杂性并为关键区块链节点软件增加攻击面。
Dapps本身是纯客户端HTML和JavaScript,不需要任何服务器,它们可以在任何Web浏览器中运行,包括移动和嵌入式浏览器,如Mist钱包内的一个。
使用Nginx代理作为HTTP基本身份验证器
有几种方法可以保护对HTTP API的访问。最常见的方法包括HTTP头中的API令牌,基于cookie的身份验证或 HTTP基本访问身份验证 。
HTTP基本身份验证是HTTP协议的一个非常古老的功能,其中Web浏览器打开一个本机弹出对话框,询问用户名和密码。它本质上的保护是有限的,但非常容易实现,非常适合需要为有限的互联网受众暴露私有Dapp的用例。这些用例包括显示Dapp演示,私有和许可的区块链应用程序或将以太坊功能作为软件即服务解决方案的一部分。
Nginx
Nginx 是最受欢迎的开源Web服务器应用程序之一。我们将展示如何设置Nginx Web服务器,以便它使用HTTP Basic Auth私下为你的Dapp(HTML文件)和geth JSON-RPC API提供服务。
我们假设Ubuntu 14.04更新的Linux服务器。文件位置可能取决于使用的Linux发行版。
安装Nginx
在Ubuntu Linux 14.04或更高版本上安装Nginx: sudo apt install nginx apache2-utils
配置Nginx
我们假设我们编辑默认的网站配置文件 /etc/nginx/sites-enabled/default 。我们使用 proxy_pass指令 与在 localhost:8545 中运行的geth进行通信: server { listen 80 default_server; listen [::]:80 default_server ipv6only=on; server_name demo.example.com; # Geth proxy that password protects the public Internet endpoint location /eth { auth_basic "Restricted access to this site"; auth_basic_user_file /etc/nginx/protected.htpasswd; # Proxy to geth note that is bind to localhost port proxy_pass http://localhost:8545; } # Server DApp static files location / { root /usr/share/nginx/html; index index.html auth_basic "Restricted access to this site"; auth_basic_user_file /etc/nginx/protected.htpasswd; } }
使用密码创建HTTP Basic Auth用户演示: sudo htpasswd -c /etc/nginx/protected.htpasswd demo
配置geth
开始使用geth守护进程的最简单方法是在UNIX screen 中运行它: screen geth # Your command line parameters here
退出 screen 使用 CTRL+A, D 。
请参阅geth private testnet说明
配置Dapp
在你的Dapp中,使web3.js使用 /eth 端点: function getRPCURL() { // ES2016 if(window.location.href.includes("demo.nordledger.com")) { // Password protected geth deployment return "http://demo.nordledger.com/eth" } else { // Localhost development return "http://localhost:8545"; } } // ... web3.setProvider(new web3.providers.HttpProvider(getRPCURL()));
部署Dapp
将DApp文件复制到服务器上的 /usr/share/nginx/html 。这包括index.html以及相关的JavaScript和CSS资源。
Bonus - 部署shell脚本示例: #!/bin/bash # # A simple static HTML + JS deployment script that handles Nginx www-data user correclty. # Works e.g. Ubuntu Linux Azure and Amazon EC2 Ubuntu server out of the box. # set -e set -u # The remote server we are copying the files using ssh + public key authentication. # Specify this in .ssh/config REMOTE="nordledger-demo" # Build dist folder using webpack npm run build # Copy local dist folder to the remote server Nginx folder over sudoed # Assum the default user specified in .ssh/config has passwordless sudo # https://crashingdaily.wordpress.com/2007/06/29/rsync-and-sudo-over-ssh/ rsync -a -e "ssh" --rsync-path="sudo rsync" dist/* --chown www-data:www-data $REMOTE:/usr/share/nginx/html/
重启Nginx
为Nginx做一次硬重启: service nginx stop service nginx start
测试并迭代
访问网站,看看您的Dapp是否连接到代理的Geth。
检查 /var/log/nginx/error.log 以获取详细信息。
如果从 /eth 端点获得502 Bad Gateway,请确保geth正在作为服务器上的后台进程正常运行。
======================================================================
分享一些以太坊、EOS、比特币等区块链相关的交互式在线编程实战教程: java以太坊开发教程 ,主要是针对java和android程序员进行区块链以太坊开发的web3j详解。 python以太坊 ,主要是针对python工程师使用web3.py进行区块链以太坊开发的详解。 php以太坊 ,主要是介绍使用php进行智能合约开发交互,进行账号创建、交易、转账、代币开发以及过滤器和交易等内容。 以太坊入门教程 ,主要介绍智能合约与dapp应用开发,适合入门。 以太坊开发进阶教程 ,主要是介绍使用node.js、mongodb、区块链、ipfs实现去中心化电商DApp实战,适合进阶。 C#以太坊 ,主要讲解如何使用C#开发基于.Net的以太坊应用,包括账户管理、状态与交易、智能合约开发与交互、过滤器和交易等。 EOS教程 ,本课程帮助你快速入门EOS区块链去中心化应用的开发,内容涵盖EOS工具链、账户与钱包、发行代币、智能合约开发与部署、使用代码与智能合约交互等核心知识点,最后综合运用各知识点完成一个便签DApp的开发。 java比特币开发教程 ,本课程面向初学者,内容即涵盖比特币的核心概念,例如区块链存储、去中心化共识机制、密钥与脚本、交易与UTXO等,同时也详细讲解如何在Java代码中集成比特币支持功能,例如创建地址、管理钱包、构造裸交易等,是Java工程师不可多得的比特币开发学习课程。 php比特币开发教程 ,本课程面向初学者,内容即涵盖比特币的核心概念,例如区块链存储、去中心化共识机制、密钥与脚本、交易与UTXO等,同时也详细讲解如何在Php代码中集成比特币支持功能,例如创建地址、管理钱包、构造裸交易等,是Php工程师不可多得的比特币开发学习课程。
这里是 原文
「深度学习福利」大神带你进阶工程师,立即查看>>>
近日,链塔数据BlockData发布了《2018年8月以太坊DApp数据分析报告》,报告显示,以太坊上的DApp数量多达775个,形成了一个较为完善的开发生态圈,累计交易笔数多达3.0036603亿,累计交易金额超过59亿ETH。
1
以太坊DApp总数达775个
以太坊是一个开源的,有智能合约功能的公共区块链平台,基于以太币提供去中心化的虚拟机来处理点对点合约,通过一套脚本语言实现让用户建立去中心化应用的功能。
以太坊给DApp提供了一个底层区块链开发平台和共识机制,区块链应用开发者可以直接基于以太坊平台进行开发,大大降低了DApp应用的开发难度。
目前,以太坊上的DApp数量多达775个,形成了一个较为完善的开发生态圈,累计交易笔数多达3亿,累计交易金额超过59亿ETH。以太坊的累计用户已经超过3587万人,日均活跃人数多达20万人。
2
8月以太坊市值及DApp交易分析
8月份以太坊市值持续走低,下旬止住颓势。
2018年以来,以太坊上的DApp数量持续增长,用户对于去中心化应用的热情并未减弱。受到监管政策影响,以太坊的热度自5月份开始出现大幅下降,8月份起,热度开始回升,环比增长8%,日均搜索数量高达6239次。
链塔智库团认为,以太坊的热度回升一方面源于公众对于区块链技术与发展前景的认可,区块链有望与传统技术相结合,解决多行业痛点。另一方面是监管政策把各区块链企业重新拉回对技术本身的思考,对实业落地的规划。
2018年8月,以太坊的市值持续下跌,但在下旬止住颓势,总体保持稳定。以太坊的市值持续走低是受交易市场变冷、政策监管、以太坊网络拥堵、比特大陆以太矿机出现等多因素干扰。
2018年8月Ethereum市值变化图
8月以太坊交易额稳定,交易笔数起伏较大。
以太坊8月份的交易额保持稳定,没有出现大幅波动,日平均交易额为157.7万ETH,总交易额为4730 ETH。
2018年8月以太坊交易额曲线图
以太坊8月份的交易笔数起伏较大,但总体表现依然稳定,截至8月30日,日平均交易笔数为64万笔,总交易笔数为1931万笔,与7月份相比并无较大差别。
2018年8月以太坊交易笔数曲线图
8月份Gas消耗量小幅下降,价格保持在较低水平。
Gas 是以太坊世界的燃料,它决定了以太坊网络生态系统的正常运行,用于交易、执行智能合约、支付数据存储费用等各个方面。Gas同时也是矿工的佣金,并以ETH支付。Gas的消耗量可以直观反映以太坊平台的交易情况,8月份Gas平均日消耗量为420亿个,同比下降1.83%,表明以太坊平台的交易量仍然出现小幅下降。
2018年8月Gas消耗量
Gas 价格由用户自己决定,代表用户愿意花费在每个Gas单位上的价格。Gas价格在一定程度上代表了矿工的收入水平,也反映了交易量的大小。8月份Gas的平均价格为191.29亿wei,保持在一个较低的水平。
2018年8月Gas平均价格
3
以太坊用户分析
8月份以太坊日均活跃用户数量同比增长近10%,反映以太坊平台运营情况较好。
2018年8月以太坊日均活跃用户曲线
8月份以太坊平均日新增用户数量持续下降,幅度巨大。分析是市场持续走冷,政策监管施压等多种原因综合导致。
2018年8月以太坊新增用户曲线
4
以太坊DApp数据总览
以太坊DApp游戏市场火爆,占比超过50%。
截至2018年8月31日,以太坊平台共收录了775个DApp,其中游戏类DApp共计411个,占比高达54%,游戏市场的持续火爆吸引了大批开发人员投入区块链游戏产业;竞猜类DApp共有152个,占20%;交易市场占比仅有4%,与以太坊上线初期对比有较大差距,由于行情变冷,交易所数量趋于饱和,交易市场类DApp进入市场的速度明显放缓;其他类DApp占22%,涉及域名服务等各个领域。
以太坊新增DApp中,游戏市场持续火爆,交易市场趋冷。
以太坊平台8月份共新上线了57个DApp,平均日上线1.84个,保持了较高的增长率,平台整体运营情况较好。
其中新上线游戏类DApp共计31个,占比高达54%,仍然占据了市场的主流地位,游戏市场持续火爆;竞猜类DApp共新上线10个,占18%,整体情况稳定;交易市场类DApp趋冷,8月份仅有1个上线,占2%,与近期市场表现相吻合;其他类DApp新上线15个,占26%。
以太坊DApp中,交易市场类的交易总额仍然占据龙头。
8月份,交易市场类DApp仍然占据了较大的交易份额,占56%;竞猜类占27%;游戏类DApp在数量上占据了较大优势,但交易总额一般,排名较为靠后,仅占11%。
5
以太坊DApp数据分类解析
交易市场类:交易市场呈现寡头垄断态势,IDEX优势明显。
以太坊平台上的交易市场类DApp共有34个,其中排名前五的交易市场类DApp占据了8月份高达94.03%的交易额,呈现出明显的寡头垄断态势。其中IDEX交易总额最高,展现出明显的优势;Bancor与ForkDelta的交易额紧随其后。
游戏类:休闲养成类区块链游戏成为主流
以太坊平台上的游戏类DApp共有411个,8月份排名前五的游戏类DApp中的4个为休闲养成类游戏,仅有God Unchained TCG属于卡牌竞技类游戏且交易总额最高,优势明显。
竞猜类:FairDapp热度激增,Fomo3D依旧火爆
以太坊平台上的竞猜类DApp共有152个,FairDapp在8月下旬热度超越Fomo3D上升到第一位。从交易额看,Dice2.win最高。Fomo3D日均活跃人数为973人,处于领先地位。
其他类:提供数据或交易服务类DApp占比较大
以太坊平台上的其他类DApp共有178个,提供数据或交易服务类DApp占比较大。排名前五的DApp中仅有Minds为一款网络社交平台应用,其余均为提供数据或交易服务类应用。
内容来源于:知乎
作者:链塔智库
「深度学习福利」大神带你进阶工程师,立即查看>>>
1
摘要
以太坊智能合约语言Solitidy是一种面向对象的语言,本文结合面向对象语言的特性,讲清楚Solitidy语言的多态(Polymorphism)(重写,重载),继承(Inheritance)等特性。
2
合约说明
Solidity 合约类似于面向对象语言中的类。合约中有用于数据持久化的状态变量,和可以修改状态变量的函数。 调用另一个合约实例的函数时,会执行一个 EVM 函数调用,这个操作会切换执行时的上下文,这样,前一个合约的状态变量就不能访问了。
面向对象(Object Oriented,OO)语言有3大特性:封装,继承,多态,Solidity语言也具有着3中特性。
面向对象语言3大特性的说明解释如下: 封装(Encapsulation)
封装,就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。一个类就是一个封装了数据以及操作这些数据的代码的逻辑实体。在一个对象内部,某些代码或某些数据可以是私有的,不能被外界访问。通过这种方式,对象对内部数据提供了不同级别的保护,以防止程序中无关的部分意外的改变或错误的使用了对象的私有部分。 继承(Inheritance)
继承,指可以让某个类型的对象获得另一个类型的对象的属性的方法。它支持按级分类的概念。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。 通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”。继承的过程,就是从一般到特殊的过程。要实现继承,可以通过 “继承”(Inheritance)和“组合”(Composition)来实现。继承概念的实现方式有二类:实现继承与接口继承。实现继承是指直接使用 基类的属性和方法而无需额外编码的能力;接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力。 多态(Polymorphism)
多态,是指一个类实例的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。
另外也解释一下重载和重写。
重载(Override)是多态的一种形式,是一个类的内部,方法中多个参数,根据入参的个数不同,会返回不同的结果。
重写(Overwrited),是子类继承父类,重写父类的方法。多态性是允许你将父对象设置成为一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。多态性在Object Pascal和C++中都是通过虚函数的。
3
函数重载(Override)
合约可以具有多个不同参数的同名函数。这也适用于继承函数。以下示例展示了合约 A 中的重载函数 f。 pragma solidity ^0.4.16; contract A { function f(uint _in) public pure returns (uint out) { out = 1; } function f(uint _in, bytes32 _key) public pure returns (uint out) { out = 2; } }
重载函数也存在于外部接口中。如果两个外部可见函数仅区别于 Solidity 内的类型而不是它们的外部类型则会导致错误。 // 以下代码无法编译 pragma solidity ^0.4.16; contract A { function f(B _in) public pure returns (B out) { out = _in; } function f(address _in) public pure returns (address out) { out = _in; } } contract B { }
以上两个 f 函数重载都接受了 ABI 的地址类型,虽然它们在 Solidity 中被认为是不同的。
3.1 重载解析和参数匹配
通过将当前范围内的函数声明与函数调用中提供的参数相匹配,可以选择重载函数。 如果所有参数都可以隐式地转换为预期类型,则选择函数作为重载候选项。如果一个候选都没有,解析失败。 pragma solidity ^0.4.16; contract A { function f(uint8 _in) public pure returns (uint8 out) { out = _in; } function f(uint256 _in) public pure returns (uint256 out) { out = _in; } }
调用 f(50) 会导致类型错误,因为 50 既可以被隐式转换为 uint8 也可以被隐式转换为 uint256。 另一方面,调用 f(256) 则会解析为 f(uint256) 重载,因为 256 不能隐式转换为 uint8。 注解:返回参数不作为重载解析的依据。
4
继承
通过复制包括多态的代码,Solidity 支持多重继承。
所有的函数调用都是虚拟的,这意味着最远的派生函数会被调用,除非明确给出合约名称。
当一个合约从多个合约继承时,在区块链上只有一个合约被创建,所有基类合约的代码被复制到创建的合约中。
总的来说,Solidity 的继承系统与 Python的继承系统 ,非常 相似,特别是多重继承方面。
下面的例子进行了详细的说明。 pragma solidity ^0.4.16; contract owned { function owned() { owner = msg.sender;} address owner; } // 使用 is 从另一个合约派生。派生合约可以访问所有非私有成员,包括内部函数和状态变量, // 但无法通过 this 来外部访问。 contract mortal is owned { function kill() { if (msg.sender == owner) selfdestruct(owner); } } // 这些抽象合约仅用于给编译器提供接口。 // 注意函数没有函数体。// 如果一个合约没有实现所有函数,则只能用作接口。 contract Config { function lookup(uint id) public returns (address adr); } contract NameReg { function register(bytes32 name) public; function unregister() public; } // 可以多重继承。请注意,owned 也是 mortal 的基类, // 但只有一个 owned 实例(就像 C++ 中的虚拟继承)。 contract named is owned, mortal { function named(bytes32 name) { Config config = Config(0xD5f9D8D94886E70b06E474c3fB14Fd43E2f23970); NameReg(config.lookup(1)).register(name); } // 函数可以被另一个具有相同名称和相同数量/类型输入的函数重载。 // 如果重载函数有不同类型的输出参数,会导致错误。 // 本地和基于消息的函数调用都会考虑这些重载。 function kill() public { if (msg.sender == owner) { Config config = Config(0xD5f9D8D94886E70b06E474c3fB14Fd43E2f23970); NameReg(config.lookup(1)).unregister(); // 仍然可以调用特定的重载函数。 mortal.kill(); } } } // 如果构造函数接受参数, // 则需要在声明(合约的构造函数)时提供, // 或在派生合约的构造函数位置以修饰器调用风格提供(见下文)。 contract PriceFeed is owned, mortal, named("GoldFeed") { function updateInfo(uint newInfo) public { if (msg.sender == owner) info = newInfo; } function get() public view returns(uint r) { return info; } uint info; }
注意,在上边的代码中,我们调用 mortal.kill() 来“转发”销毁请求。 这样做法是有问题的,在下面的例子中可以看到: pragma solidity ^0.4.0; contract owned { function owned() public { owner = msg.sender;} address owner; } contract mortal is owned { function kill() public { if (msg.sender == owner) selfdestruct(owner); } } contract Base1 is mortal { function kill() public { /* 清除操作 1 */ mortal.kill(); } } contract Base2 is mortal { function kill() public { /* 清除操作 2 */ mortal.kill(); } } contract Final is Base1, Base2 { }
调用 Final.kill() 时会调用最远的派生重载函数 Base2.kill,但是会绕过 Base1.kill, 主要是因为它甚至都不知道 Base1 的存在。解决这个问题的方法是使用 super: pragma solidity ^0.4.0; contract owned { function owned() public { owner = msg.sender; } address owner; } contract mortal is owned { function kill() public { if (msg.sender == owner) selfdestruct(owner); } } contract Base1 is mortal { function kill() public { /* 清除操作 1 */ super.kill(); } } contract Base2 is mortal { function kill() public { /* 清除操作 2 */ super.kill(); } } contract Final is Base1, Base2 { }
如果 Base2 调用 super 的函数,它不会简单在其基类合约上调用该函数。 相反,它在最终的继承关系图谱的下一个基类合约中调用这个函数,所以它会调用 Base1.kill() (注意最终的继承序列是——从最远派生合约开始:Final, Base2, Base1, mortal, ownerd)。 在类中使用 super 调用的实际函数在当前类的上下文中是未知的,尽管它的类型是已知的。 这与普通的虚拟方法查找类似。
4.1 基类构造函数的参数
派生合约需要提供基类构造函数需要的所有参数。这可以通过两种方式来完成: pragma solidity ^0.4.0; contract Base { uint x; function Base(uint _x) public { x = _x; } } contract Derived is Base(7) { function Derived(uint _y) Base(_y * _y) public { } }
一种方法直接在继承列表中调用基类构造函数(is Base(7))。 另一种方法是像 修饰器modifier 使用方法一样, 作为派生合约构造函数定义头的一部分,(Base(_y * _y))。 如果构造函数参数是常量并且定义或描述了合约的行为,使用第一种方法比较方便。 如果基类构造函数的参数依赖于派生合约,那么必须使用第二种方法。 如果像这个简单的例子一样,两个地方都用到了,优先使用 修饰器modifier 风格的参数。
4.2 多重继承与线性化
编程语言实现多重继承需要解决几个问题。 一个问题是 钻石问题。 Solidity 借鉴了 Python 的方式并且使用“ C3 线性化 ”强制一个由基类构成的 DAG(有向无环图)保持一个特定的顺序。 这最终反映为我们所希望的唯一化的结果,但也使某些继承方式变为无效。尤其是,基类在 is 后面的顺序很重要。 在下面的代码中,Solidity 会给出“ Linearization of inheritance graph impossible ”这样的错误。 // 以下代码编译出错 pragma solidity ^0.4.0; contract X {} contract A is X {} contract C is A, X {}
代码编译出错的原因是 C 要求 X 重写 A (因为定义的顺序是 A, X ), 但是 A 本身要求重写 X,无法解决这种冲突。
可以通过一个简单的规则来记忆: 以从“最接近的基类”(most base-like)到“最远的继承”(most derived)的顺序来指定所有的基类。
4.3 继承有相同名字的不同类型成员
当继承导致一个合约具有相同名字的函数和 修饰器modifier 时,这会被认为是一个错误。 当事件和 修饰器modifier 同名,或者函数和事件同名时,同样会被认为是一个错误。 有一种例外情况,状态变量的 getter 可以覆盖一个 public 函数。 本文作者:HiBlock区块链社区技术布道者辉哥
原文发布于简书
以下是我们的社区介绍,欢迎各种合作、交流、学习:)
「深度学习福利」大神带你进阶工程师,立即查看>>>
前一篇文章《 Hyperledger Fabric on SAP Cloud Platform 》,我的同事Aviva已经给大家介绍了基于区块链技术的超级账本(Hyperledger)的一些概要知识。Fabric是超级账本5个并行项目中的其中之一,因为发展较为成熟,SAP云平台对Fabric也提供了较好的支持。
学完了前一篇文章的理论知识后,今天我们来动手实践一下。
我们做的这个练习的范围很窄,就是学会如何使用go语言开发一组微服务,这组微服务包含读和写两个API,能够将数据写入架设于SAP云平台上的超级账本服务。
大家还记得之前Aviva介绍的智能合约(Smart Contract)么?
简单地说,应用程序通过智能合约接口同超级账本进行读写操作。我们将开发一个Hello World的智能合约,部署到SAP云平台上。出于简单起见,我们没有开发应用,而是简单地在SAP云平台的API控制台上直接消费这个Hello World的智能合约,对云平台上的超级账本进行读和写。
打开超级账本项目Fabric的github仓库地址:
https://github.com/hyperledger/fabric
发现Fabric项目是Google的编程语言GoLang开发的,因此咱们这个练习也使用Go语言来进行智能合约的开发。
1. 从Google上将Go语言1.11版的二进制包下载到本地,解压到/usr/local目录下:
sudo tar -C /usr/local -xzf /home/vagrant/Downloads/go1.11.linux-amd64.tar.gz
将该目录配置到环境变量PATH中去:
2. Fabric项目已经将智能合约同超级账本的通信封装到一个名叫shim的接口中,我们只需要在我们编写的智能合约代码中直接调用该shim接口即可。
我们使用import将这个shim接口的依赖引入进来,在第14行定义一个结构体,包含ID和Value两个字段。这个结构体即是待写入超级账本的数据结构,ABAP顾问可以将其视为ABAP数据字典里定义的结构体。
第46行定义的方法Invoke是这个最简单的智能合约的核心代码,cc *MessageStore这个语法和C语言很像,定义了一个类型为MessageStore的指针变量cc。这个指针变量同C++的 this指针 和ABAP的 me引用 作用类似,在方法被调用时,指向了方法的调用者。
Invoke后面括号里的stub shim.ChaincodeStubInterface定义了该方法的输入参数(形参)stub, 类型为shim.ChaincodeStubInterface。
这个Invoke方法不会通过应用程序显式调用,而是通过超级账本程序回调:当方法被调用时,指针cc和输入参数stub已经自动被Fabric框架赋上了对应值。在Invoke方法运行的上下文里,通过输入参数stub判断出当前回调的场景是读还是写,然后进入对应的分支。分支内部调用我们自己开发的write和read方法同超级账本进行交互。具体源码在我的github上:
https://github.com/i042416/KnowlegeRepository/blob/master/ABAP/blockchain/message_store_chaincode.go
这种通过同一个回调函数内部的switch case来处理多个场景的做法,ABAP和Java开发者应该都不陌生。比如下图是通过InvocationHandler实现Java动态代理的例子,其中invoke方法的逻辑结构和本文智能合约代码的结构非常相似。
关于ABAP和Java里各种静态代理和动态代理的写法,请参考我的博客:
Various Proxy Design Pattern implementation variants in Java, ABAP and JavaScript
https://blogs.sap.com/2017/04/17/various-proxy-design-pattern-implementation-variants-in-java-and-abap/
3. 将开发好的智能合约源文件构建成可执行文件。这一步确保在部署智能合约到SAP云平台之前,先在本地开发环境将所有潜在错误全部检测出并修复。
4. 登录SAP云平台,在Service Marketplace里点击Hyperledger Fabric的超链接:
创建一个新的Service实例:
创建过程中需要填写channel的ID和密匙。
还记得上一篇文章Aviva提到区块链分为 公有链 , 私有链 和 联盟链 ,而超级账本属于联盟链么?在联盟链里,有一个专门的称为MSP(Membership Service Provider)的模块,提供成员管理服务,只有授权用户才能接入区块链网络。这里我事先在SAP云平台上创建了一个渠道并进行认证,因此此处直接输入一个合法的渠道ID和密匙。关于SAP云平台上超级账本渠道的创建和成员授权接入的步骤,请参考SAP帮助文档:
https://help.sap.com/viewer/p/HYPERLEDGER_FABRIC
Service实例创建完毕后,点击Create Service Key按钮创建key,目的是生成用于OAuth认证的clientId和clientSecret,方便接下来的API调用。
点击Service实例的Referencing Apps面板,点击按钮Open Dashboard:
点击Deploy Chaincode,选择本地构建好的zip包,进行上传并部署。这个按钮同SAP云平台Neo和CloudFoundry环境部署本地应用的逻辑相同。
部署成功后,点击Test Chaincode超链接进入API控制台。
该控制台集成了Swagger框架,在调用post请求进行超级账本的写操作和get请求进行读操作之前,先要点击Authorize按钮进行身份认证:
输入第四步创建Service Key后生成的clientID和clientSecret进行认证:
认证成功后,可以在Swagger的控制台里调用post和get请求了。
首先发送post请求,请求负载就是一个简单的json对象,id为i042416,value为Hello World:
post请求在SAP云平台上的超级账本执行成功,返回200响应码:
紧接着执行get请求,输入刚才写入的数据id: i042416:
get请求能够将之前通过post请求写入账本的数据成功读出来:
登录SAP云平台超级账本控制台,能看到之前通过post写入的数据已经加入到区块链尾部的区块了。点击区块可以查看数据明细:
在超级账本控制台的API Calls和Logs面板里也能看到每次超级账本读写的详细信息。
总结一下,SAP云平台的超级账本服务,成功地帮助了希望使用这项区块链技术的企业避免了硬件基础设施的投入,同时屏蔽了大部分超级账本平台管理的底层细节。通过SAP云平台提供的控制台,即可实现对超级账本进行设备接入,访问控制,服务监控等管理功能。同时,通过Go语言编写的智能合约一旦部署到SAP云平台,生成的Restful API能够被其他编程语言方便地消费。调用这些API写入超级账本区块链中的数据将无法再被篡改。使用SAP云平台的超级账本服务,应用开发人员可以无需将过多精力花费在超级账本体系架构本身,从而能够专注于应用逻辑的编写上去。
本文写作过程中,得到了同事Aviva的大力帮助,在此感谢。
更多阅读 Hyperledger Fabric on SAP Cloud Platform 300行ABAP代码实现一个最简单的区块链原型
要获取更多Jerry的原创文章,请关注公众号"汪子熙":
「深度学习福利」大神带你进阶工程师,立即查看>>>
今天的文章来自Wen Aviva, 坐Jerry面对面的程序媛。
Jerry在之前的公众号文章《 在SAP UI中使用纯JavaScript显示产品主数据的3D模型视图 》已经介绍过Aviva了,SAP成都C4C开发团队中其他同事评价她为:“ 美腻与智慧的化身 ”,“ 云时代女王 ”,“ 是大家前沿技术的引路人 ”。因为Jerry和Aviva就在一个组,所以我的看法是,这些评价都实至名归。
比如Jerry了解到的Javascript 3D渲染,增强现实( A rgument R eality)和这篇文章谈到的Hyperledger Fabric, 全部都是从Aviva那里学到的。
SAP成都研究院的每位同事,只要是参加了2017年岁末年会扫福字领红包的活动,则理论上都使用了Aviva和成都另一位程序媛Zhao Rina开发的基于AR的小应用。
2017年7月初成都C4C开发团队刚刚创建,除了老大Max之外,只有5位组员: 哈公子,大卫哥,象老师,勇哥和阿爽 。当时这支新的开发团队面临的最紧迫问题,就是赢得C4C美国开发总部的信任,从而从总部揽活到成都本地来做。用什么获得信任呢?对程序猿来说,当然是talk is cheap, show me the code。当时这支刚刚组建起来的五人小团队对C4C毫不了解,但是却选择了一个中国客户呼声非常高,非常希望能够添加到C4C标准产品去的backlog。短短一个月时间,这个五人小团队完成了从现学C4C产品知识和前后台开发知识,到将backlog实现成一个原型的全过程。当原型录成的视频给美国开发老大过目之后,得到了极高的评价,惊叹这只团队从创建到productive只花了短短一个月的时间。这个原型的顺利完成,为成都C4C团队后续的发展壮大打下了一个坚实的基础。
这个原型最后的交付形式是iOS应用。当时五位同事都没有做过iOS平台上的开发,不过幸好我们有Aviva。Max从SAP成都数字创新空间租借了Aviva。在她的帮助下,原型发布顺利完成。更令人敬佩的是,Aviva将她的iOS开发经验无私地分享给了团队其他同事,现在C4C团队已经有多位同事能够在iOS平台上进行工作。我想,今年三月成都C4C团队参加编程马拉松时,在组队阶段给队伍取名为“ Hi Aviva! ”, 或许是想通过这种方式感谢Aviva对C4C团队做出的贡献。
Jerry很庆幸每天可以和这样的同事一起工作。
下面是Aviva的正文。
什么是区块链?简单来说区块链就是一个分布式的记账本,或者分布式的数据库。
区块链的数据结构是一个链表,交易数据被存储到链表的区块中,区块链的第一个区块叫创世区块,除了创世块以外,每个区块还包含前一个区块的哈希指针,这个哈希指针的值是根据前一个区块的实际数据计算出来的。哈希指针指向前一个区块,后面的区块可以查找前面所有区块的信息。
账本的数据结构就是这样的一个链表,那么分布式的含义是什么呢?
区块链的众多参与者组成了一个松散自治的P2P网络,我们把区块链网络的参与者叫做节点,每个节点都拥有一个账本拷贝,所有账本的信息都是一致的,在区块链里没有中心节点。每当有新的交易进来,所有节点的账本都会更新,并且最终保持一致。更新的方式不是去修改某个区块的值,而是保存交易记录。比如在比特币系统中,它没有用户资产记录这样的概念,不像普通数据库那样用一条数据存储资产,比特币用户资产的值是通过把所有的交易记录串联聚合后得到的,账户里资产的来源可以一直向上追溯,直到创世块为止。区块链里的交易数据根据具体场景,可以是任何需要记录的信息。
智能合约
为了支持信息的持续更新,以及对账本进行管理(写入交易,进行查询等),区块链网络引入了 智能合约 来实现对账本的访问和控制。智能合约不仅仅可用于在区块链网络中打包信息,它们也可以被用于自动的执行由参与者定义的特定交易操作。
比如智能合约可以规定物流中的运输费用,根据物流的快慢收取不同的费用,根据货物的到达时间进行自动转账等。上传到区块链网络中的的智能合约会被打包到某一个区块中,因此智能合约一旦写入区块链,也是不可更改的。
共识机制
区块链网络中交易信息同步的过程,确保交易只有获得适当参与者批准后才更新,所有的参与者都会将同样的信息按照同样的顺序更新,这样的过程叫做共识。共识机制是区块链的核心之一。
区块链的第一个应用 比特币 ,采用的是Proof of Work(工作量证明)的共识机制。简单介绍一下比特币的共识机制,算法的具体细节大家可以去查白皮书。节点收到一个交易后,会根据判断标准对该交易进行有效性校验,无效的交易会被废弃。通过有效性验证之后的交易将会被广播给其他节点。其他节点会做同样的独立校验,当有效的交易达到整个网络所有节点时,即全网达成了“ 该交易有效 ”的共识。每个节点都会收到很多有效但是还未被打包到区块中的交易,这些交易被组装成Merkle Tree,Merkle Tree的第一个交易比较特殊,叫做coinbase,由节点自己创建,将挖矿奖励支付到矿工自己的地址。挖矿奖励包括新创建的比特币和打包进该区块所有交易的手续费总额。然后节点计算一个符合难度的哈希值,挖矿就是通过修改参数不断计算区块哈希值,直至达到难度要求,也就间接证明了该节点付出了对应的工作量,这就是工作量证明。Jerry的公众号文章《 300行ABAP代码实现一个最简单的区块链原型 》里用了一个ABAP方法CL_ABAP_MESSAGE_DIGEST=>CALCULATE_HASH_FOR_CHAR来计算区块的哈希值。
当节点计算出一个符合难度的区块哈希时,即说明该矿工挖矿成功了,该节点将该区块组装到本地的区块链,同时也将此区块广播给其他节点。其他节点接收到该区块后会验证该区块是否有效,有可能有两个节点同时挖出了新的区块B1和B2,它们的上一个区块都是同一个区块P。有的节点可能会先收到B1,有的会先收到B2,这时区块链出现了暂时性的两个分叉。要打破这种局面,要看下一个区块是基于B1生成还是基于B2生成。如果基于B1,B1这条链就变成了最长链,其他包含B2的节点会重新选择最长链,而B2作为孤块被丢弃掉。
到目前为止,我们可以将区块链看做是一个共享的,去中心化的多备份系统,通过智能合约更新交易数据,同时借助共识的协作流程使网络中所有的节点保持一致。
这里的交易可以指代任何数据,例如:数字货币,合同,记录或者其它任何信息。
区块链的类型 公有链:网络中的节点可以任意接入,网络中数据读写权限不受限制,所有节点都参与共识过程。比特币,以太坊等数字货币都属于公有链。 私有链:网络中的节点被一个组织控制,由其独享该区块链的写入权限,私有链和其他的分布式存储没有太大区别。 联盟链:多个公司或组织通过授权接入,由某些节点参与共识过程。Hyperledger Fabric属于联盟链。
什么是Hyperledger Fabric?
Hyperledger Fabric 是Linux基金会发起的Hyperledger项目之一。Hyperledger Fabric 专为在企业环境中使用而设计的开源的基于区块链的分布式账本。Hyperledger Fabric可用于全球供应链管理、金融交易、资产记账、人力资源、保险、健康和数字音乐等领域。
Hyperledger Fabric中的账本子系统(ledger)包括两个组件:**世界观( world state)和 事务日志(**transaction log)。世界观记录了账本在特定时间点的现状,是一个键值数据库。交易日志记录产生世界状态当前值的所有交易,是世界观的更新历史。账本的世界观的底层数据库可以更换,可以选择使用levelDB或couchDB。
Hyperledger Fabric是第一个支持以通用语言编写智能合约的区块链平台,可以使用java,nodejs和go语言来编写智能合约。Hyperledger Fabric中的智能合约也叫链码(chain code)。
和其他公有区块链平台最大的不同,Hyperledger Fabric 是私有的并且需要授权才能接入,它拥有一个**MSP(**Membership Service Provider)模块专门提供成员管理服务。
CA(Certificate Authority)负责权限管理,成员身份相关证书管理(Enrollment CertificateAuthority)和维护交易相关证书管理(Transaction Certificate Authority)等等。
Hyperledger Fabric提供了建立channel的功能,这允许参与者为交易新建一个单独的账本。当网络中的一些参与者是竞争对手时,这个功能变得尤为重要。因为这些参与者并不希望所有的交易信息——比如提供给部分客户的特定价格信息——都对网络中所有参与者公开。只有在同一个channel中的参与者,才会拥有该channel中的账本,而其他不在此channel中的参与者则看不到这个账本。
Hyperledger Fabric使用独立的排序节点(order)来提供共识服务,负责排序交易,提供全局确认的交易顺序。
应用程序通过SDK访问Hyperledger Fabric。
最新版Hyperledger Fabric的设计中,根据功能将节点角色解耦开,让不同节点处理不同类型的工作负载。从业务逻辑上又将节点分为背书节点(Endorser)和提交节点(Committer)。 Endorser peer:负责对来自客户端的交易进行合法性和权限检查(模拟交易),通 过检查则签名并返回结果给客户端。 Committer peer:负责维护账本,将达成一致顺序的批量交易结果进行状态检查,生成区块,执行合法的交易,并写入账本,同一个物理节点可以同时担任endorser和committer两个角色。
Hyperledger Fabric 交易流程:共识
共识流程主要分Proposal,Packaging和Validation三个阶段。
Proposal
应用提交一个交易proposal,然后将其提交给所有的背书节点,后者接到后,将其作为输入执行链码生成相应的交易proposal响应。此时并不会更新Ledger,而是对交易proposal 响应签名,并将其返回给应用。应用收到签名后的响应,共识流程的第一阶段就完成了。
Packaging
这个阶段是order节点对交易进行排序打包。Order节点从各个应用接收交易proposal响应,然后对这些交易进行排序,排序之后打包成区块。
「深度学习福利」大神带你进阶工程师,立即查看>>>
1
摘要
以太坊智能合约语言Solitidy是一种面向对象的语言,本文结合面向对象语言的特性,讲清楚Solitidy语言的多态(Polymorphism)(重写,重载),继承(Inheritance)等特性。
2
合约说明
Solidity 合约类似于面向对象语言中的类。合约中有用于数据持久化的状态变量,和可以修改状态变量的函数。 调用另一个合约实例的函数时,会执行一个 EVM 函数调用,这个操作会切换执行时的上下文,这样,前一个合约的状态变量就不能访问了。
面向对象(Object Oriented,OO)语言有3大特性:封装,继承,多态,Solidity语言也具有着3中特性。
面向对象语言3大特性的说明解释如下: 封装(Encapsulation)
封装,就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。一个类就是一个封装了数据以及操作这些数据的代码的逻辑实体。在一个对象内部,某些代码或某些数据可以是私有的,不能被外界访问。通过这种方式,对象对内部数据提供了不同级别的保护,以防止程序中无关的部分意外的改变或错误的使用了对象的私有部分。 继承(Inheritance)
继承,指可以让某个类型的对象获得另一个类型的对象的属性的方法。它支持按级分类的概念。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。 通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”。继承的过程,就是从一般到特殊的过程。要实现继承,可以通过 “继承”(Inheritance)和“组合”(Composition)来实现。继承概念的实现方式有二类:实现继承与接口继承。实现继承是指直接使用 基类的属性和方法而无需额外编码的能力;接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力。 多态(Polymorphism)
多态,是指一个类实例的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。
另外也解释一下重载和重写。
重载(Override)是多态的一种形式,是一个类的内部,方法中多个参数,根据入参的个数不同,会返回不同的结果。
重写(Overwrited),是子类继承父类,重写父类的方法。多态性是允许你将父对象设置成为一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。多态性在Object Pascal和C++中都是通过虚函数的。
3
函数重载(Override)
合约可以具有多个不同参数的同名函数。这也适用于继承函数。以下示例展示了合约 A 中的重载函数 f。 pragma solidity ^0.4.16; contract A { function f(uint _in) public pure returns (uint out) { out = 1; } function f(uint _in, bytes32 _key) public pure returns (uint out) { out = 2; } }
重载函数也存在于外部接口中。如果两个外部可见函数仅区别于 Solidity 内的类型而不是它们的外部类型则会导致错误。 // 以下代码无法编译 pragma solidity ^0.4.16; contract A { function f(B _in) public pure returns (B out) { out = _in; } function f(address _in) public pure returns (address out) { out = _in; } } contract B { }
以上两个 f 函数重载都接受了 ABI 的地址类型,虽然它们在 Solidity 中被认为是不同的。
3.1 重载解析和参数匹配
通过将当前范围内的函数声明与函数调用中提供的参数相匹配,可以选择重载函数。 如果所有参数都可以隐式地转换为预期类型,则选择函数作为重载候选项。如果一个候选都没有,解析失败。 pragma solidity ^0.4.16; contract A { function f(uint8 _in) public pure returns (uint8 out) { out = _in; } function f(uint256 _in) public pure returns (uint256 out) { out = _in; } }
调用 f(50) 会导致类型错误,因为 50 既可以被隐式转换为 uint8 也可以被隐式转换为 uint256。 另一方面,调用 f(256) 则会解析为 f(uint256) 重载,因为 256 不能隐式转换为 uint8。 注解:返回参数不作为重载解析的依据。
4
继承
通过复制包括多态的代码,Solidity 支持多重继承。
所有的函数调用都是虚拟的,这意味着最远的派生函数会被调用,除非明确给出合约名称。
当一个合约从多个合约继承时,在区块链上只有一个合约被创建,所有基类合约的代码被复制到创建的合约中。
总的来说,Solidity 的继承系统与 Python的继承系统 ,非常 相似,特别是多重继承方面。
下面的例子进行了详细的说明。 pragma solidity ^0.4.16; contract owned { function owned() { owner = msg.sender;} address owner; } // 使用 is 从另一个合约派生。派生合约可以访问所有非私有成员,包括内部函数和状态变量, // 但无法通过 this 来外部访问。 contract mortal is owned { function kill() { if (msg.sender == owner) selfdestruct(owner); } } // 这些抽象合约仅用于给编译器提供接口。 // 注意函数没有函数体。// 如果一个合约没有实现所有函数,则只能用作接口。 contract Config { function lookup(uint id) public returns (address adr); } contract NameReg { function register(bytes32 name) public; function unregister() public; } // 可以多重继承。请注意,owned 也是 mortal 的基类, // 但只有一个 owned 实例(就像 C++ 中的虚拟继承)。 contract named is owned, mortal { function named(bytes32 name) { Config config = Config(0xD5f9D8D94886E70b06E474c3fB14Fd43E2f23970); NameReg(config.lookup(1)).register(name); } // 函数可以被另一个具有相同名称和相同数量/类型输入的函数重载。 // 如果重载函数有不同类型的输出参数,会导致错误。 // 本地和基于消息的函数调用都会考虑这些重载。 function kill() public { if (msg.sender == owner) { Config config = Config(0xD5f9D8D94886E70b06E474c3fB14Fd43E2f23970); NameReg(config.lookup(1)).unregister(); // 仍然可以调用特定的重载函数。 mortal.kill(); } } } // 如果构造函数接受参数, // 则需要在声明(合约的构造函数)时提供, // 或在派生合约的构造函数位置以修饰器调用风格提供(见下文)。 contract PriceFeed is owned, mortal, named("GoldFeed") { function updateInfo(uint newInfo) public { if (msg.sender == owner) info = newInfo; } function get() public view returns(uint r) { return info; } uint info; }
注意,在上边的代码中,我们调用 mortal.kill() 来“转发”销毁请求。 这样做法是有问题的,在下面的例子中可以看到: pragma solidity ^0.4.0; contract owned { function owned() public { owner = msg.sender;} address owner; } contract mortal is owned { function kill() public { if (msg.sender == owner) selfdestruct(owner); } } contract Base1 is mortal { function kill() public { /* 清除操作 1 */ mortal.kill(); } } contract Base2 is mortal { function kill() public { /* 清除操作 2 */ mortal.kill(); } } contract Final is Base1, Base2 { }
调用 Final.kill() 时会调用最远的派生重载函数 Base2.kill,但是会绕过 Base1.kill, 主要是因为它甚至都不知道 Base1 的存在。解决这个问题的方法是使用 super: pragma solidity ^0.4.0; contract owned { function owned() public { owner = msg.sender; } address owner; } contract mortal is owned { function kill() public { if (msg.sender == owner) selfdestruct(owner); } } contract Base1 is mortal { function kill() public { /* 清除操作 1 */ super.kill(); } } contract Base2 is mortal { function kill() public { /* 清除操作 2 */ super.kill(); } } contract Final is Base1, Base2 { }
如果 Base2 调用 super 的函数,它不会简单在其基类合约上调用该函数。 相反,它在最终的继承关系图谱的下一个基类合约中调用这个函数,所以它会调用 Base1.kill() (注意最终的继承序列是——从最远派生合约开始:Final, Base2, Base1, mortal, ownerd)。 在类中使用 super 调用的实际函数在当前类的上下文中是未知的,尽管它的类型是已知的。 这与普通的虚拟方法查找类似。
4.1 基类构造函数的参数
派生合约需要提供基类构造函数需要的所有参数。这可以通过两种方式来完成: pragma solidity ^0.4.0; contract Base { uint x; function Base(uint _x) public { x = _x; } } contract Derived is Base(7) { function Derived(uint _y) Base(_y * _y) public { } }
一种方法直接在继承列表中调用基类构造函数(is Base(7))。 另一种方法是像 修饰器modifier 使用方法一样, 作为派生合约构造函数定义头的一部分,(Base(_y * _y))。 如果构造函数参数是常量并且定义或描述了合约的行为,使用第一种方法比较方便。 如果基类构造函数的参数依赖于派生合约,那么必须使用第二种方法。 如果像这个简单的例子一样,两个地方都用到了,优先使用 修饰器modifier 风格的参数。
4.2 多重继承与线性化
编程语言实现多重继承需要解决几个问题。 一个问题是 钻石问题。 Solidity 借鉴了 Python 的方式并且使用“ C3 线性化 ”强制一个由基类构成的 DAG(有向无环图)保持一个特定的顺序。 这最终反映为我们所希望的唯一化的结果,但也使某些继承方式变为无效。尤其是,基类在 is 后面的顺序很重要。 在下面的代码中,Solidity 会给出“ Linearization of inheritance graph impossible ”这样的错误。 // 以下代码编译出错 pragma solidity ^0.4.0; contract X {} contract A is X {} contract C is A, X {}
代码编译出错的原因是 C 要求 X 重写 A (因为定义的顺序是 A, X ), 但是 A 本身要求重写 X,无法解决这种冲突。
可以通过一个简单的规则来记忆: 以从“最接近的基类”(most base-like)到“最远的继承”(most derived)的顺序来指定所有的基类。
4.3 继承有相同名字的不同类型成员
当继承导致一个合约具有相同名字的函数和 修饰器modifier 时,这会被认为是一个错误。 当事件和 修饰器modifier 同名,或者函数和事件同名时,同样会被认为是一个错误。 有一种例外情况,状态变量的 getter 可以覆盖一个 public 函数。 本文作者:HiBlock区块链社区技术布道者辉哥
原文发布于简书
以下是我们的社区介绍,欢迎各种合作、交流、学习:)
「深度学习福利」大神带你进阶工程师,立即查看>>>
Virtual Box的默认安装是不包含Guest Addition这个扩展的,在实际使用过程中带来种种不便,比如只能通过小窗口访问虚拟机的操作系统,通过默认的右Ctrl切换鼠标,不能和宿主操作系统共享文件等等。
这些弊端在安装了Guest Additions扩展程序后能得到完美解决。
Guest Additions,故名思议,需要在Guest即虚拟机操作系统里安装。
在VirtualBox的官网下载VBoxGuestAdditions.iso这个镜像文件,
http://download.virtualbox.org/virtualbox/5.0.16/
然后将保存在宿主操作系统本地的iso文件挂接到虚拟机操作修通的光驱里:
我的虚拟机操作系统是Ubuntu,新建一个文件夹/mnt/cdrom:
然后使用命令行sudo mount /dev/cdrom /mnt/cdrom将光驱挂接到目录/mnt/cdrom去:
然后进入/mnt/cdrom, 就能看到镜像文件VBoxGuestAdditions.iso里的内容了:
执行脚本文件./VBoxLinuxAdditions.run:
稍后收到提示: Running kernel modules will not be replaced until the system is restarted. 这说明Guest Additions已经在虚拟机操作系统Ubuntu里安装成功,重启虚拟机即生效。
要获取更多Jerry的原创技术文章,请关注公众号"汪子熙"或者扫描下面二维码:
「深度学习福利」大神带你进阶工程师,立即查看>>>
如果你曾上过 BlockExplorer 观察自己的比特币收入状况,你是否曾经被搞的一头雾水呢?这正是因为比特币所使用的交易模型并非我们直觉上以账户为基础的,而是一种叫做UTXO的模型 。在我的前一篇文章:《深入了解NEX:Neon Exchange》中,也提到了比特币所使用UTXO模型与乙太坊使用的账户模型在功能上的一些差异,但究竟这两个模型到底差在哪儿?
ETH与账户模型
以太坊所使用的账户模型比较容易理解,就好像我们每个人都拥有一个银行帐户一样。在以太坊的世界中,每个地址就像是一个帐户,每一次的扣款,交易过后,都会将帐户的余额纪录在区块链当中。因此在认证交易时只要检查帐户是否有足够的余额就可以了。这个方法简单,直观,较利于智能合约的开发。如果你曾经上过Etherscan观察你的交易纪录,也会发现一切都简单易懂输入你的交易ID之后你会看到这种画面:
简单的从A到B,这只要看得懂英文应该就可以理解了。
比特币与UTXO模型
UTXO全名是 Unspent Transaction Outputs ,未花费交易输出,相比于账户模型来说没那么直观。
在比特币的世界里,并没有一个纪录所有帐户余额的帐本。那么要怎么确定一个地址现在有多少余额呢?简单的说,你要回顾以前所有的交易,并且找到所有寄给你的比特币,再把他们全都加起来,才会知道。
交易中的输入与输出
比特币中的一笔「交易」也较为复杂。假设今天,Fred给了Alice 2个BTC,Ted给了Alice 3个BTC,我们把这两笔寄给Alice,总和为5的BTC称为 Unspent Transaction Outputs 即未花费交易输出:也就是说现在Alice拥有了两笔Unspent Transcation Outputs,可以当作他未来转钱给别人的 input 。
如果现在Alice想要转5 BTC给Bob,他要将前面两笔总和刚好为5的UTXO当作这笔交易的输入。而矿工要验证的就是并没有其他交易在先前的区块当中,已经使用过这笔 Unspent Output 。如果同一笔输出已经被发送过,那它就不是 Unspent 了,这就是比特币预防 Double Spending 的方法。
还有一个条件就是, output 跟 input 总数要吻合。实际上在交易的时候,并不可能刚刚好总是找到两笔加起来等于你要转出金额的 output ,就好像上图中,如果爱丽丝Alice只想转4.5个BTC给鲍勃Bob,那么他就要多加一栏的 output ,把多出来的0.5个BTC转给自己,这样的交易才是平衡的。
我们可以实际来看看比特币的交易长什么样子,我们现在如果想要观察BlockExplorer上自己的交易纪录,会发现它长的是这付德性:
一笔交易包含了大量的 input 与 output ,这很有可能是一笔交易所转出金额的纪录,所以含有很多的 output 。而左边的 input 则可能是大量转入金额交易所钱包的交易 output 。
有趣的是,我们实际上在一笔交易之中无法「确定」真正的交易金额。例如下面这一笔纪录中,右边包含了三个 output ,我们无法确定究竟0.2,0.03以及56.38三个 output 究竟哪一个才是真正的目的地。搞不好Alice只有一笔 Unspent Transaction Output 未花费交易输出56.61 BTC,因此他在这笔交易中虽然他只想要转0.2BTC,却必须要动用他唯一一笔UTXO,而剩下的56.38再转回给自己。
当然,现在的比特币钱包已经帮我们照顾这些事情了,所以在使用的时候就好像银行帐户一样,我们只要输出目的地址,钱包就会帮我们找出合适的未花费输出(UTXO)当作输入来完成交易 。但如果你很闲,或是要干一些不想让你知道的事,就可以自己来打包奇怪的输入输出来增加匿名性。
UTXO的优势与劣势
UTXO因为没有帐户的存在,因此容许平行进行多笔交易。假如你有许多的UTXOs,你可以同时进行多笔交易而不会被阻挡。再来就是匿名性,如上面提过得,你可以轻易的隐藏自己的交易目的。除此之外,UTXO也被认为比较安全且有效率,可以透过Simple Payment Verification(SPV)来快速验证检验交易。
但UTXO最大的缺点就在于他是 Stateless 无状态的,这对于在其上开发应用程序非常的不利。就像有名的Qtum虽然底子是UTXO的交易模式,但是仍然会设计 Account Abstraction Layer 账户抽象层来让应用程序的开发变得容易。
小结
现在区块链应用开发当道,UTXO倾向被大家视为一种只能简单处理交易的模型,我觉得一定程度上算是时代的产物吧!毕竟离比特币的发明也已经十年了,尽管有一些特性是无可取代,但是大家仍是偏好朝向Account Model或是混合式的架构前进。
但不论怎么说,比特币永远都是区块链世界的老大!而且现在大家免不了还是要用到BTC交易,所以我们还是有必要了解UTXO运作方式的!
总之,希望这篇文章可以对大家对比特币有深一点的理解啦!如果喜欢我的文章,可以按照我@antonsteemit,我会努力产出一些区块链相关的文章。
建议你浏览我们汇智网的各种编程语言的区块链教程和区块链技术博客,深入了解区块链,比特币,加密货币,以太坊,和智能合约。 java比特币开发教程 ,本课程面向初学者,内容即涵盖比特币的核心概念,例如区块链存储、去中心化共识机制、密钥与脚本、交易与UTXO等,同时也详细讲解如何在Java代码中集成比特币支持功能,例如创建地址、管理钱包、构造裸交易等,是Java工程师不可多得的比特币开发学习课程。 php比特币开发教程 ,本课程面向初学者,内容即涵盖比特币的核心概念,例如区块链存储、去中心化共识机制、密钥与脚本、交易与UTXO等,同时也详细讲解如何在Php代码中集成比特币支持功能,例如创建地址、管理钱包、构造裸交易等,是Php工程师不可多得的比特币开发学习课程。 php以太坊 ,主要是介绍使用php进行智能合约开发交互,进行账号创建、交易、转账、代币开发以及过滤器和交易等内容。 java以太坊开发教程 ,主要是针对java和android程序员进行区块链以太坊开发的web3j详解。 以太坊入门教程 ,主要介绍智能合约与dapp应用开发,适合入门。 以太坊开发进阶教程 ,主要是介绍使用node.js、mongodb、区块链、ipfs实现去中心化电商DApp实战,适合进阶。 python以太坊 ,主要是针对python工程师使用web3.py进行区块链以太坊开发的详解。 C#以太坊 ,主要讲解如何使用C#开发基于.Net的以太坊应用,包括账户管理、状态与交易、智能合约开发与交互、过滤器和交易等。 EOS入门教程 ,本课程帮助你快速入门EOS区块链去中心化应用的开发,内容涵盖EOS工具链、账户与钱包、发行代币、智能合约开发与部署、使用代码与智能合约交互等核心知识点,最后综合运用各知识点完成一个便签DApp的开发。
汇智网原创翻译,转载请标明出处。这里是 原文
「深度学习福利」大神带你进阶工程师,立即查看>>>
比原项目仓库:
Github地址: https://github.com/Bytom/bytom
Gitee地址: https://gitee.com/BytomBlockchain/bytom
国密算法是指国家密码管理局制定的自主可控的国产算法,包括一系列密码学算法:SM1、SM2、SM3、SM4、SM7、SM9、以及祖冲之算法。最常用的三种商用密码算法是 SM2椭圆曲线公钥密码算法、SM3密码杂凑算法以及 SM4分组密码算法。
其中,SM2 算法属于椭圆曲线公钥密码系统,相较于 RSA 公钥密码系统,这种新型的公钥密码系统拥有加解密速度更快,使用的密钥更短的优点。SM2算法密钥长度为192至256位长度的安全性就能达到 RSA 算法2048至4096位密钥长度的安全要求。SM2的优异性能取决于求解椭圆曲线离散对数问题的困难性。对于一般椭圆曲线的离散对数问题,目前只存在指数级计算复杂度的求解方法,与大数分解问题及有限域上离散对数问题相比,椭圆曲线离散对数问题的求解难度要大得多。因此,在相同安全程度要求下,椭圆曲线密码较其它公钥密码所需的密钥规模要小得多。SM2数字签名算法适用于商用密码应用中的数字签名和验证,可满足多种密码应用中的身份鉴别和数据完整性、真实性的安全需求。在比原链主网中,交易的签名和验证使用的是 Ed25519签名算法,而在国密测试网中,使用 SM2算法替代。
SM3密码杂凑算法是哈希算法的一种,适用于商用密码应用中的数字签名和验证、消息认证码的生成与验证以及随机数的生成,可以满足多种密码应用的安全需求。在比原链主网中,在获取交易和区块头等摘要的过程中使用的哈希算法是 SHA3算法,而在国密测试网中,使用 SM3算法替代。
SM4分组密码算法是一种对称加密算法,使用同一个密钥对信息进行加密和解密。在比原链主网中,对用户的钱包进行加解密使用的是 AES-128算法,而在国密测试网中,使用 SM4算法替代。
2014年国务院办公厅就颁发了《国务院办公厅转发密码局等部门关于金融领域密码应用指导意见》,该意见就指出在我国涉及到金融领域信息安全的产品和系统要自主可控,到2020年实现国产密码在金融领域中的全面应用。而实际上,我国的金融信息安全产品的国产化率已经大幅度提前达到目标。在金融领域使用国产加密标准是机构走向合规化的重要一步。
比原链作为一种原子资产的交互协议,其宗旨是连通原子世界与比特世界,促进资产在两个世界间的交互和流转。为了完成这个目标,在国密测试网上使用国密密码学加密标准不仅仅是保障资产安全的重要措施,也是比原链满足政策要求的重要举措。
开发者体验国密测试网方式:
下载国密测试网源码: $ git clone ne https://github.com/bytom/bytom-gm.git $GO $GOPATH/src/rc/github.com/bytom-gm
安装: $ cd $GOPATH/src/rc/github.com/bytom-gm $ m $ make install
初次启动需要配置: $ bytomd init --chain_id --home
其中,可以选择 gm-testnet 或者 solonet 。 gm-testnet 启动的是国密测试网。 solonet 启动的是单节点网络。
指定的是数据存放的目录。
启动节点: $ bytomd node --mining --home
开发者获取国密网测试币的方式可以在启动节点时开启 --mining 选项。
国密测试网的操作体验与主网类似,但是主网的地址前缀为 bm ,而国密测试网的地址前缀为 gm 。
目前,比原链正在按照原有计划执行,技术开发每周都发布一个稳定的迭代版本。目前已经发布了7个迭代版本,而社区运营也在有条不紊的进行,政策合规化也在积极与相关机构洽谈。可以说,比原链的项目进展伴随着国密测试网的发布更上一层楼。
「深度学习福利」大神带你进阶工程师,立即查看>>>
1
摘要
以太坊智能合约语言Solitidy是一种面向对象的语言,本文结合面向对象语言的特性,讲清楚Solitidy语言的多态(Polymorphism)(重写,重载),继承(Inheritance)等特性。
2
合约说明
Solidity 合约类似于面向对象语言中的类。合约中有用于数据持久化的状态变量,和可以修改状态变量的函数。 调用另一个合约实例的函数时,会执行一个 EVM 函数调用,这个操作会切换执行时的上下文,这样,前一个合约的状态变量就不能访问了。
面向对象(Object Oriented,OO)语言有3大特性:封装,继承,多态,Solidity语言也具有着3中特性。
面向对象语言3大特性的说明解释如下: 封装(Encapsulation)
封装,就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。一个类就是一个封装了数据以及操作这些数据的代码的逻辑实体。在一个对象内部,某些代码或某些数据可以是私有的,不能被外界访问。通过这种方式,对象对内部数据提供了不同级别的保护,以防止程序中无关的部分意外的改变或错误的使用了对象的私有部分。 继承(Inheritance)
继承,指可以让某个类型的对象获得另一个类型的对象的属性的方法。它支持按级分类的概念。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。 通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”。继承的过程,就是从一般到特殊的过程。要实现继承,可以通过 “继承”(Inheritance)和“组合”(Composition)来实现。继承概念的实现方式有二类:实现继承与接口继承。实现继承是指直接使用 基类的属性和方法而无需额外编码的能力;接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力。 多态(Polymorphism)
多态,是指一个类实例的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。
另外也解释一下重载和重写。
重载(Override)是多态的一种形式,是一个类的内部,方法中多个参数,根据入参的个数不同,会返回不同的结果。
重写(Overwrited),是子类继承父类,重写父类的方法。多态性是允许你将父对象设置成为一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。多态性在Object Pascal和C++中都是通过虚函数的。
3
函数重载(Override)
合约可以具有多个不同参数的同名函数。这也适用于继承函数。以下示例展示了合约 A 中的重载函数 f。 pragma solidity ^0.4.16; contract A { function f(uint _in) public pure returns (uint out) { out = 1; } function f(uint _in, bytes32 _key) public pure returns (uint out) { out = 2; } }
重载函数也存在于外部接口中。如果两个外部可见函数仅区别于 Solidity 内的类型而不是它们的外部类型则会导致错误。 // 以下代码无法编译 pragma solidity ^0.4.16; contract A { function f(B _in) public pure returns (B out) { out = _in; } function f(address _in) public pure returns (address out) { out = _in; } } contract B { }
以上两个 f 函数重载都接受了 ABI 的地址类型,虽然它们在 Solidity 中被认为是不同的。
3.1 重载解析和参数匹配
通过将当前范围内的函数声明与函数调用中提供的参数相匹配,可以选择重载函数。 如果所有参数都可以隐式地转换为预期类型,则选择函数作为重载候选项。如果一个候选都没有,解析失败。 pragma solidity ^0.4.16; contract A { function f(uint8 _in) public pure returns (uint8 out) { out = _in; } function f(uint256 _in) public pure returns (uint256 out) { out = _in; } }
调用 f(50) 会导致类型错误,因为 50 既可以被隐式转换为 uint8 也可以被隐式转换为 uint256。 另一方面,调用 f(256) 则会解析为 f(uint256) 重载,因为 256 不能隐式转换为 uint8。 注解:返回参数不作为重载解析的依据。
4
继承
通过复制包括多态的代码,Solidity 支持多重继承。
所有的函数调用都是虚拟的,这意味着最远的派生函数会被调用,除非明确给出合约名称。
当一个合约从多个合约继承时,在区块链上只有一个合约被创建,所有基类合约的代码被复制到创建的合约中。
总的来说,Solidity 的继承系统与 Python的继承系统 ,非常 相似,特别是多重继承方面。
下面的例子进行了详细的说明。 pragma solidity ^0.4.16; contract owned { function owned() { owner = msg.sender;} address owner; } // 使用 is 从另一个合约派生。派生合约可以访问所有非私有成员,包括内部函数和状态变量, // 但无法通过 this 来外部访问。 contract mortal is owned { function kill() { if (msg.sender == owner) selfdestruct(owner); } } // 这些抽象合约仅用于给编译器提供接口。 // 注意函数没有函数体。// 如果一个合约没有实现所有函数,则只能用作接口。 contract Config { function lookup(uint id) public returns (address adr); } contract NameReg { function register(bytes32 name) public; function unregister() public; } // 可以多重继承。请注意,owned 也是 mortal 的基类, // 但只有一个 owned 实例(就像 C++ 中的虚拟继承)。 contract named is owned, mortal { function named(bytes32 name) { Config config = Config(0xD5f9D8D94886E70b06E474c3fB14Fd43E2f23970); NameReg(config.lookup(1)).register(name); } // 函数可以被另一个具有相同名称和相同数量/类型输入的函数重载。 // 如果重载函数有不同类型的输出参数,会导致错误。 // 本地和基于消息的函数调用都会考虑这些重载。 function kill() public { if (msg.sender == owner) { Config config = Config(0xD5f9D8D94886E70b06E474c3fB14Fd43E2f23970); NameReg(config.lookup(1)).unregister(); // 仍然可以调用特定的重载函数。 mortal.kill(); } } } // 如果构造函数接受参数, // 则需要在声明(合约的构造函数)时提供, // 或在派生合约的构造函数位置以修饰器调用风格提供(见下文)。 contract PriceFeed is owned, mortal, named("GoldFeed") { function updateInfo(uint newInfo) public { if (msg.sender == owner) info = newInfo; } function get() public view returns(uint r) { return info; } uint info; }
注意,在上边的代码中,我们调用 mortal.kill() 来“转发”销毁请求。 这样做法是有问题的,在下面的例子中可以看到: pragma solidity ^0.4.0; contract owned { function owned() public { owner = msg.sender;} address owner; } contract mortal is owned { function kill() public { if (msg.sender == owner) selfdestruct(owner); } } contract Base1 is mortal { function kill() public { /* 清除操作 1 */ mortal.kill(); } } contract Base2 is mortal { function kill() public { /* 清除操作 2 */ mortal.kill(); } } contract Final is Base1, Base2 { }
调用 Final.kill() 时会调用最远的派生重载函数 Base2.kill,但是会绕过 Base1.kill, 主要是因为它甚至都不知道 Base1 的存在。解决这个问题的方法是使用 super: pragma solidity ^0.4.0; contract owned { function owned() public { owner = msg.sender; } address owner; } contract mortal is owned { function kill() public { if (msg.sender == owner) selfdestruct(owner); } } contract Base1 is mortal { function kill() public { /* 清除操作 1 */ super.kill(); } } contract Base2 is mortal { function kill() public { /* 清除操作 2 */ super.kill(); } } contract Final is Base1, Base2 { }
如果 Base2 调用 super 的函数,它不会简单在其基类合约上调用该函数。 相反,它在最终的继承关系图谱的下一个基类合约中调用这个函数,所以它会调用 Base1.kill() (注意最终的继承序列是——从最远派生合约开始:Final, Base2, Base1, mortal, ownerd)。 在类中使用 super 调用的实际函数在当前类的上下文中是未知的,尽管它的类型是已知的。 这与普通的虚拟方法查找类似。
4.1 基类构造函数的参数
派生合约需要提供基类构造函数需要的所有参数。这可以通过两种方式来完成: pragma solidity ^0.4.0; contract Base { uint x; function Base(uint _x) public { x = _x; } } contract Derived is Base(7) { function Derived(uint _y) Base(_y * _y) public { } }
一种方法直接在继承列表中调用基类构造函数(is Base(7))。 另一种方法是像 修饰器modifier 使用方法一样, 作为派生合约构造函数定义头的一部分,(Base(_y * _y))。 如果构造函数参数是常量并且定义或描述了合约的行为,使用第一种方法比较方便。 如果基类构造函数的参数依赖于派生合约,那么必须使用第二种方法。 如果像这个简单的例子一样,两个地方都用到了,优先使用 修饰器modifier 风格的参数。
4.2 多重继承与线性化
编程语言实现多重继承需要解决几个问题。 一个问题是 钻石问题。 Solidity 借鉴了 Python 的方式并且使用“ C3 线性化 ”强制一个由基类构成的 DAG(有向无环图)保持一个特定的顺序。 这最终反映为我们所希望的唯一化的结果,但也使某些继承方式变为无效。尤其是,基类在 is 后面的顺序很重要。 在下面的代码中,Solidity 会给出“ Linearization of inheritance graph impossible ”这样的错误。 // 以下代码编译出错 pragma solidity ^0.4.0; contract X {} contract A is X {} contract C is A, X {}
代码编译出错的原因是 C 要求 X 重写 A (因为定义的顺序是 A, X ), 但是 A 本身要求重写 X,无法解决这种冲突。
可以通过一个简单的规则来记忆: 以从“最接近的基类”(most base-like)到“最远的继承”(most derived)的顺序来指定所有的基类。
4.3 继承有相同名字的不同类型成员
当继承导致一个合约具有相同名字的函数和 修饰器modifier 时,这会被认为是一个错误。 当事件和 修饰器modifier 同名,或者函数和事件同名时,同样会被认为是一个错误。 有一种例外情况,状态变量的 getter 可以覆盖一个 public 函数。 本文作者:HiBlock区块链社区技术布道者辉哥
原文发布于简书
以下是我们的社区介绍,欢迎各种合作、交流、学习:)
「深度学习福利」大神带你进阶工程师,立即查看>>>
这一系列文章将围绕以太坊的二层扩容框架,介绍其基本运行原理,具体操作细节,安全性讨论以及未来研究方向等。本篇文章主要对 Plasma 一些关键操作的细节进行剖析。
在 上一篇文章中 我们已经理解了什么是 Plasma 框架以及它是如何运行的,这一篇文章将对其运行过程中的一些关键部分,包括 Plasma 提交区块的过程,当有恶意行为发生时如何构建防伪证明以及如何退出 Plasma 子链等进行剖析。需要注意的是,由于 Plasma 是一套框架,因此本文只剖析 Plasma 项目的共性,每一部分的实现细则还是需要参考实际的项目,例如 Plasma MVP(Minimal-Viable-Plasma)和 Plasma Cash 等。
1
存款(Deposit)
Plasma 的主要思想就是将大部分计算过程都转移到链下进行,用户只有在进入和退出 Plasma Chain 的时候需要跟主链上的智能合约交互,这也是所有 Plasma 应用的标准流程。
用户在将主链的资产(如以太币或者其它 ERC20 合约发布的 token)转移到 Plasma Chain 的过程称为存款(Deposit),具体做法是直接向主链上的 Plasma 合约发送以太币或 token。Plasma 合约收到 Deposit 交易后会在子链上创建跟 Deposit 数额一致的交易,并将其打包进区块中,作为存款确认的证明。这个过程如下图所示(来源自[1])。
当用户看到子链上自己之前存款的交易被确认后,就可以在子链上使用这笔资产(给子链上的其他用户发送交易或者退出子链等)。
2
状态确认(State Commitment)
当大部分都转移到链下进行时,需要某种机制确保链下状态的更新得到确认,这样才能保证当有恶意行为发生时,主链可以保证用户不会受到损失。这就是为什么需要状态确认(State Commitment),即子链周期性地将状态更新情况提交到主链进行共识。
然而,将子链中的所有交易都同步到主链显然违反了 Plasma 的初衷,在 Plasma 中,实际向主链提交的是 Merkle Tree 的根哈希。因此子链中的实际交易情况被隐藏,在主链上只能看到子链区块的哈希值。
当有恶意行为发生时,子链网络中的所有用户都可以向主链提交防伪证明,证明成立后,含有恶意交易的区块将被回滚。
3
防伪证明(Fraud Proof)
Plasma 的一个关键设计之一就是允许用户构造防伪证明(Fraud Proof)。防伪证明的意义在于只要发布区块的节点构造了含有恶意交易的区块,那么就要承担被惩罚的风险。每当新的区块被提交到主链上时,会留出一段时间给用户提交防伪证明,如果在这段时间内没有证明被提交,则认为新的区块被验证合法。如果有防伪证明检测到区块中存在恶意交易,则该区块将被舍弃,回滚到上一个被验证合法的区块。Plasma 中的防伪证明主要有以下(但不限于)几种: 资产可花费证明 交易签名有效性证明 存取款证明
至于每种防伪证明的具体形式,则依赖于实际 Plasma 应用的实现细则。
如下图所示(来源自[1]),子链中每个节点都存有 1-4 个区块的数据。假设区块 1-3 已经被验证合法,而区块 4 中存在恶意交易,那么每个节点都可以使用 1-4 个区块中的数据构造防伪证明提交到主链,主链验证后将子链中的状态回滚到区块 1-3。
防伪证明还可以使用零知识证明(zk-SNARKs 或者 STARKs)来构造,但由于目前通过零知识证明生成证明的时间和空间还有待优化,目前设计的 Plasma 并不依赖零知识证明。零知识证明在 Plasma 中的应用是一个很有前景的研究方向,感兴趣的读者可以参考以太坊研究团队关于这方面的研究[2])。
4
取款(Withdrawal)
取款(Withdrawal),顾名思义,就是从子链中的资产取回到主链上,因此取款也被称为退出(Exit)。取款操作可以说是 Plasma 框架中最重要的一步,因为它确保用户可以安全地将子链上的资产转移到主链上。之前的存款以及状态确认步骤已经产生了一些交易数据,并在主链上得到同步,用户可以利用这些数据构造资产证明,之后执行简单取款(Simple Withdrawal)操作退出子链。当有扣留(Withholding)攻击发生(即子链上的矿工恶意扣留区块,意图双花攻击等)时,用户可能无法成功获取数据构造资产证明,这时需要执行批量取款(Mass Withdrawal)操作退出子链。
需要注意的是,当子链中有取款操作发生时,跟这个取款操作相关的账号或者交易都将被禁止。
简单取款(Simple Withdrawal)
执行简单取款的条件是所要取回的资产已经在主链和子链上确认。
一个简单取款的执行主要有以下几个步骤: 向主链上的 Plasma 智能合约发送已签名的取款交易。取款的数额可以包含多个输出(UTXO模型),但所有输出必须在同一个子链当中,而且每个输出的余额必须全部取出,不能只取出一部分。取款数额的一部分还需要被当作押金,作为恶意行为的惩罚。 当取款请求发送后,需要等待一段“争议期(Challenge Period)”,这期间其它节点可以构造证据证明该取款中的部分或全部数额已经被花费。如果争议期内有节点提供证明成功,那么取款被取消,而且押金被扣除。 接下来可能还要等待一段时间,直到所有区块高度较低的取款操作都完成。这是为了保证所有取款操作按照“先来后到”的顺序执行。 当争议期结束后,如果没有争议被提出,则认为取款操作成立,取款者将子链资产成功取回到主链。
快速取款(Fast Withdrawal)
快速取款(Fast Withdrawal)跟简单取款相比的差别主要是引入一个中间人,白皮书上称为 Liquidity Provider,这里简称为 LP。如果一个用户不想等待很长的争议期(目前的实现至少要一周),那么它可以选择从 LP 这里直接取款,只需要消耗一个交易确认的时间,代价是需要支付给 LP 一定的费用。由于 Plasma 白皮书上关于快速取款的描述太过晦涩,这里主要参考 kfichter 提出的 Simple Fast Withdrawal[3] 来介绍快速取款是如何实现的。
为了实现快速取款,取款方和 LP 可以利用一个流动合约(liquidity contract)。假设取款方是 Alice,她想要执行快速取款将 10 以太币从子链转移到主链。她首先向流动合约发送 10 以太币,注意这里的交易是在子链上进行的。当这个交易被子链打包成区块后,Alice 可以调用合约中的某个退出函数,这时 Alice 将获取一个代表她这笔资产的 token。Bob 作为 LP,他检查了子链上数据之后证明 Alice 的取款没有问题之后愿意以 9 以太币的价格购买这个 token。Alice 将 token 卖给 Bob,获得了 9 以太币,Bob 赚取了 1 以太币。
需要注意的是,实现快速取款的前提条件是没有拜占庭行为发生,即没有扣留区块攻击发生,因为 LP 需要验证取款方的交易历史。
批量取款(Mass Withdrawal)
当子链中有拜占庭行为(例如,区块扣留攻击)发生时,将会影响以后生成防伪证明,因此网络中的每个用户都有责任快速退出子链。虽然批量取款(Mass Withdrawal)操作不是必要选择,但当大量用户执行取款时很可能会造成主链拥塞,也会消耗更多的 gas,因此批量取款是当子链受到攻击时更好的选择。
批量取款操作由于所采用的模型(UTXO 模型或者账户模型)不同会有较大的差别,而且目前关于批量取款的操作细节也正在研讨当中,因此这里只对批量取款做简单介绍,想要了解目前研究状态可以参考[4]。
当子链中有拜占庭行为发生时,用户之间可以共同协作执行批量取款。这时会有一个节点扮演取款处理人(Exit Processor)的角色,简称为 EP,负责当前某个批量操作(可以同时有多个批量取款操作发生,但同一个取款申请不能存在于多个批量取款),并且可以收取服务费作为报酬。EP 将构造一个位图(bitmap,即一串0/1)记录哪些资产要执行取款。之后 EP 将利用现有的区块数据检查每个取款是否合法,之后将构造一个批量退出初始化交易(Mass Exit Initiation Transaction,MEIT),并将其发送到主链上。在 MEIT 被主链确认之前,每个用户都可以对这个交易提出异议。当争议期结束,MEIT 被主链确认,批量取款成功。
5
总结
本文主要对 Plasma 框架中一些关键操作进行了比较详细的介绍,但如果不依托于某个实际的 Plasma 项目,对一些细节还是很难理解。因此在后面的文章中将会介绍 Plasma MVP 以及 Plasma Cash。
6
相关资源
相关资源 https://plasma.io/ https://ethresear.ch/t/plasma-is-plasma/2195 https://ethresear.ch/t/simple-fast-withdrawals/2128 https://ethresear.ch/t/basic-mass-exits-for-plasma-mvp/3316 内容来源:知乎 原文作者:盖盖
「深度学习福利」大神带你进阶工程师,立即查看>>>
9月11日,在由万向区块链实验室举办的“新经济·技术探索”第四届区块链全球峰会上,微众银行副行长兼首席信息官马智涛先生作为演讲嘉宾受邀出席本次会议,带来了题为《联盟链的升华——公众联盟链》的演讲, 提出新的概念“公众联盟链”,认为联盟链也可以服务于联盟成员之外的公众 。
马智涛提出,从联盟链概念推出市场的时候,引起了很多争论。他对于联盟链和公有链技术上谁强谁弱未做评判,而是提出了微众银行不断思考和摸索的几个问题:
1、公有链是否为“公众所有”?
公有链非常强调去中心化的理念,以及属于公有资产,并不归属于某个个体、某个企业。但从实际运行情况来看,几条主要的公链像比特币、以太坊、EOS,它们的算力基本上还是集中在几个大矿池或机构手上。所以公有链是否真正为“公众所有”,这个问题值得思考。
2、公有链是否真正在服务“普罗大众”?
最新的全球人口数据是76亿,有上网习惯的个人有40亿。而参与全球公有链的人数大约只有2000万,这是区块链从业机构基于比特币和以太坊钱包的数量估算出来的。马智涛提出,目前真正使用了公有链提供的服务的群体,还是非常少。
3、公有链能否承载“数字社会”使命?
根据IDC的数据统计,2017年全球数据总量大约是230亿TB。微众银行的股东腾讯也在运行对外的云服务,它们可承载的数据规模大概是480万TB。而公有链的代表以太坊,目前能承载的数据量还不足1TB。从承载的数据量来看,公有链离真正能够承载“数字社会”使命的要求,还是有一定的距离的。
4、信任是否只能通过算法来建立?
区块链强调通过算法来做数据的隐私保护、信任的建立,但算法是否是唯一建立信任的手段呢?马智涛提出,人类社会经过了多年的演变进化,已经有很多人类历史验证积累下来的现成的信任机制。比如:可以依赖政府的信用,包括在全国各地建立起来的法律体系和监管体系等,可通过发牌照给一些可信机构,让他们经营一些高敏感、高风险的业务;可以通过资产抵押实现征信;在技术层面,也有很多标准组织来制定技术标准。微众银行非常认可算法可以增加信任,但它不是唯一建立信任的手段,还是应该看看怎么让算法去结合社会上已有的信任机制,共同完善信任体系。
5、联盟链是否只能服务联盟成员?
现在所有的企业,都会在互联网上面向外部提供服务。马智涛认为,联盟链的参与机构,在组成联盟的同时,同样可以通过互联网面向公众提供服务,不见得联盟链只能服务联盟成员。
基于对以上五个问题的思考,马智涛总结下来,认为联盟链的进化升华,应该能够演变成为一个面向公众提供服务的生态,称之为“公众联盟链“。它并不是单一的链条,而是一种新的基于区块链商业应用所打造的一种生态圈,它有如下几个非常重要的使命。
第一,服务公众 。公众作为链的使用者,可以通过公开网络访问商业联盟所组成的联盟链提供的服务。
第二,联盟链有一套治理机制,由联盟成员去共治的。 联盟链的属主以及运营方,是联盟本身,通过这个链去实现信息以及价值的交换。
第三,分布式商业。 通过公众联盟链的体系,可以大力提倡政企机构联合,提供对外服务,去提升机构间的协同效率,以及提升公众体验、降低公众成本和风险。所以,我们认为公众联盟链,英文称之为Open Consortium Chain,应该是区块链生态圈中不可忽略的,应该有更多关注和投入的领域。
公众联盟链对于技术底层的要求,也有需要加强的几个方面:
第一,公众联盟链并不是单一链条,所以整个体系下面需要能够支持多链条并行,以及跨链条通信,同时能够支撑来自互联网海量交易的能力。
第二,真正能够让大家快速组成联盟,能够低成本、高效率地建立联盟链,这也是重点。也是公众联盟链要加强的力量。
第三,开源开放,公众联盟链一定离不开开源基础。
马智涛指出,任何的科技体系,除了技术底层以外,还有更重要的一点就是业务的基础服务,有了这些业务服务基础能力,业务发展、商业应用才能够蓬勃起来:
联盟治理: 既然有联盟,就需要有一套机制去管理好这些联盟成员,谁能够加入,谁违背了联盟章程可能要退出。
数据治理: 联盟成员共建的数据,怎么做授权、怎么做隐私保护。
身份管理: 在智能设备的陆续发展之下,会有越来越多需要管理的物,需要放在这个体系当中,所以身份管理也会变得越来越重要。
事件管理: 越来越多智能设备会随时随地产生很多事件。这些事件通过区块链,也可以驱动很多联盟成员之间的互动。
清结算管理: 公众联盟链作为一个很重要的金融底层基础设施,清结算也是必不可少的环节。
微众银行构想的未来公众联盟链生态圈是:会有不同的联盟所组成的联盟链条,它们之间会有很大程度的相互协同,通过跨链的通讯机制,通过互联网,各类服务被呈现给终端消费者。
马智涛还指出,目前微众银行正在努力打磨开源区块链底层平台BCOS 和 FISCO BCOS,更好地支持了各行各业包括在存证、仲裁、机构间对账、供应链金融、物业管理、旅游金融、版权交易、人才招聘、游戏等等领域的应用出台,也正在联合金链盟发起一个区块链应用大赛,去支持更多的创业者、企业,能够参与到公众联盟链的生态当中。
最后,马智涛总结道:“微众银行坚信分布式商业肯定是人类经济的发展模式必会走向的方向,而公众联盟链很有可能是打开分布式商业模式这道大门的钥匙。”
「深度学习福利」大神带你进阶工程师,立即查看>>>
从github上clone EOS的时候速度很慢,尝试了hosts设置,postbuffer设置,等各种手段后还是很慢,又懒得走代理,选择走码云的方式,速度很不错,步骤如下:
1、登陆github,把 https://github.com/EOSIO/eos Fork过来;
2、登陆码云,右上角消息图标旁有个加号,鼠标过去下拉框中选择从GitHub导入项目,出现GitHub上自有的项目列表,找到EOS点击导入;
3、在码云自己的项目列表中找到EOS,拷贝地址,就可以从这里git clone了,速度在1M以上。
「深度学习福利」大神带你进阶工程师,立即查看>>>
我在使用springboot时,当代码有问题时,发现控制台打印下面信息: Connected to the target VM, address: '127.0.0.1:42091', transport: 'socket' log4j:WARN No appenders could be found for logger (org.springframework.boot.devtools.settings.DevToolsSettings). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. . ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.0.6.RELEASE) 2018-10-25 10:10:21.425 INFO 102158 --- [ restartedMain] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2018-10-25 10:10:21.427 INFO 102158 --- [ restartedMain] org.apache.catalina.core.StandardEngine : Starting Servlet Engine: Apache Tomcat/8.5.34 2018-10-25 10:10:21.444 INFO 102158 --- [ost-startStop-1] o.a.catalina.core.AprLifecycleListener : The APR based Apache Tomcat Native library which allows optimal performance in production environments was not found on the java.library.path: [/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib] 2018-10-25 10:10:21.590 INFO 102158 --- [ost-startStop-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2018-10-25 10:10:24.522 INFO 102158 --- [ restartedMain] o.apache.catalina.core.StandardService : Stopping service [Tomcat] Disconnected from the target VM, address: '127.0.0.1:42091', transport: 'socket' Process finished with exit code 0
WTF?没有错误信息怎么解决问题? 各种搜索,总之就是代码有问题,自己检查把...
好吧,直接debug把
内嵌tomcat的入口类是 org.apache.catalina.core.StandardService
//TODO 后面补上过程
最终找到 org.springframework.context.support.AbstractApplicationContext 定位方法 refresh() if (logger.isWarnEnabled()) { logger.warn("Exception encountered during context initialization - " + "cancelling refresh attempt: " + ex); }
debug可以正常进入,然后就看到我们希望看到的 ex了 org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'fabricApiController': Injection of resource dependencies failed; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'fabricTemplate': Injection of resource dependencies failed; nested exception is org.springframework.boot.context.properties.ConfigurationPropertiesBindException: Error creating bean with name 'fabricConfiguration': Could not bind properties to 'FabricConfiguration' : prefix=blockchain, ignoreInvalidFields=false, ignoreUnknownFields=true; nested exception is org.springframework.boot.context.properties.bind.BindException: Failed to bind properties under 'blockchain.channel-peers' to java.util.List
问题发现了,解决自己代码问题,然后重新启动,正常! 万事大吉?错,这才开始 上面我们简单解决了问题,但是根源没有解决! 要说解决方案把当前流行的日志体系简单说一遍 下面整理的来源网络: 常见的日志框架,注意不是具体解决方案 1 Commons-logging: apache 最早提供的日志的门面接口。避免和具体的日志方案直接耦合。类似于JDBC的api接口,具体的的JDBC driver实现由各数据库提供商实现。通过统一接口解耦,不过其内部也实现了一些简单日志方案 2 Slf4j: 全称为Simple Logging Facade for JAVA:java简单日志门面。是对不同日志框架提供的一个门面封装。可以在部署的时候不修改任何配置即可接入一种日志实现方案。和commons-loging应该有一样的初衷。 常见的日志实现: log4j logback jdk-logging 详细优缺点不是本文重点,请自行搜索。
接着分析上面的问题,Commons-logging 是tomcat默认的日志系统(apache自家东西得支持),具体的日志实现,根据系统已存在日志系统选择。 简单列举以下log的实现: org.apache.commons.logging.Log | org.apache.commons.logging.impl.SimpleLog org.apache.commons.logging.impl.NoOpLog org.apache.commons.logging.impl.Log4JLogger org.apache.commons.logging.impl.SLF4JLog org.apache.commons.logging.impl.Jdk14Logger
springboot 默认使用的是logback日志实现,问题就出现在这里了!!!common-logs并没有logback的实现!
根据maven依赖,我们看到log4j和logback的包都被引入了,然后tomcat之能选择的是log4j,springboot使用的是logback。 log4j和logback只见缺少一个桥梁,正是缺少的这个桥梁,导致springboot只能输出logback!!!
中间的桥梁就是下面这个依赖 org.slf4j jcl-over-slf4j
这个依赖可以将log4j输出到slf4j,从而从sl4j输出。
总结: 总结一下,已经搞明白是slf4j/common-logs <> log4j和logback的恩怨情仇
第一种解决方式:根据日志定位问题,然后采用加法处理,增加jcl-over-slf4j,打通slf4j和common-logs通道
第二种解决方式:解决冲突,一山不容二虎,排除掉slf4j,common-logs任意一方,spring使用slf4j,那可以排除调common-logs
从项目优化的角度看,第二种更优,可以减少不必要的依赖。
如果日志出现问题,那就是日志体系发生冲突了,可以参考这个思路,处理项目中日志异常问题。 「深度学习福利」大神带你进阶工程师,立即查看>>>
1
上海区块链马拉松成功结赛
10月19日-21日,由天钥(Tenzorum)团队,bitfwd 社区,HiBlock 以及 Blockchain Brother 合作组织的上海区块链马拉松,在黄浦区 P2 联合创业办公社成功举办。来自世界各地的50名开发者分成9支队伍参与了这次活动。经过48小时的竞赛,以及项目成果路演角逐。最终野狼队、9527队以及逸境队,分获本次比赛的前三名。天钥团队很开心看到这样一批开发者,与我们同样关心区块链技术发展,并为区块链生态系统带来了很多价值。希望这样的活动越来越多,天钥团队期待下次与大家相见。
2
TENZ-ID 中文文档发布
天钥的技术团队在上海区块链黑客马拉松上展示了 TENZ-ID 的软件开发工具包(SDK: Software Development Kit) 。区块链开发者可以通过接入 SDK 的方式, 将 TENZ-ID 轻松融入到程序之中,为用户提供更好的使用体验。 目前中文文档也已经被推送到 GitHub 上的开源代码库中啦~
如果你的团队也想接入 TENZ - ID 开发项目,先来看看我们准备的快速入门吧:
https://github.com/Tenzorum/ens-subdomain-factory/blob/master/TENZ-ID-QUICKSTART-CN.md
下周,天钥团队将马不停蹄地前往捷克首都布拉格参加 #cryptolife hackathon,并出席以太坊第四次开发者大会 (DEVCON 4)。更多精彩,敬请期待~
扩展阅读: Blockathon(2018)上海竞赛项目成果今天揭晓
Blockathon上海|年纪最小且是唯一一支女子团队率先获得投资人青睐与加持
「深度学习福利」大神带你进阶工程师,立即查看>>>
10月19-21日,Blockathon2018(上海)在黄浦区P2联合创业办公社举办,这是Blockathon2018在中国区的第三场区块链黑客马拉松竞赛。本次活动由Bitfwd技术社区、HiBlock区块链社区和区块链兄弟联合主办, 获得了来自NEM、澳中理事会、离子链、Olympus Labs、HPB芯链、Tenzorum等的赞助支持,P2联合创业办公社提供场地支持,以太坊爱好者社区、掘金、活动行、it大咖说、飞马网、机械工业出版社华章分社、登链学院等15家合作伙伴以及世链财经、共享财经、铱科技、陀螺财经等20家媒体对活动给予宣传支持。
Blockathon是全球性的区块链开发者竞赛,48小时内,开发者自由组队进行现场开发,完成一个区块链项目的完整交付。Blockathon2018(上海)选拔出50名区块链爱好者组成9支队伍参赛,并邀请到20余位来自全球优秀项目的技术专家担任嘉宾评审,对项目进行指导与点评。值得一提的是,活动现场的女性参会者比例超过30%。
本次活动共产生了9个区块链项目,经过21日下午的路演评审环节,野狼队、9527队、逸境队获得了前三名,分别获得20000元、10000元及5000元等值XEM的竞赛奖金,其中使用Olympus协议开发的项目还额外获得OlympusLabs追加的奖金。现场年纪最小且是唯一一支女子团队,来自上海对外经贸大学的三个大二女生所做的 《数字钱包》项目直接获得投资人的青睐并获得项目启动投资。
在21日下午的项目路演环节,主办方邀请了10多位区块链技术专家级嘉宾担任项目评审,《白话区块链》作者蒋勇、Bitcoin SPV开发者喵叔、因特链ChainX创始人岳利鹏、区块链兄弟技术社区创始人冯翔、NEM中国地区负责人李世庚、铂链联合创始人& CTO王超、美国区块链媒体BTC Media亚太区CTO古千峰、火币区块链研究院 首席区块链分析师朱翊邦、Olympus协议核心开发者Orange、众为资本Venture Partner周欣华、 265 Ventures 创始合伙人刘桐彤、一百亿研究所创始人v女神、LongHash 区块链孵化器中东地区负责人王琴文、M Phase Consulting 联合创始人Queenie、NEM马来西亚Technical Trainer Anthony Law、TENZORUM项目CTO Radek Ostrowski等技术专家对参赛项目给予专业的建议与指导。
与前两站相比,Blockathon2018(上海)更加体现开放、分享的软件学习精神,在整个比赛过程中,注重推动区块链技术发展的探讨与分享,让更多区块链爱好者通过这场比赛了解区块链、认识区块链技术。
10月19日开幕式,HiBlock区块链社区合伙人王登辉担任主持人,介绍整体活动,澳洲bitfwd开发者社区创始人Daniel、HiBlock区块链社区创始人Bob和区块链兄弟联合发起人方天叶对Blockathon(2018)上海站的活动进行开幕致辞,澳大利亚驻沪领事馆商务处商务领事 Dane Richmond表达了对活动的支持,他认为中澳的友好关系在这些活动中都能得到体现和发展。随后,NEM中国地区负责人李世庚、离子链联合创始人方天叶、Olympus协议核心开发者Orange分别介绍对各自代表的项目作了简单介绍,鼓励大家采用本项目的协议及技术,并介绍了活动期间在现场担任导师的技术专家,导师全程陪伴为参赛者提供技术支持与指导。
10月20日上午,主办方开放了以“降低区块链应用使用门槛”为主题的开发培训活动,由OlympusLabs、Tenzorum及NEM三个优秀区块链开发团队的核心开发者从各自经验分享如何降低区块链Dapp在大众应用时的技术门槛。同时在10月21日的项目路演环节,邀请60余位观众到场观看路演并进行交流,从现场开发的项目中了解区块链,探讨区块链技术的落地应用思路。
通过48小时的活动,50名参赛者共计产生了9个参赛项目,分别是:
1、Asset Trust 数字资产生态平台(第一名)
Asset Trust通过NEM公链开发,解决数字资产的防伪交易,实现无缝上链。该项目以艺术品交易作为案例,通过Asset Trust 数字资产生态平台可以看到艺术品创作过程中的视频,将成品和过程视频上传IPFS实现数字资产防伪。
2、NFTS 基金(第二名)
该项目通过Olympus协议实现以ERC20代币为投资标的的投资基金基金,相对于传统金融市场的基金,NFTS 的优势在于用户对基金的申购和赎回操作都是通过智能合约自动执行,结算价格由智能合约根据用户发起申请的当前价格自动结算,且没有额度限制。
另外,由于基金合约的地址是公开的,用户可以通过合约地址方便地查看到基金经理的所有操作记录,能够对基金和基金经理的市场表现有更加准确和及时地判断。
github地址: https://github.com/longduer/olympus-protocol.git
3、基于NEM链的汽车机油溯源项目(第三名)
针对我国机油市场中假机油泛滥的问题,“NEM区块链溯源汽车机油项目”致力于帮助品牌机油厂商解决对机油进行跟踪、防伪和打假的各种难题。项目通过运用区块链的不可篡改技术、物联网的实时跟踪技术和链上数据分析等技术,实施了一整套方案。通过对供应链各个环节物流数据的上链、物联网对机油状态的实时数据上链和信誉值末尾淘汰等机制保证了数据溯源过程中的真实性,可有效地对供应链流通环节中的每个节点实施真实监控,让汽车机油供应流程的溯源成为可能,提高市场正品占有率,从而维护厂商、经销商和消费者等各个环节的利益。
4、校园数字钱包(现场获得投资)
参赛作品《数字钱包》创意的提出,一方面,是由于现行校园一卡通经常存在丢失、被盗刷以及消磁等各种问题;另一方面,和学校对接的第三方支付机构(支付宝和微信),并没有办法保障学生个人消费数据的安全。
基于区块链技术,首先,数字钱包中附有个人专属二维码,可以进行学生身份的确认和消费,将校园卡从实物形式转变成虚拟形式;其次,通过在校内进行分布式记账,把各学生的数据匿名化打包,再交给银行,这就避免了我们直接向第三方平台直接提供个人消费记录。
5、智能资产 X 区块链
结合智能合约NFT协议和Tenzorum提供的API接口,将智能资产记录在区块链上,具有资产交易记录不可更改、追踪快捷可靠、资产数据完全透明、减少书面手续以及中间商、智能合约确保交易安全便捷等优点。
6、Searchlight@ 供应链云管理平台
Searchlight@ 供应链云管理平台是以NEM区块链为底链基础的云网络平台,致力于为汽车供应商、维修商和用户提供来自整个供应链生态系统的数据,以实现更高的零配件可追溯性、增加透明度并提高产业链整体效率。项目基于区块链链上信息不可篡改的根本属性,引入NEM区块链的智能资产模块,对供应链流程做多签传递,并结合配套的保险及认证机制,可有效地对供应链流通环节中的每个节点实施监控,让汽车零配件供应流程的溯源成为可能,从而实现整个供应链的成本精简和效率优化。
7、基于NEM的新闻平台项目
作为以NEM区块链为底链基础的云网络平台,致力于打破现有新闻媒体中心话模式,解决假新闻问题。采用NEM的message模块,将新闻内容和作者等信息上链。同时使用发布者交押金,奖励读者对新闻进行修正还原真相模式,对新闻真实性进行去中心化追溯和修正。
8、健身+区块链
项目简介: 健身作为一个未来行业趋势,越来越火!区块链可以帮助顾客更好的锻炼自己想要的身材,帮助教练更换的辅导锻炼计划!
基于Tenzorum提供的sdk服务,为顾客和教练设置唯一域名TENZ-ID,使用TSNN服务,统计顾客锻炼过程的心率,体型,体脂,体重。。等数据
TSNN很轻松的上传数据,减少顾客和教练的上传数据的gas成本,提高服务,建立信任。
9、鉴闻
项目介绍:让用户高效地获取真实有价值的信息,确保信息可追溯,可验证。同时,使新闻的客观性回归。采用通证经济设计,激励揭露真相和揭穿谣言的人,形成正向循环。同时,让越来越多的资源加入到社区中。
代码Github地址: https://github.com/xuyao91/jianwen
Blockathon区块链黑客马拉松(区块松)活动由澳洲技术社区Bitfwd发起,作为一场国际性的区块链技术活动,招募区块链技术爱好者现场组队、现场创意、现场开发、现场路演,通过活动诞生更多优秀的区块链项目创意。如有投资方有意向继续支持以上项目或Blockathon活动的举办,请加微信EF0815联系。下一站竞赛我们正在策划中,请保持关注。
扩展阅读: Blockathon(2018)上海竞赛项目成果今天揭晓
Blockathon上海|年纪最小且是唯一一支女子团队率先获得投资人青睐与加持
「深度学习福利」大神带你进阶工程师,立即查看>>>
今天我们来讲区块链扩容的另一个主流方案——侧链,侧链可作为解决区块链扩容难题的一种有效解决方案。有些人认为,从理论上说,这种解决方案可让所有人都满意。
基础概念
侧链协议本质上是一种跨区块链解决方案。通过这种解决方案,可以实现数字资产从第一个区块链到第二个区块链的转移,又可以在稍后的时间点从第二个区块链安全返回到第一个区块链。其中第一个区块链通常被称为主区块链或者主链,每二个区块链则被称为侧链。侧链协议被设想为一种允许数字资产在主链与侧链之间进行转移的方式,这种技术为开发区块链技术的新型应用和实验打开了一扇大门。02—产生背景
2012年,在比特币聊天室中,首次出现了关于侧链概念的相关讨论。当时比特币的核心开发团队正在考虑如何可以安全的升级比特币协议,以增加新的功能,但是直接在比特币区块链上进行功能添加比较危险,因为如果新功能在实践中发生软件故障,则会对现有的比特币网络造成严重影响。另外,由于比特币的网络结构特性,如果进行较大规模的改动,还需要获得多数比特币矿工的支持。这时,比特币核心开发者便提出了侧链方案。这种技术允许开发人员将新功能附加在其他的区块链,但是这些区块链仍然附着在现有比特币区块链上。这些区块链中新功能可以充分利用现有比特币的网络特性,而不会对现有的比特币网络造成危害。
通过侧链,可以在主链的基础上,进行交易隐私保护技术、智能合约等新功能的添加,这样可以让用户访问大量的新型服务,并且对现有主链的工作并不造成影响。另外,侧链也提供了一种更安全的协议升级方式,当侧链发生灾难性的问题时,主链依然安然无恙。03—实现方案
侧链实现的技术基础是双向锚定(Two-way Peg),通过双向锚定技术,可以实现暂时的将数字资产在主链中锁定,同时将等价的数字资产在侧链中释放,同样当等价的数字资产在侧链中被锁定的时候,主链的数字资产也可以被释放。双向锚定实现的最大难点是协议改造需兼容现有主链,也就是不能对现有主链的工作造成影响,其具体实现方式可以分为以下几类:
(一)单一托管模式
最简单的实现主链与侧链双向锚定的方法就是通过将数字资产发送到一个主链单一托管方(类似于交易所),当单一托管方收到相关信息后,就在侧链上激活相应数字资产。这个解决方案的最大问题是过于中心化。图1给出了以比特币为主链的单一托管模式的工作原理示意图:
(二)联盟模式
联盟模式是使用公证人联盟来取代单一的保管方,利用公证人联盟的多重签名对侧链的数字资产流动进行确认。在这种模式中,如果要想盗窃主链上冻结的数字资产就需要突破更多的机构,但是侧链安全仍然取决于公证人联盟的诚实度。图2给出了以比特币为主链的联盟模式的工作示意图:
单一托管模式与联盟模式的最大优点是它们不需要对现有的比特币协议进行任何的改变。
(三)SPV模式
SPV(Simplified Payment Verification)模式是最初的侧链白皮书《Enabling Blockchain Innovations with Pegged Sidechains》中的去中心化双向锚定技术最初设想。SPV是一种用于证明交易存在的方法,通过少量数据就可以验证某个特定区块中交易是否存在。在SPV模式中,用户在主链上将数字资产发送到主链的一个特殊的地址,这样做会锁定主链的数字资产,该输出仍然会被锁定在可能的竞争期间内,以确认相应的交易已经完成,随后会创建一个SPV证明并发送到侧链上。此刻,一个对应的带有SPV证明的交易会出现在侧链上,同时验证主链上的数字资产已经被锁住,然后就可以在侧链上打开具有相同价值的另一种数字资产。这种数字资产的使用和改变在稍后会被送回主链。当这种数字资产返回到主链上时,该过程会进行重复。它们被发送到侧链上锁定的输出中,在一定的等待时间后,就可以创建一个SPV证明,来将其发送回主区块链上,以解锁主链上的数字资产。SPV模式存在的问题是需要对主链进行软分叉。图3给出了以比特币主链的SPV模式的工作流程示意图:
(四)驱动链模式
驱动链概念是由Bitcoin Hivemind创始人Paul Sztorc提出的。在驱动链中,矿工作为‘算法代理监护人’,对侧链当前的状态进行检测。换句话说,矿工本质上就是资金托管方,驱动链将被锁定数字资产的监管权发放到数字资产矿工手上,并且允许矿工们投票何时解锁数字资产和将解锁的数字资产发送到何处。矿工观察侧链的状态,当他们收到来自侧链的要求时,他们会执行协调协议以确保他们对要求的真实性达成一致。诚实矿工在驱动链中的参与程度越高,整体系统安全性也就越大。如同SPV侧链一样,驱动链也需要对主链进行软分叉。图4给出了以比特币为主链的驱动链模式的工作流程示意图:
(五)混合模式
上述所有的模式都是对称的,而混合模式则是将上述获得双向锚定的方法进行有效的结合的模式。由于主链与侧链在实现机制存在本质的不同,所以对称的双向锚定模型可能是不够完善的。混合模式是在主链和侧链使用不同的解锁方法,例如在侧链上使用SPV模式,而在主链网络上则使用驱动链模式。同样,混合模式也需要对主链进行软分叉。
以下是我们的社区介绍,欢迎各种合作、交流、学习:)
「深度学习福利」大神带你进阶工程师,立即查看>>>
Go语言是谷歌2009发布的第二款开源编程语言。
Go语言专门针对多处理器系统应用程序的编程进行了优化,使用Go编译的程序可以媲美C或C++代码的速度,而且更加安全、支持并行进程。
北京时间2010年1月10日,Go语言摘得了TIOBE公布的2009年年度大奖。该奖项授予在2009年市场份额增长最多的编程语言。
2007年,谷歌把Go作为一个20%项目开始研发,即让员工抽出本职工作之外时间的20%, 投入在该项目上。除了派克外,该项目的成员还有其他谷歌工程师也参与研发。
本文介绍如何在ubuntu操作系统下面安装goLang。
首先用工具curl下载goLang的安装包:
sudo curl -O https://storage.googleapis.com/golang/go1.9.2.linux-amd64.tar.gz
然后将下载好的安装包,一个压缩文件通过tar解压。
sudo tar -xvf go1.9.2.linux-amd64.tar.gz
解压后,生成一个go目录。
用命令行mv将该目录移到目录/usr/local下:
将go目录下的bin文件夹加到ubuntu的环境变量里:
echo 'export PATH=$PATH:/usr/local/go/bin' >> ~/.profile
source ~/.profile
命令行go version显示版本,说明环境变量生效了。
用go语言实现一个计算阶乘的简单程序: package main import "fmt" func Factorial(n uint64)(result uint64) { if (n > 0) { result = n * Factorial(n-1) return result } return 1 } func main() { var i int = 15 fmt.Printf("func(%d): %d ", i, Factorial(uint64(i))) }
使用go build hello.go编译成可执行文件,然后./hello执行。
要获取更多Jerry的原创技术文章,请关注公众号"汪子熙"或者扫描下面二维码:
「深度学习福利」大神带你进阶工程师,立即查看>>>
1
摘要
恩金(Enjin)花了大半年的时间一直在完善ERC-1155这个通证协议,毫不夸张地说,该标准是现有以太坊上最适用于游戏资产的通证标准,将主流游戏中道具涉及到的一切操作经过高度抽象之后,基本通过ERC-1155进行了实现。本文分为两部分:区块链游戏的多重宇宙观和为游戏资产而生的Enjin钱包。欢迎细细品尝!
本文大部分内容翻译自Enjin的Medium频道中多篇文章,经过删减编辑成文,整篇文章为Enjin视角,不代表本平台观点和立场。
2
摘要
在理论物理中,多重宇宙是指存在无限多个宇宙,在这里“一切皆可能,可能即存在”。这些宇宙也被称之为“平行宇宙”。
把这个名词放在游戏中,是指玩家将可以在不同的游戏里使用“多重宇宙的道具”。理论上来说,玩家会在不同的平行游戏中,用同一个“多重宇宙道具”,但却以不同的形式发挥不同的作用。
注:在这里,所谓的“多重宇宙的道具”,也就是可以跨游戏使用的游戏资产,他可以是角色,可以是武器,也可以是各类物品。
这种游戏资产在多重宇宙中的跨域使用,完美地符合物理学家的平行宇宙理论。
在通常的假设中,如果你穿越到另一个平行世界的维度里,你会发现自己在这个世界里过着完全不同的生活,或是一个性格完全不同的人,甚至可能完全不存在。从基因学的角度据估计,我们每一个人存在的概率大约是10的2685000次方分之一。
太阳系坐落在银河的当前位置,地球演化成宜人居住的环境,有机物进化成人类,历史一页页翻开,你成为现在的你,这一切的一切如果再一次发生,概率上约等于不可能。
因此,当玩家进入不同的游戏世界时,多重宇宙中的角色和道具会发生改变也是合理的设定。 而我们期待这将成为游戏世界中冒险重要组成部分。
脱离了区块链,一个游戏中的多重宇宙是否能存在?
不能,绝壁不能。
为什么?
1. 有机增长
一个多重宇宙是一个无限的、一直在演变中的大环境,在这里一切皆有可能。
但由一个实体中心化掌控的多重宇宙不会是最终的解决方案,它一定会被各种原因所约束,而限制了多重宇宙真正的潜力。
构建一个具有多重宇宙雏形的游戏网络已经是一个超级宏大的工程,它需要协同合作的力量。通过撬动牛逼开发者的能力和脑洞,向不同的游戏方向去设计,是能够模拟出一个真正多重宇宙无限潜力的唯一方式。
利用我们的工具,游戏开发者将能够将他们的游戏接入多重宇宙,并且以最合适的方式整合进去。他们可以加入现有的多重宇宙,或者创建一个自己的。
我们的任务是开发一套去中心化的架构,方便开发者使用并开始上述工程。
我们怎么做? 铸造一套多重宇宙的道具,并分发给希望简单快速加入多重宇宙的开发者。我们将继续拓宽多重世界里的道具品类,直到成百种甚至上千种,他们将提供给希望加入多重宇宙的新开发者一个简单的接入点。 给开发者提供独占的多重宇宙道具,开发者可以重新设计道具的图片和游戏机制,来符合他们自己的游戏玩法。 把这些多重宇宙的道具给到真正有信仰的玩家手中
我们将先铸造一批稀有的道具,给到现有的游戏开发商参与者,他们来分发给合适的游戏玩家。
后续加入的开发者,也可以加入并且收到这些用来分发的游戏道具,不过他们需要提供文档说明这些道具在游戏中将如何使用,以及如何在游戏中来支撑这些道具的内在价值。
我们给多重宇宙的大规模落地设计了一条很清晰的路径,非常期待看到如滚雪球一般发展壮大,直到超出我们的预期。
2. 去中心化的监管
如果有人在今天创造了一个中心化的多重宇宙,等待它的将来要么是失败(就像过去有很多已经失败的例子),跟更先进的去中心化版本相比不值一提,要么就是落入独裁的大厂手里随意收割玩家。
大多数玩家都应该读过《头号玩家》这本书或者看过电影,这部科幻题材的作品里,哈利迪创造了一个游戏的多重宇宙——绿洲。哈利迪的死亡,最后引起了一场史诗般的战争,一边是希望去良性运营整个多重宇宙的玩家们,另一边则是企图垄断并利用这个世界赚快钱的组织——IOI。
在一个由Enjin代币驱动的多重宇宙世界观下,像《头号玩家》里面这样的灾难就不会发生,因为它仍是一个基于中心化管理的系统,弱势的群体往往被迫屈服于有权有势之徒。
历史已经多次证明,中心化的管理最终总逃脱不出人类最原始的动物本性。
这些本性是在远古时代恶劣的生存环境下和人类进化的过程中,与生俱来的。时过境迁,它们仍然深深的潜藏在我们的潜意识之中。这些本性让人类学会堂而皇之地伪装自己,使我们在做决策时往往是利己主义者。
没有人能够反抗本性。与本性斗争往往是困难的,而权势更能使人腐败——唯一的解决方案是尽可能地将权力平均化。
3. 安全性
在《头号玩家》中,每一个人都是在自己的家里,通过设备接入到多重宇宙进行游戏。所有的资产都是虚拟的,通过贩卖游戏道具的数十亿美金的公司在争夺整个网络的控制权。
先不去推测绿洲的GDP,来想想这里面可能发生的盗窃行为。
在现实世界,平均每一个虚拟道具被购买,就有7.9个道具被盗窃或诈骗。
对于《头号玩家》这么一个宏大的多重宇宙,如果使用现在这种过时的虚拟资产管理数据库,上面的盗窃数据看起来会是什么样子?
难以想象的糟糕。
区块链并不是解决所有的游戏安全问题的万灵药,但是更强的KYC、复杂的行为数据分析、透明的资产记录和安全的区块链钱包能帮助我们在正确的方向上迈出一大步。
多亏区块链,你真正拥有了自己的资产。不仅如此,你也有真正拥有了游戏中的每一步行动,以及随之发生的一系列结果。
3
第一批多重宇宙道具
我们来谈谈将来的电子资产,他们将会是第一批多重宇宙的道具。
下面你将看到的就是你会在Enjin钱包中看到的道具(如果你幸运的能拿到这些独一无二的资产)。
要知道游戏开发者们正在将这些游戏资产做进他们自己的游戏,而且是在不同的游戏世界,不同的设计风格。从一个游戏到另一个游戏,这些道具的用途和形式都会不一样。
这也就是多重宇宙的魅力所在—— 一切皆可能,可能即存在
锻造之锤
多重宇宙的破晓时分,5500泰坦巨人徒手铸造于混沌的遗忘之地。锻造之锤散落于五维时空,蕴藏着史诗级魔法属性,乃至高宝藏。
修正之剑
修正之剑诞生于龙界。单晶魂石点缀,魔法铭文印记。每一把剑,高雅大气,确是致命之器。数千载,未受侵蚀,剑锋依旧。
麦克(Mike)
“安格瑞姆 - 爆焰 三世,新卡特加特伯爵,泰坦神酒盗窃者”,通常被称为Mike,可能是整个多重宇宙最不幸的人。
以上三个多重宇宙游戏道具和角色,将全部会被整合到以下六个游戏中:Age of Rust, 9Lives Arena, CryptoFights, Forest Knight, Bitcoin HODLer, and Cats in Mechs。(DR注:Enjin在下面的几周,每周都会更新出几个多重宇宙道具或角色,以上是第一周的三个,在第二周也已经公布了两个,在此就不多赘述了。)
4
为游戏资产而生的Enjin钱包
Enjin钱包刚刚进行了一次大规模升级,新特性如下:
行业内最先支持ERC-1155标准
可以创建不限数量支持游戏藏品的钱包
⏩对游戏藏品的显示速度进行了最大程度的优化
原生支持ERC-721&ERC-1155协议
针对War of Crypto 提供ERC-1155的支持
针对Gods Unchained 提供ERC-721的支持
针对CryptoKitties 提供ERC-721的支持
全新的带有即时载入系统的导航菜单
对游戏元数据的支持(用户可以随时查看这些数据)
游戏内道具的交易记录(发送/接收/铸造)
浏览其他人钱包里游戏道具
✔️针对基于ERC-721的游戏的轻便整合
自行变换的稀有度主题系统
Enjin钱包已经支持了ERC-721和将来真正的游戏及收藏品标准 ERC-1155. 用户将可以安全地储存和管理自己Gods Unchained,War of Crypto 和 CryptoKitties这些区块链游戏中的资产。
5
“神奇的保险柜”
收集一些不同寻常又漂亮的物品这种欲望,是一种原始的需求。
这件事情的吸引力很有可能是来源于古代人类为了生存而历练的狩猎行为和收集能力。也就是说收集稀有物品的欲望其实已经深深地植入在我们的DNA之中。
古埃及托洛米王朝收集了全世界的书籍储藏在古亚力山大图书馆。文艺复兴时期梅第奇家族通过私人赞助来收集艺术品。
跟古亚历山大图书馆中的实体的印刷品被大火付之一炬所不同的是,你储存在Enjin钱包中的电子文物可以安全地免于自然灾难。
现在你可以将你的ERC-721和ERC-1155资产储存在一个“神奇的保险柜”里——由NSA级别多重加密、ARM编译器、RAM和硬件加密和防键盘记录器的输入键盘等安全技术所铸造。
现有的通证标准比如ERC-721最多只能用于基于网页的收藏类游戏,功能非常有限,而ERC-1155协议用了全新的方式定义了通证,使得游戏开发者能创造真正的收藏品和可交换的道具来支持更复杂的游戏机制,有更高的内在价值,并且可以被应用于主流游戏。
ERC-1155有着超级多的特性,玩家可以使用、交易、购买、升级、销毁、合成、租赁、抵押、加强以及溶解他们的游戏道具。
Enjin钱包将同样支持基于ERC-1155的多重宇宙道具——可以被用与多个游戏之中的史诗级游戏资产,由ENJ代币驱动来保证了他们的真实性并为价值做了背书。 文章来源公众号:DappReview
区块链马拉松|Blockathon(2018)上海站开放报名
北京blockathon回顾:
Blockathon(北京):48小时极客开发,区块松11个现场交付项目创意公开
成都blockathon回顾:
Blockathon2018(成都站)比赛落幕,留给我们这些区块链应用思考
「深度学习福利」大神带你进阶工程师,立即查看>>>
以太坊智能合约语言Solitidy是一种面向对象的语言,本文清楚合约定义,以及派生的抽象合约,接口,库的定义。
1
合约定义(Contract)
Solidity 合约类似于面向对象语言中的类。合约中有用于数据持久化的状态变量,和可以修改状态变量的函数。 调用另一个合约实例的函数时,会执行一个 EVM 函数调用,这个操作会切换执行时的上下文,这样,前一个合约的状态变量就不能访问了。
1.1 创建合约
可以通过以太坊交易“从外部”或从 Solidity 合约内部创建合约。
一些集成开发环境,例如 Remix, 通过使用一些用户界面元素使创建过程更加流畅。 在以太坊上编程创建合约最好使用 JavaScript API web3.js。 现在,我们已经有了一个叫做 web3.eth.Contract 的方法能够更容易的创建合约。
创建合约时,会执行一次构造函数(与合约同名的函数)。构造函数是可选的。只允许有一个构造函数,这意味着不支持重载。
在内部,构造函数参数在合约代码之后通过 ABI 编码 传递,但是如果你使用 web3.js 则不必关心这个问题。
如果一个合约想要创建另一个合约,那么创建者必须知晓被创建合约的源代码(和二进制代码)。 这意味着不可能循环创建依赖项。 pragma solidity ^0.4.16; contract OwnedToken { // TokenCreator 是如下定义的合约类型. // 不创建新合约的话,也可以引用它。 TokenCreator creator; address owner; bytes32 name; // 这是注册 creator 和设置名称的构造函数。 function OwnedToken(bytes32 _name) public { // 状态变量通过其名称访问,而不是通过例如 this.owner 的方式访问。 // 这也适用于函数,特别是在构造函数中,你只能像这样(“内部地”)调用它们, // 因为合约本身还不存在。 owner = msg.sender; // 从 `address` 到 `TokenCreator` ,是做显式的类型转换 // 并且假定调用合约的类型是 TokenCreator,没有真正的方法来检查这一点。 creator = TokenCreator(msg.sender); name = _name; } function changeName(bytes32 newName) public { // 只有 creator (即创建当前合约的合约)能够更改名称 —— 因为合约是隐式转换为地址的, // 所以这里的比较是可行的。 if (msg.sender == address(creator)) name = newName; } function transfer(address newOwner) public { // 只有当前所有者才能发送 token。 if (msg.sender != owner) return; // 我们也想询问 creator 是否可以发送。 // 请注意,这里调用了一个下面定义的合约中的函数。 // 如果调用失败(比如,由于 gas 不足),会立即停止执行。 if (creator.isTokenTransferOK(owner, newOwner)) owner = newOwner; } } contract TokenCreator { function createToken(bytes32 name) public returns (OwnedToken tokenAddress) { // 创建一个新的 Token 合约并且返回它的地址。 // 从 JavaScript 方面来说,返回类型是简单的 `address` 类型,因为 // 这是在 ABI 中可用的最接近的类型。 return new OwnedToken(name); } function changeName(OwnedToken tokenAddress, bytes32 name) public { // 同样,`tokenAddress` 的外部类型也是 `address` 。 tokenAddress.changeName(name); } function isTokenTransferOK(address currentOwner, address newOwner) public view returns (bool ok) { // 检查一些任意的情况。 address tokenAddress = msg.sender; return (keccak256(newOwner) & 0xff) == (bytes20(tokenAddress) & 0xff); } }
2
抽象合约(Abstract Contract)
合约函数可以缺少实现,如下例所示(请注意函数声明头由 ; 结尾): pragma solidity ^0.4.0; contract Feline { function utterance() public returns (bytes32); }
这些合约无法成功编译(即使它们除了未实现的函数还包含其他已经实现了的函数),但他们可以用作基类合约: pragma solidity ^0.4.0; contract Feline { function utterance() public returns (bytes32); } contract Cat is Feline { function utterance() public returns (bytes32) { return "miaow"; } }
如果合约继承自抽象合约,并且没有通过重写来实现所有未实现的函数,那么它本身就是抽象的。
3
接口(Interface)
接口类似于抽象合约,但是它们不能实现任何函数。还有进一步的限制: 无法继承其他合约或接口。 无法定义构造函数。 无法定义变量。 无法定义结构体 无法定义枚举。 将来可能会解除这里的某些限制。
接口基本上仅限于合约 ABI 可以表示的内容,并且 ABI 和接口之间的转换应该不会丢失任何信息。
接口由它们自己的关键字表示: pragma solidity ^0.4.11; interface Token { function transfer(address recipient, uint amount) public; }
4
库(Libary)
库与合约类似,它们只需要在特定的地址部署一次,并且它们的代码可以通过 EVM 的 DELEGATECALL (Homestead 之前使用 CALLCODE 关键字)特性进行重用。 这意味着如果库函数被调用,它的代码在调用合约的上下文中执行,即 this 指向调用合约,特别是可以访问调用合约的存储。 因为每个库都是一段独立的代码,所以它仅能访问调用合约明确提供的状态变量(否则它就无法通过名字访问这些变量)。 因为我们假定库是无状态的,所以如果它们不修改状态(也就是说,如果它们是 view 或者 pure 函数), 库函数仅可以通过直接调用来使用(即不使用 DELEGATECALL 关键字), 特别是,除非能规避 Solidity 的类型系统,否则是不可能销毁任何库的。
库可以看作是使用他们的合约的隐式的基类合约。虽然它们在继承关系中不会显式可见,但调用库函数与调用显式的基类合约十分类似 (如果 L 是库的话,可以使用 L.f() 调用库函数)。此外,就像库是基类合约一样,对所有使用库的合约,库的 internal 函数都是可见的。 当然,需要使用内部调用约定来调用内部函数,这意味着所有内部类型,内存类型都是通过引用而不是复制来传递。 为了在 EVM 中实现这些,内部库函数的代码和从其中调用的所有函数都在编译阶段被拉取到调用合约中,然后使用一个 JUMP 调用来代替 DELEGATECALL。
下面的示例说明如何使用库(但也请务必看看 using for-https://solidity-cn.readthedocs.io/zh/develop/contracts.html?highlight=view#using-for 有一个实现 set 更好的例子)。 library Set { // 我们定义了一个新的结构体数据类型,用于在调用合约中保存数据。 struct Data { mapping(uint => bool) flags; } // 注意第一个参数是“storage reference”类型,因此在调用中参数传递的只是它的存储地址而不是内容。 // 这是库函数的一个特性。如果该函数可以被视为对象的方法,则习惯称第一个参数为 `self` 。 function insert(Data storage self, uint value) public returns (bool) { if (self.flags[value]) return false; // 已经存在 self.flags[value] = true; return true; } function remove(Data storage self, uint value) public returns (bool) { if (!self.flags[value]) return false; // 不存在 self.flags[value] = false; return true; } function contains(Data storage self, uint value) public view returns (bool) { return self.flags[value]; } } contract C { Set.Data knownValues; function register(uint value) public { // 不需要库的特定实例就可以调用库函数, // 因为当前合约就是“instance”。 require(Set.insert(knownValues, value)); } // 如果我们愿意,我们也可以在这个合约中直接访问 knownValues.flags。 }
当然,你不必按照这种方式去使用库:它们也可以在不定义结构数据类型的情况下使用。 函数也不需要任何存储引用参数,库可以出现在任何位置并且可以有多个存储引用参数。
调用 Set.contains,Set.insert 和 Set.remove 都被编译为外部调用( DELEGATECALL )。 如果使用库,请注意实际执行的是外部函数调用。 msg.sender, msg.value 和 this 在调用中将保留它们的值, (在 Homestead 之前,因为使用了 CALLCODE,改变了 msg.sender 和 msg.value)。
以下示例展示了如何在库中使用内存类型和内部函数来实现自定义类型,而无需支付外部函数调用的开销: library BigInt { struct bigint { uint[] limbs; } function fromUint(uint x) internal pure returns (bigint r) { r.limbs = new uint[](1); r.limbs[0] = x; } function add(bigint _a, bigint _b) internal pure returns (bigint r) { r.limbs = new uint[](max(_a.limbs.length, _b.limbs.length)); uint carry = 0; for (uint i = 0; i < r.limbs.length; ++i) { uint a = limb(_a, i); uint b = limb(_b, i); r.limbs[i] = a + b + carry; if (a + b < a || (a + b == uint(-1) && carry > 0)) carry = 1; else carry = 0; } if (carry > 0) { // 太差了,我们需要增加一个 limb uint[] memory newLimbs = new uint[](r.limbs.length + 1); for (i = 0; i < r.limbs.length; ++i) newLimbs[i] = r.limbs[i]; newLimbs[i] = carry; r.limbs = newLimbs; } } function limb(bigint _a, uint _limb) internal pure returns (uint) { return _limb < _a.limbs.length ? _a.limbs[_limb] : 0; } function max(uint a, uint b) private pure returns (uint) { return a > b ? a : b; } } contract C { using BigInt for BigInt.bigint; function f() public pure { var x = BigInt.fromUint(7); var y = BigInt.fromUint(uint(-1)); var z = x.add(y); } }
由于编译器无法知道库的部署位置,我们需要通过链接器将这些地址填入最终的字节码中 (请参阅 使用命令行编译器- https://solidity-cn.readthedocs.io/zh/develop/using-the-compiler.html#commandline-compiler 以了解如何使用命令行编译器来链接字节码)。 如果这些地址没有作为参数传递给编译器,编译后的十六进制代码将包含 Set ____ 形式的占位符(其中 Set 是库的名称)。 可以手动填写地址来将那 40 个字符替换为库合约地址的十六进制编码。
与合约相比,库的限制: 没有状态变量 不能够继承或被继承 不能接收以太币
(将来有可能会解除这些限制)
4.1 库的调用保护
如果库的代码是通过 CALL 来执行,而不是 DELEGATECALL 或者 CALLCODE 那么执行的结果会被回退, 除非是对 view 或者 pure 函数的调用。
EVM 没有为合约提供检测是否使用 CALL 的直接方式,但是合约可以使用 ADDRESS 操作码找出正在运行的“位置”。 生成的代码通过比较这个地址和构造时的地址来确定调用模式。
更具体地说,库的运行时代码总是从一个 push 指令开始,它在编译时是 20 字节的零。当部署代码运行时,这个常数 被内存中的当前地址替换,修改后的代码存储在合约中。在运行时,这导致部署时地址是第一个被 push 到堆栈上的常数, 对于任何 non-view 和 non-pure 函数,调度器代码都将对比当前地址与这个常数是否一致。
4.2 Using For
指令 using A for B; 可用于附加库函数(从库 A)到任何类型(B)。 这些函数将接收到调用它们的对象作为它们的第一个参数(像 Python 的 self 变量)。
using A for *; 的效果是,库 A 中的函数被附加在任意的类型上。
在这两种情况下,所有函数都会被附加一个参数,即使它们的第一个参数类型与对象的类型不匹配。 函数调用和重载解析时才会做类型检查。
using A for B; 指令仅在当前作用域有效,目前仅限于在当前合约中,后续可能提升到全局范围。 通过引入一个模块,不需要再添加代码就可以使用包括库函数在内的数据类型。
让我们用这种方式将 库 中的 set 例子重写: // 这是和之前一样的代码,只是没有注释。 library Set { struct Data { mapping(uint => bool) flags; } function insert(Data storage self, uint value) public returns (bool) { if (self.flags[value]) return false; // 已经存在 self.flags[value] = true; return true; } function remove(Data storage self, uint value) public returns (bool) { if (!self.flags[value]) return false; // 不存在 self.flags[value] = false; return true; } function contains(Data storage self, uint value) public view returns (bool) { return self.flags[value]; } } contract C { using Set for Set.Data; // 这里是关键的修改 Set.Data knownValues; function register(uint value) public { // Here, all variables of type Set.Data have // corresponding member functions. // The following function call is identical to // `Set.insert(knownValues, value)` // 这里, Set.Data 类型的所有变量都有与之相对应的成员函数。 // 下面的函数调用和 `Set.insert(knownValues, value)` 的效果完全相同。 require(knownValues.insert(value)); } } 也可以像这样扩展基本类型: library Search { function indexOf(uint[] storage self, uint value) public view returns (uint) { for (uint i = 0; i < self.length; i++) if (self[i] == value) return i; return uint(-1); } } contract C { using Search for uint[]; uint[] data; function append(uint value) public { data.push(value); } function replace(uint _old, uint _new) public { // 执行库函数调用 uint index = data.indexOf(_old); if (index == uint(-1)) data.push(_new); else data[index] = _new; } }
注意,所有库调用都是实际的 EVM 函数调用。这意味着如果传递内存或值类型,都将产生一个副本,即使是 self 变量。 使用存储引用变量是唯一不会发生拷贝的情况。 本文作者:HiBlock区块链社区技术布道者辉哥
原文发布于简书
区块链马拉松|Blockathon(2018)上海站开放报名
以下是我们的社区介绍,欢迎各种合作、交流、学习:)
「深度学习福利」大神带你进阶工程师,立即查看>>> 大多数加密货币没加密,其实应该叫密码货币或签名货币,它们多数只用到了数位签章的不可否认性(non-repudiation),没有用到密码学的机密性(confidentiality),除了Zcash之流有用到homomorphic encryption。 大多数token的用途都是中心化的,即便这些token存在去中心化的区块链上,如:在某个还没写出来的网站平台跟你说会用到,但其实他们大可用DB做个酷碰点数就好;而且,没有任何一个合作厂商会想要拿你家平台的代币做利润拆分,还要自己找交易所出金,吃饱太闲。 部分token的功能,ETH都能做。这些代币没有价值或微乎其微,顶多算网站平台使用费,这类型通常也炒不起来,连投机人士都不太想买帐,除非这些投资人是没做功课的肥羊,如:VC平台、ENS平台。 大多数资料上链的token,根本做不到验证资料是真是假,或负责资料上链的单位本来就是trusted third party(可信第三方)。区块链上写巴黎铁塔倒了,巴黎铁塔就真的倒了吗? 你已经相信气象局网站的地震资料,那气象局跟你说他要把资料上区块链,你会因此更相信它吗? 多此一举,只是多了一个没用的代币,这样的资料上链根本没有意义,如:供应链、能源相关、证书相关应用、所有权上链和转移,广告分润(先解释怎么阻止聘用大量人力刷假流量,不然链上都是假量的资料有何意义?AI?人工智慧有100%正确吗?) 部分token什么也没告诉你,只告诉你他们会涨,什么时候能涨多少,会上那些交易所,虽然这些token没用到极点,但个人很佩服庞氏骗局在各个时代都能有它不同的样貌。 中国的白皮书,已经到了不骗人还不行的地步,投资人会说你这写的太诚实了,不能炒,他们不买帐。 这年头说自己一个区块链或应用已经被证明可以跨多个公有链的都是瞎扯,问问知名区块链的核心团队,谁要配合你改共识协定或新增op code。
「深度学习福利」大神带你进阶工程师,立即查看>>>
据新华社报道,10月8日,海南自贸区(港)区块链试验区正式在海南生态软件园授牌设立,这也是目前为止国内第一个区块链试验区。
该试验区位于海南生态软件园,与试验区同一天成立还有2家研究中心,分别是海南生态软件园与牛津大学共同设立的“牛津海南区块链研究院”;海南生态软件园与中国人民大学大数据区块链与监管科技实验室共同设立的“区块链制度创新中心”。
据报道,海南省工信厅厅长王静表示:“试验区将致力于吸引世界各地的区块链人才,并探索区块链在跨境贸易,包容性金融和信用评级等领域的应用。”
王静指出,试点区将“深化与全球顶级研究机构以及区块链行业的主要参与者的合作”。
据了解,目前园区已吸引了360区块链、迅雷区块链等一批企业入园。
尽管国内对于以区块链技术为基础的虚拟货币打击甚严,但对于区块链技术却非常开放,此前,农业银行与交通银行都已经开始使用区块链发放证券与贷款,而最高法也承认了区块链证据的法律效力,南京还上线了国内首家区块链仲裁平台。 原文来自: https://www.linuxprobe.com/first-block-chain-established.html
「深度学习福利」大神带你进阶工程师,立即查看>>>
在开发过程中,常常用到各种加密方法和算法,本文总结了几种常用加密方法的原理。
1
对称加密
原理 :加密和解密数据使用同一个密钥,适合对大量数据进行加解密
安全性 :关键是密钥的保存方式,加密或是解密的任何一方泄漏密钥,都会导致信息泄漏
代表算法 :DES、3DES、Blowfish、IDEA、RC4、RC5、RC6、AES等
对称密码常用的数学运算:
**移位和循环移位 **
移位就是将一段数码按照规定的位数整体性地左移或右移。循环右移就是当右移时,把数码的最后的位移到数码的最前头,循环左移正相反。例如,对十进制数码12345678循环右移1位(十进制位)的结果为81234567,而循环左移1位的结果则为23456781。
**置换 **
就是将数码中的某一位的值根据置换表的规定,用另一位代替。它不像移位操作那样整齐有序,看上去杂乱无章。这正是加密所需,被经常应用。
**扩展 **
就是将一段数码扩展成比原来位数更长的数码。扩展方法有多种,例如,可以用置换的方法,以扩展置换表来规定扩展后的数码每一位的替代值。
**压缩 **
就是将一段数码压缩成比原来位数更短的数码。压缩方法有多种,例如,也可以用置换的方法,以表来规定压缩后的数码每一位的替代值。
**异或 **
这是一种二进制布尔代数运算。异或的数学符号为⊕ ,它的运算法则如下:
1⊕1 = 0 0⊕0 = 0 1⊕0 = 1 0⊕1 = 1
也可以简单地理解为,参与异或运算的两数位如相等,则结果为0,不等则为1。
**迭代 **
迭代就是多次重复相同的运算,这在密码算法中经常使用,以使得形成的密文更加难以破解。
2
非对称加密
原理:
非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥(privatekey)。公开密钥与私有密钥是一对,如果用公开密钥对数据进行加密,只有用对应的私有密钥才能解密;如果用私有密钥对数据进行加密,那么只有用对应的公开密钥才能解密
**安全性:**公钥可以被任何人知道,但是私钥被泄漏就会导致信息泄漏
应用场景:
数字签名,私钥拥有者对信息进行加密,接受者使用公钥解密成功,就可以确定发送者的身份
密钥长度:
通常是1024,2048等。密钥长度增长一倍,公钥操作所需时间增加约4倍,私钥操作所需时间增加约8倍,公私钥生成时间约增长16倍
加密的明文长度:
加密的明文长度不能超过RSA密钥的长度减去11byte,比如密钥长度是1024位的,1024位=1024bit=128byte,128-11=117byte,所以明文长度不能超过117byte,如果长度超过该值将会抛出异常。加密后密文的长度为密钥的长度,如密钥长度为1024bit(128Byte),最后生成的密文固定为 1024bit(128Byte)
**代表算法:**DES、3DES、Blowfish、IDEA、RC4、RC5、RC6、AES等
3
哈希散列算法
原理:
采用某种散列函数,输入不同长度的明文,得到相同的长度的密文,明文的微小变化都能引起密文的巨大变化。其实哈希散列算法不算是真正的加密,而是生成对应明文的指纹信息,用来校验数据的完整性。
**安全性:**不能通过密文反推明文,通常作为数据的完整性校验
**应用场景1:**生成信息摘要,验证信息的完整性
**应用场景2:**不用明文存储用户密码,比如使用md5(md5(用户密码)+salt)来存储密码和验证密码,防止攻击者用彩虹表攻击
**代表算法:**MD2、MD4、MD5、PANAMA、SHA-0、SHA-1、SHA-256、SHA-512等
4
常用算法对比
参考: DES加密算法原理 DES算法实例详解 AES对称加密算法扫盲 DES,3DES,AES这三种对称密钥的区别与联系 数字签名算法介绍和区别 HOTP和TOTP算法图解 本文内容来源于Robin Liu的博客
整理:区块链兄弟
「深度学习福利」大神带你进阶工程师,立即查看>>>
现今,科技已经侵犯了我们的隐私。个人或组织所做的大多数事情都属于公共领域。第三方会监控,存储并利用个人及组织的数据、模式、爱好(首选项)和所参与的活动。许多新兴商业模式依赖于收集、处理和转售我们的个人数据。
科技使得将数据关联到个人变的更加容易,即使个人选择退出社交网络平台。例如,在面部识别技术上的突破,已经被广泛应用在商业和安全领域,尤其是在中国和俄罗斯。
区块链技术可能会限制这种隐私被侵犯的影响,尽管在利用区块链技术实现用户隐私保护时仍会泄露一些个人信息。比如,一个用户可以将个人信息存储在区块链上,并公开该个人信息的部分临时信息来接受服务。比特币和其他基于区块链的数字货币已经表明:利用点对点分布式网络和公共账本技术可以实现可信且透明地计算。
本篇文章探讨了个人及组织产生的数据对隐私保护的影响。其次,本文还简单阐述了支持区块链技术的系统是如何使得用户重新掌控自己的隐私数据。
1
个人
隐私对于个人来说是十分重要的,因为他们的个人信息对组织、营销人员以及其他个体都是很有价值的。在互联网用户中常见的一句话是:如果你不为产品付费,那么你就是产品。这就意味着,对于那些提供免费服务的公司,比如社交网络平台,个人信息是很有价值的。
宪法保护
在美国,隐私保护对于各种宪法权利的行使是十分重要的——包括言论自由、结社自由、新闻自由、免受不合理搜查和缉获以及免于自证其罪的权利。国家行为者缺乏隐私可能会危及自身的这些权利。我们知道在公共领域他们的言论归于他们自己,但就个人而言可能不会说出这些原因,特别是在他们的观点或主题有争议或不受欢迎的时候。由于存在许多重要的意见不受欢迎或有争议,所以社会应该重视自我审查。如果知道自己正在被监视,就也可能会阻止你与志同道合的人会面。如果人们不能保持匿名的话,举报者和其他揭露组织不法行为的人将不可能再去做这些事情。随着技术的不断进步,法院已经对国家行为进行了约束。
医疗信息
如果信息是权力,那么保护该个人信息能够帮助人们与组织机构进行协商。例如,健康保险公司可以使用负面健康信息向特定个人收取更高的保费,或拒绝承保。因此,个人有动机阻止此类信息公开于公共领域。健康信息的公开也可能会让一个人在社交生活中或在职场上感到尴尬。
财务信息
财务信息是个人隐私信息的另一部分。人们可能不希望让金融机构了解到几年前的不良信用记录,并且肯定也不希望不法分子利用自己的个人信息进行身份盗用或金融欺诈。
尽管人们不得不频繁地披露自己的个人财务信息,比如纳税或获得抵押,但是如果将这些信息公开,那么会吸引各种各样的人关注。寻求客户的公司、寻求捐款者的慈善机构,以及寻觅捐款的政治候选人等都会对了解个人财务信息感兴趣。虽然这些人大部分都是出于良好意图的,但是人们对于自己想要与谁分享个人信息以及想要利用这些信息做些什么的想法都是因人而异的。
例如,人们可能不希望公司根据他们的财务信息来确定他们能够并愿意支付某些商品的最大金额数——通常这些商品以较低价格就能够购买到。 然而,Orbitz在向使用Mac的用户展示了同一个酒店房间的时候,其价格却高于使用PC的用户。这表明,即使是一个很小的个人信息,比如一个人是否使用PC或Mac,也会帮助营销人员衡量一个人的经济能力——这种方式让大多数人都会觉得很不舒服。
个人行为
研究表明:当人们知道自己正在被监控的情况下,人们的行为举止会有所不同。因此,在更基础的层面上,隐私能够让一个人表现出受鼓舞的、亲密的、或有点傻却毫无害怕的样子。就像人们本能地关上或锁上前门一样,他们渴望在使用科技的同时保护自己的隐私。正如上面讨论的,组织机构有很多正当理由(包括实现使用产品和服务的便捷性、简化交互过程以及通过研究消费者的偏好来创造更好的产品或服务)来收集个人信息。精明的组织机构会尽力不违背人们对个人隐私保护的期望,因为个人隐私本身就很有价值:它使得人们可以以自己的方式做事并不受拘束。
匿名和使用假名
在互联网的核心中存在一个悖论:人们期望它是一个开放透明的论坛,可以交换想法,信息,商品和服务,但他们也期望匿名上网。正如著名的《纽约客》漫画上的标题所说:“在互联网上,没人知道你是条狗。”不同的利益集团和国家对互联网上隐私保护的期望会有所不同。比如,由于政府监管,韩国人对互联网隐私的期望低于美国人。在2015年年初,中国政府通过了新法规——要求未来互联网用户在使用微博或其他社交媒体时使用真实姓名。在互联网上允许匿名和使用假名的需求备受争议。例如,虽然对于一个大学生来说,期望在网上匿名是合理的,但是对于某人利用互联网谋划暴力犯罪就不能同一而论了。对于教授是否应该被允许使用笔名发文章,人们也各执一词。
虽然蛮有意思的,但是随着新技术给个人隐私带来的新的挑战,有关匿名和使用假名的辩论就变得毫无实际意义了。
社交媒体和共享经济要求披露个人信息
Facebook,Twitter和其他社交网络平台的兴起改变了人们对互联网隐私保护的期望。使用这些平台的人自愿提供个人信息,并同意与每个人或限定的某些人分享。然而,即使那些不想分享个人信息的人(例如,没有Facebook或Twitter帐户的人)也会因职业或营销目的而感到有压力。雇主经常会对候选员工进行Google搜索。虽然没有结果比糟糕的结果要好,但今天的求职者通常会使用互联网来推销自己,无论是通过创建LinkedIn帐户,还是通过个人网站、博客或文章来彰显自己的成就。对于小型企业来说也是如此:大多数企业要么都有在线业务,要么因为没有线上服务而失去该业务。
过去十年中的另一个主要技术趋势是按需经济(简称为共享经济)的出现,其中商品或服务的提供者通过网络、手机应用程序或站点与用户进行交易。 这将弱化已建立的中间参与者在交易中所发挥的作用(称为去中介的过程)。 就像Uber和Lyft这样的乘车共享服务,使得传统的出租车服务和城市出租车系统几乎被淘汰,维基百科已经取代了像Microsoft Encarta这样的大型私人编辑的百科全书。
现今,旅行者要查询的不仅是其他城市的酒店价格,还包括通过Airbnb直接从其他人那里租用短期房间或房屋的价格。 随着Airbnb和其他标志性按需经济公司的出现,他们需要通过检验主人和客人提供的个人信息来保障消费者的安全。 此外,在通过Airbnb入住后,我们会邀请主人和客人对双方进行评价,这些评价通常会包含一些个人信息,并且任何人都可以通过Airbnb网站浏览这些信息。
虽然像eBay这样的公司几十年来一直利用身份验证及用户评价来打击欺诈和鼓励商家保证线上市场的品质,但是新一代共享经济应用将个人信息与信誉值等同起来:信誉值越多越好。因为按需经济中参与者之间的互动比eBay上卖家与买家互动要紧密的多,所以这么做还是有点道理的。乘坐陌生人的车,睡在陌生人的家里,并且允许陌生人帮你遛狗,这些都要求该陌生人在应用程序或平台上具有很高的可信度。
收集信息越多的平台可以建立更多更可靠的信任。比如,虽然某个Airbnb客人可以通过主人积极正面的历史评价来获得信任,但是没有任何历史记录的用户可能还是需要通过上传ID,或链接到他们的Facebook账户来表明其可信度。因此,虽然共享经济的“去中介化”使得人们之间彼此信任,但它也希望人们可以在平台上、甚至是在公共领域上透露一些公共信息。
人们提供给社交媒体网络和按需经济服务的隐私数据(所处的地理位置、年龄、性别、消费偏好、社交偏好以及其他类似属性)可以为搜索/查询某个人或组织提供一个基本描述。
2
组织机构
保护组织策略和专有信息
组织机构需要保护敏感信息——例如公司战略见解或专有信息(如知识产权),这些信息可能会被竞争对手或不法分子用来破坏组织。这不仅仅是针对那些在行业内拥有尖端技术的组织机构(例如,国防部门、航空航天业或汽车行业),而是针对所有机构而言。2016年,黑客攻击了民主党国家委员会并发布了其内部邮件,从而破坏了几位民主党候选人的信誉。 同年,冒充孟加拉国中央银行官员的黑客向纽约联邦储备银行发出指示,试图从孟加拉国央行在纽约联邦储备银行的帐户中盗取9.51亿美元。 他们成功盗取了1.01亿美元,其中大部分资金仍未被收回。 这些引人注目的黑客攻击意味着:在保护组织战略和专有信息方面,组织机构仍面临的巨大挑战——这些挑战来自竞争对手和不法分子。
以营销和研究为目的收集消费者信息
组织收集客户信息用于营销。比如,杂货店通过筛选从人们手机上收集到的位置信息,来确定他们在某些过道上花费的时间。飞行常客计划和其他顾客信赖度项目会提供额外的优惠(或特权)来换取他们的个人信息,然后再利用这些信息提升产品和服务。 对于营利性和非营利性组织来说,建立客户或捐赠者信息档案有助于销售产品和筹集资金。
客户信息还可用于帮助平台了解消费者偏好并在将来为顾客提供更好的产品和服务。此外,组织机构收集的客户信息通常会使得未来客户与该组织交易更方便。
在收集此类信息时,组织机构必须遵守适用的联邦和州法律。 在美国,医疗保健公司、金融服务公司和其他公司在被允许收集的客户信息类型方面受到了不同的限制。有经验的组织熟悉管理其行业的法律框架。随着数据收集和分析越来越多地由非人类行为者操作,法律和法规的遵从将变得越来越困难。
保护消费者信息
对于所有面向消费者的公司,尤其是谷歌,苹果和亚马逊等技术公司,从消费者那里收集个人信息有助于为每个消费者提供更加个性化的服务。与此同时,它还使得公司有责任保护这些信息。 例如,用户可以在Mac,iPhone和iPad上同步数据,从而方便人们访问信息,但也产生了一个期望——期望Apple公司能够采取措施保护此类信息免受外部侵害。
保护客户信息
对于那些为其他组织提供服务的机构(例如会计或法律服务组织)来说,保护好客户信息至关重要。 黑客曾瞄准专业服务公司,并试图规避客户复杂的数据保护措施来获取客户数据。 了解了这一风险之后,主要的专业服务公司已经采取了一些重要措施来保护客户信息。
目前保护敏感信息的组织策略
组织机构已经采取了许多措施来保护敏感信息:例如,雇用内部和外部信息安全专业人员,教授员工如何保护信息,并审查员工防范内部威胁。 一些已被锁定或可能成为目标的组织也开始使用蜜罐技术(通过受公司监控的数据室声称:“这里保存了公司敏感信息”,从而来诱骗黑客并帮助公司了解黑客的动机)。 这些措施都是十分重要和必需的,并且需要不断改进来迎接新的挑战。
3
大数据
组织机构收集的数据包含各种信息:比如一个公司的产品和服务、内部流程、市场条件以及竞争对手、供应链、顾客偏好趋势、个人消费者偏好以及消费者与产品、服务、线上网站之间的具体互动。各组织机构收集数据的数量明显有所增加。
至少在过去的一个世纪中,对存储数据量不断扩大的担忧一直存在。 2014年4月,研究机构IDC发布了一份题为“充满机遇的数字世界:丰富的数据和不断增长的物联网价值”的报告,预测“从2013年到2020年,数字世界将扩张10倍 - 从4.4万亿千兆到44万亿千兆。 目前数据的扩展是由计算和数据存储能力的提升、传感器数量的增加以及传感器间交互增多所驱动的。
算力和数据存储能力的不断提升
随着时间的推移,我们发现存储更多信息变的更加容易,因为在过去的几十年中,计算能力和存储容量都有着显著提升。 英特尔联合创始人戈登·摩尔(Gordon Moore)在1975年观察到——芯片上的晶体管数量每两年翻一番。 这种现象被称为摩尔定律,准确描述了计算能力在进入二十一世纪后呈现出的指数增长趋势。 同样地,在过去的几十年中,数据存储容量也呈指数级增长,尤其是我们已经能够在较小的驱动器上存储大量的数据。
正是由于这些突破,使得大数据的存储成为可能(且更加便宜和方便)。 因此,组织机构更倾向于存储更多的数据,因为随后证明有用数据丢失带来的风险远超过减少数据存储(减少存储成本)带来的好处。
云计算的兴起
云计算仅仅意味着按需使用远程(而非本地)算力、数据存储、应用程序或网络。 由于云计算的出现,组织可以简单地从云服务提供商那里租用计算能力或存储空间(不再需要在自己的服务器上存储大量数据,并维持巨大的计算能力),或者与供应商一起维护传统数据库(尽管传统数据库仍然可用在大型组织机构中)。 由于云服务提供商必须能够提供可靠的需求及可扩展的解决方案,所以亚马逊,微软和谷歌等大公司成为了主要的云服务提供商。
面向企业的云计算服务有三种形式: 软件即服务(SaaS),其中云服务提供商允许组织在线使用其软件(例如,在线访问TurboTax); 平台即服务(PaaS),组织机构在该平台上使用云服务提供商的资源为其成员开发应用程序(例如,Microsoft Azure); 基础架构即服务(IaaS),其中云服务提供商为客户提供基本的基础架构服务(例如,Netflix使用Amazon Web Service基础设施来实现视频流媒体播放)。 (个人用户可能更熟悉云应用程序,例如iDrive,Google Docs或Dropbox。)
云计算的实现不仅依赖于前面讨论的计算能力和数据存储容量的进步,还依赖于互联网访问速度以及可靠性的的显著提升。尽管云计算在一定程度上是为了应对存储数据不断增长,但它的广泛采用也促进了存储数据量的增长。
传感器数量增长及连通性
虽然传统意义上,互联网由用户彼此交互以及与数据库的交互组成,但是现今互联网越来越多地被用来实现物理设备之间的彼此连接。 机器与机器(M2M)交互中的这种定性和定量增长预计将会产生无处不在的物联网:以集成的智能设备构成的网络通过最少的人为干预来实现日益复杂的功能。
物联网并不需要全新的基础设施。 相反,它是通过将传感器嵌入现有设备和基础设施来实现的。 例如,当家庭空调系统使用传感器来确定人们何时在家时,系统可以使用该信息来确定每个房间的温度,从而使得它变的很“智能”。 同样,当城市能源和水基础设施中嵌入传感器时,可以利用智能系统监控使用,并预测未来使用量,从而更有效地分配资源。 先进的传感器几乎可以改进任何技术,从智能手机到心脏监测器,再到大型的农场或工厂。
智能设备根据其用途需要不同类型的传感器。 几十年来,计算机已经配备了摄像头和麦克风。 现在,设备还可以配备传感器,用来测量温度、运动、其他物体的距离、压力、化学物质和其他不同事物。 每年传感器的质量都在不断提升,且其价格也越来越低。
虽然传感器本身就可以大大改善设备,但是许多智能系统需要设备之间进行通信。 例如,虽然在车内嵌入各种传感器有助于车辆自行驾驶,但若能让路上的所有汽车之间实现相互通信,那将会更加有用。 这将缓解交通堵塞,并在理想情况下使汽车行驶更加安全。 类似地,当物联网适用于大规模生产或仓储时,它将要求设备之间有良好的通信。 各种通信技术的进步,尤其是无线通信技术,已经为物联网技术打开了大门。
智能设备通常会收集个人数据
在智能设备出现之前,你早上跑步基本上不会产生数据。 现在,如果你在智能手机上安装健康应用程序再进行晨跑,那么在你跑步的这段时间内,你晨跑的路线,跑步的步数以及整个晨跑过程中各个点的心率数据都将被收集和存储在手机中。 同样,三十年前,安装在窗口的空调不会产生太多数据。 如今,智能家居温度系统每天都在采集大量有关温度和湿度的数据。 一旦数据被采集后,这些数据不仅可用于保持屋内适宜的温度,从而节约能源,还可推测你什么时候会在家里,或者你最有可能设置的温度。 上述晨跑和家用空调系统的例子表明,智能设备可以产生更多的数据。 它们还表明,为一个目的收集的个人数据还可用于很多其他地方。
数字世界正在以指数速度扩张:在2013年4月,Ralph Jacobson在IBM消费品行业博客(IBM’s Consumer Products Industry blog )上发表了一篇文章,他估计全球每天会创造出25亿千兆字节的数据。 正如计算能力和存储容量的进步促使组织机构收集的数据量增加一样,改进的传感器和通信技术的出现也会如此。 利用传感器感知周围事物,并将这些测量结果传送到其他设备或服务器上,再将其收集并存储为一个数据点。
人工智能
正如我前一篇文章所讨论的,人工智能来源于数据。
大多数人工智能研究都是由谷歌,亚马逊和百度资助,因为数据是人工智能的“食粮”,而这些公司每天都会产生大量的数据。 微软收购LinkedIn不是因为它的平台,而是因为它拥有的数据。
到目前为止,一些公司已经利用人工智能来改变金融和生产。 保护我们的财务信息有时看起来像是会注定失败的努力——因为政府,房东,银行,信用卡公司和信用评级机构都会收集你的财务信息(并且正如Equifax遭受黑客攻击所表明的,存储这些信息很不安全)。
相比于财务信息,人们通常对他们的医疗健康信息更加敏感。人工智能已被应用于医疗健康数据,但由于隐私问题,这些数据通常是零碎和分散的,因此人工智能在医疗健康中的作用有限。然而,最终公司将利用我们的个人健康数据来完善日益全面的数据库。
如果技术侵犯了我们的隐私,那么技术也许也可以帮助我们解决这个问题。
4
区块链
具有特定协议的区块链能够实现不同程度上的匿名性,机密性和隐私保护,而这些可以用来保护医疗健康数据,财务信息和其他个人数据,同时仍然允许这些数据用于人工智能应用程序。 例如,用户可以拥有存储着个人健康信息的区块链,并且仅向产品或服务提供商(例如隐形眼镜制造商)简要地发布该信息的特定单元数据(例如视力处方)从而实现某个特定目的。
虽然区块链是一个公共分类账本并存储在多个不同位置的节点上,但它可以实现匿名和信任,正如多个基于区块链的应用程序和已经存在的具有高度隐私性的加密货币所表明的那样。
目前,第三方收集的个人数据通常存储在具有单点故障的中心化的数据库中。 这些数据的泄漏往往被忽视且未被报道。 一旦我们的数据被掌握在不受信任的一方手中,我们就无法控制它将被如何使用。
区块链方案
正如比特币所表明的那样——密码学和经过深思熟虑的经济激励可以创建一种安全的方式来存储和管理信息,包括个人信息。
区块链上的私有数据受加密保护。 我在别处讨论过区块链技术的核心是进行哈希计算。 以下是区块链技术可用于保护个人数据的一些方法(即使在将部分数据用于算法处理的情况下)。
同态加密
一种称为“同态加密”的新型加密技术允许在加密数据上进行计算,而无需将密文数据先解密。 这意味着可以在对其执行计算时保护数据的隐私性和安全性。 只有具有相应解密密钥的用户才能访问数据或交易的详细信息。
诸如零知识证明(ZKPs)和zk-SNARK之类的密码学技术已经使用了同态加密。 一种名为Zcash的加密协议使用zk-SNARK来加密其数据,并仅向授权方提供解密密钥,以便他们查看该数据。
状态通道
区块链可以为非区块链解决方案提供模型,或者作为保护隐私的混合解决方案中的一部分。
状态通道是一种可能发上在区块链上的链间互动。 状态通道通过下面三个过程来完成: 锁定:通过链上的智能合约锁定交易。 交互:交互发生在链下或侧链上。 发布:在交互完成且状态通道关闭后,解锁智能合约并且在区块链上发布该交易的索引。
服务提供商可以通过状态通道来维护用户数据的私密性和安全性。 我们可以链下进行交易,并将交易的哈希值存储到区块链上(不披露任何有关交易的机密细节)。
5
总结
目前,我们的私人信息仍集中于互联网上和公司的数据库中,因此这些数据被少数“玩家”掌控。 呈现出指数增长率的新增数据量和数据收集量预示着:未来我们的隐私还是很可能会被侵犯。 基于区块链或受区块链启发的解决方案有助于保护我们的隐私数据,同时也使我们能够从更快的交易,更好的服务以及更强大的人工智能算法中受益。 本文内容来源于无退社区
「深度学习福利」大神带你进阶工程师,立即查看>>>
Hyperledger fabric是基于区块链技术的一个开源项目,由Linux基金会于2015年发起,目的是推进区块链数字技术和交易验证的发展和落地。 Hyperledger由多个区块构成了一个有序链表,每个区块里包含多条交易(trasanction,缩写为tx)。Jerry在学习账本的数据结构时,发现一个有趣的现象:上图中WorldState(世界状态)的设计目的,是为了提升性能。比如,有一个channel里共发生了1千次交易,为了获取该channel的当前状态值,需要沿着区块链的首块出发执行这1千次交易,有点像SAP HANA内存数据库实时计算的思路。 而Hyperledger Fabric选择了在每次新交易处理完后,都同步更新一个称之为levelDB的数据库。这样每次查询当前状态时,无需遍历区块链每个区块重复执行交易,只需要查询该levelDB数据库即可。 这个levelDB的概念和CRM里的订单抬头的很多字段,比如总价,毛重(Gross weight)等等设计思路是一样的。 比如我在ID为IMU的产品主数据里维护了1个ST的单位重50KG,那么下图订单包含了两个行项目,一共8个ST,毛重50 × 8 = 400KG。 这个400KG是存储在表CRMD_CUMULAT_H的GROSS_WEIGHT字段。 顾名思义,这个字段的值是从另一张存放行项目明细信息的表CRMD_PRODUCT_I里的GROSS_WEIGHT累加而来的,这也是这张表的部分名称CUMULAT的由来:(cumulate累积) 每次行项目里产品数量发生变化时,会触发one order框架的回调函数,更新CRMD_CUMULAT_H的GROSS_WEIGHT. 最后数据更新通过CRM_CUMULAT_H_UPDATE_DU写回到CRMD_CUMULAT_H里。CRMD_CUMULAT_H扮演的角色同Hyperledger Fabric里的levelDB相同。
要获取更多Jerry的原创技术文章,请关注公众号"汪子熙"或者扫描下面二维码:
「深度学习福利」大神带你进阶工程师,立即查看>>>
本文解释了比特币交易的内容,目的和结果。下面的解释适用于新手和中级比特币用户。
作为加密货币用户,你需要熟悉交易雏形——为了你对这种不断发展的创新有信心,以及作为理解新兴多签名交易和合约的基础,这两者都将在本系列的后期进行探讨。这不是纯技术文章,解释将集中在你需要了解的标准比特币交易——我们通常做的支出交易——并且我们将掩盖你可以安全忽略的内容。
本文底部的信息图提供了从钱包到区块链的整个比特币交易流程的全面说明。
注意:即使是核心开发人员也承认,用于描述交易及其组件的某些语言可能导致人们误解了实际发生的事情。在下面的解释中避免了这些误解。因此,在尝试尽可能简单的描述的同时,借助一些图表,让我们直接开始。
术语和缩写的定义 Bitcoin:具有大写 B 的比特币指的是协议——代码,节点,网络及其对等交互。 bitcoin:用小写字母 b 表示货币——我们通过比特币网络发送和接收的加密货币。 tx:在文本中使用的任何地方——是比特币交易 ‘Bitcoin transaction 的缩写。 txid:是 transaction id 的缩写——这是人和协议引用交易的哈希。 Script:是比特币协议的脚本系统的名称,用于处理和验证交易——脚本是一个聪明的,基于堆栈的指令引擎,它使得从简单支付到复杂的oracle监督合约的所有交易成为可能。 UTXO: Unspent Transaction Output 的缩写,也称为“输出”。 satoshi:1 BTC = 100,000,000 satoshi
什么是比特币交易?为什么?
1.定义
比特币交易是一个经过签名的数据,它被广播到网络上,如果有效,最终会进入区块链的一个区块。
2.目的
比特币交易的目的是将一定数量的比特币的所有权转移到比特币地址。
3.结果
当你发送比特币时,你的钱包客户端会创建一个单一的数据结构,即比特币交易,然后广播到网络。网络上的比特币节点将中继和重新广播交易,如果交易有效,节点将把它包含在他们正在挖掘的块中。通常,在10-20分钟内,交易将与区块链中的一个区块中的其他交易一起被包括在内。此时接收者能够看到他们钱包中的交易金额。
4.例子
以下是今年早些时候区块链中包含的示例交易:
此标准交易的主要组成部分采用颜色编码: 交易ID(以黄色突出显示) 描述符和元数据(蓝色花括号在右边详细说明) 输入(粉色区域) 输出(绿色区域)
比特币交易输入和输出
首先,关于交易的四个公理: 我们发送的任何比特币金额总是发送到一个地址。 我们收到的任何比特币金额都被锁定在接收地址——这通常与我们的钱包相关联。 每当我们花费比特币时,我们花费的金额将始终来自之前收到的并且目前存在于我们钱包中的资金。 地址接收比特币,但他们不发送比特币——比特币是从钱包发送的。
进入我们钱包的金额并不像实体钱包中的硬币那样混乱。收到的金额不会混合,但保持独立且与钱包收到的确切金额不同。这是一个例子:
示例:
你创建一个全新的钱包,并及时收到三个0.01,0.2和3BTC的金额,如下所示:你将3BTC发送到与钱包相关联的地址,并由Alice向另一个地址付款。
钱包报告的余额为3.21BTC,但如果你真的看钱包里面,你会看到——不是321,000,000 satoshi(321 mil satoshi),但是三个不同的数量仍然由他们的原始交易组合在一起:0.01,0.2和3BTC。
收到的比特币金额不会混合,但保持分开,作为发送到钱包的确切金额。上例中的三个金额称为其原始交易的输出。
比特币钱包始终保持输出分离和独特。
输出 output 是(通过标准交易)发送到比特币地址的金额,以及解锁输出金额的一组规则。在比特币用语中,输出称为“未使用的交易输出”或 UTXO 。
可以使用与接收地址相关联的私钥解锁标准交易输出。地址及其相关的公钥/私钥对将在本系列的后面部分介绍。目前,我们只关注总数。
示例:
让我们考虑一个例子,在你向Bob发送0.15BTC的情况下跟踪钱。
正如我们所看到的,你的钱包没有选择15mil miloshi(0.15 BTC)来自一个无差别的321 mil satoshi组成钱包余额。相反,钱包从钱包中包含的三个现有输出 outputs 中选择一个支出候选者。因此,它选择(由于各种原因,现在不重要)0.2BTC输出。钱包将解锁0.2 BTC输出并使用全部0.2BTC作为新的0.15 BTC交易的输入 input 。0.2BTC输出在此过程中花费 spent 。
你的钱包创建的花费交易将向Bob的地址发送0.15BTC——它将作为输出存放在他的钱包中——等待最终花费。
0.05BTC差额(0.2 BTC输入减去0.15 BTC输出)称为改变 change ,交易将通过新创建的地址将其发送回你的钱包。0.05 BTC改变的金额将作为新输出存放在你的钱包中——等待最终花费。所以,现在你钱包里会显示以下内容:
“等待花费”的三个输出中的每一个被锁定到其接收地址,直到选择它们中的一个或多个作为新花费交易的输入为止。
在后台,当选择 UTXO 作为新交易的输入时,不同的钱包客户端应用不同的逻辑规则。一个理智的钱包策略是尽可能先使用旧的 UTXO ,但实现方式不同。我们现在并不关注选择 UTXO 的方式,因为我们的目标一直是强调我们的钱包收到的金额是分开的和不同的。
比特币交易如何完成的总结
各种收到的金额不会像在实体钱包中那样混合。相反,在我们花费比特币时,收到的金额(UTXO)被单独使用(或组合使用)。在创建支出交易时,我们的钱包选择UTXO(具有足够的价值以满足我们想要发送的金额)并且通常创建两个新输出:一个用于接收器,一个用于我们收到的更改到钱包。更改成为我们钱包中的全新UTXO,我们发送的金额成为锁定到收件人地址的UTXO——可能与钱包相关联,也可能不与钱包相关联,例如冷存储。用作支出交易的输入的原始UTXO将“花费”并永久销毁。
这是钱包软件如何处理输出(UTXO)的介绍。一旦选择了UTXO用于支出,它就需要与接收它的地址相关联的私钥。此私钥兑换UTXO并允许它成为新支出交易中的输入。以前的交易输出被重新用作新交易的输入的机制是比特币协议功能的核心——完全符合Satoshi的设计。
建议你浏览我们汇智网的各种编程语言的区块链教程和区块链技术博客,深入了解区块链,比特币,加密货币,以太坊,和智能合约。 java比特币开发教程 ,本课程面向初学者,内容即涵盖比特币的核心概念,例如区块链存储、去中心化共识机制、密钥与脚本、交易与UTXO等,同时也详细讲解如何在Java代码中集成比特币支持功能,例如创建地址、管理钱包、构造裸交易等,是Java工程师不可多得的比特币开发学习课程。 php比特币开发教程 ,本课程面向初学者,内容即涵盖比特币的核心概念,例如区块链存储、去中心化共识机制、密钥与脚本、交易与UTXO等,同时也详细讲解如何在Php代码中集成比特币支持功能,例如创建地址、管理钱包、构造裸交易等,是Php工程师不可多得的比特币开发学习课程。 php以太坊 ,主要是介绍使用php进行智能合约开发交互,进行账号创建、交易、转账、代币开发以及过滤器和交易等内容。 java以太坊开发教程 ,主要是针对java和android程序员进行区块链以太坊开发的web3j详解。 以太坊入门教程 ,主要介绍智能合约与dapp应用开发,适合入门。 以太坊开发进阶教程 ,主要是介绍使用node.js、mongodb、区块链、ipfs实现去中心化电商DApp实战,适合进阶。 python以太坊 ,主要是针对python工程师使用web3.py进行区块链以太坊开发的详解。 C#以太坊 ,主要讲解如何使用C#开发基于.Net的以太坊应用,包括账户管理、状态与交易、智能合约开发与交互、过滤器和交易等。 EOS入门教程 ,本课程帮助你快速入门EOS区块链去中心化应用的开发,内容涵盖EOS工具链、账户与钱包、发行代币、智能合约开发与部署、使用代码与智能合约交互等核心知识点,最后综合运用各知识点完成一个便签DApp的开发。
汇智网原创翻译,转载请标明出处。这里是 原文
「深度学习福利」大神带你进阶工程师,立即查看>>>
本文首发于 深入浅出区块链社区 原文链接: 深入理解Plasma(一)Plasma 框架 原文已更新,请读者前往原文阅读
这一系列文章将围绕以太坊的二层扩容框架,介绍其基本运行原理,具体操作细节,安全性讨论以及未来研究方向等。本篇文章作为开篇,主要目的是理解 Plasma 框架。
Plasma 作为以太坊的二层扩容框架,自从 2017 年被 Joseph Poon(Lightning Network 创始人)和 Vitalik Buterin (Ethereum 创始人)提出以来 [1] ,一直是区块链从业人员关注的焦点 [2] 。首先需要明确的是,Plasma 实质上是一套框架,而不是一个单独的项目,它为各种不同的项目实际项目提供链下(off-chain)解决方案。这也是为什么很多人对 Plasma 感到疑惑的一个重要原因,因为在缺乏实际应用场景的情况下很难将 Plasma 解释清楚。 因此,理解 Plasma 是一套框架是理解 Plasma 的关键。
从区块链扩容谈起
在介绍 Plasma 之前,不得不先介绍区块链扩容。我们都知道,比特币(Bitcoin)和以太坊(Ethereum)作为目前最广泛使用的区块链平台,面临的最大问题就是可扩展性(Scalability)。这里需要注意的是,区块链中的可扩展性问题并不是单独特指某个问题,而是区块链想要实现 Web3.0 [3] 的愿景,为亿万用户提供去中心化服务所要克服的一系列挑战。虽然以太坊号称是“世界计算机”,但这台“计算机”却是单线程的,每秒钟只能处理大约 15 条交易,与目前主流的 Visa 和 MasterCard 动辄每秒上万的吞吐量相比实在相形见绌。因此如何在保证区块链安全性的情况下,提高可扩展性是目前区块链发展亟待解决的问题之一。
目前关于区块链扩容的解决方案无外乎两个方向:一层(Layer 1)扩容和二层(Layer 2)扩容 [4] 。一层扩容也被称为链上(on-chain)扩容,顾名思义,这类扩容方案需要更改区块链底层协议。但同时也意味着需要将区块链硬分叉。这类扩容方案就像将原来的单核 CPU 改装成多核 CPU,从而可以多线程处理计算任务,提高整个网络的吞吐量。
目前最典型的一层扩容方案是 Vitalik 和他的研究团队提出的“Sharding(分片)”,也就是说将区块链划分成不同的部分(shards),每个部分独立处理交易。想要了解更多关于 Sharding 的信息,可以参考以太坊官方的 Wiki [5] 。
二层扩容也称链下(off-chain)扩容,同样非常好理解,这种扩容方案不需要修改区块链底层协议,而是通过将大量、频繁的计算工作转移到“链下”完成,并定期或在需要时将链下的计算结果提交到“链上”保证其最终性(finality)。二层扩容的核心思想是将底层区块链作为共识基础,使用智能合约或者其它手段作为链下和链上沟通的桥梁,当有欺诈行为发生时链下的用户仍然可以回到链上的某一状态。虽然将计算转移到链下会在一段时间内损失最终性,但这个代价是值得的,因为这样做不止可以极大提高区块链的灵活性和可扩展性,也极大降低了用户进行交易所需要的代价。将计算转移到链下也并不意味着完全放弃安全性,因为最终的安全性还是由底层所依赖的区块链来保证,因此二层扩容主要关注的问题就在于如何保证链上链下切换过程的安全性。这种思想最早被用在闪电网络(Lightning Network)当中作为比特币的其中一个扩容方案,并取得了很好的效果。
本文所要介绍的 Plasma 就属于基于以太坊二层扩容方案,类似的解决方案还有 State Channels 和 Trubit 。这些方案虽然面向的问题有所区别,但基本思想都是将复杂的计算转移到链下进行。那么,接下来我们将进入 Plasma 的世界,一窥究竟!
理解 Plasma
在前文中我们已经明白 Plasma 是一种二层扩容框架,那么该如何进一步理解 Plasma 是什么?它区别于其它二层扩容方案的地方在哪呢?
Plasma 也被称为“链中链(blockchains in blockchains)”。任何人都可以在底层区块链之上创建不同的 Plasma 支持不同的业务需求,例如分布式交易所、社交网络、游戏等。
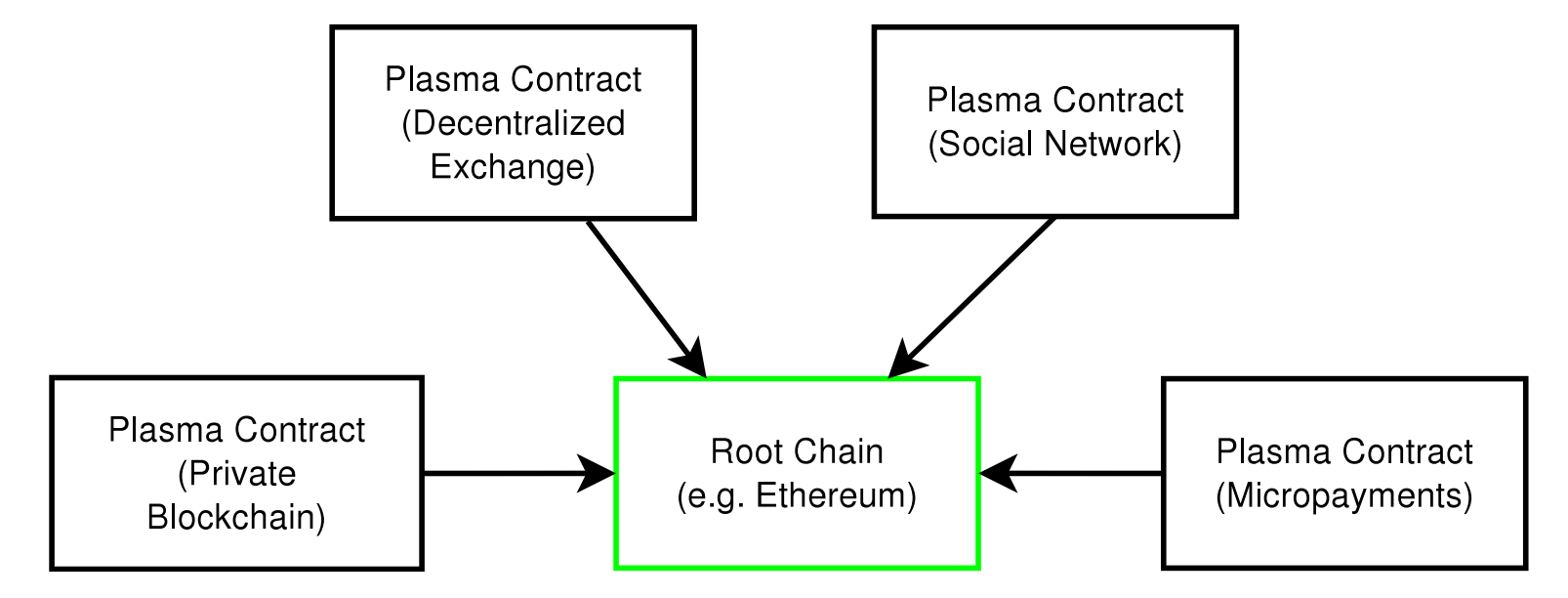
这里可以举一个例子来理解 Plasma。假如企鹅公司创建了一个 Plasma Chain 叫作 Game Chain。用户通过向 Game Chain 发送一些以太币换取 Token,用于购买皮肤等游戏内的增值商品。加入 Game Chain 的操作是在链上进行的,以太坊区块链将这部分资产锁定,转移到 Game Chain 上。之后每次我们购买虚拟商品的交易就会转移到链下进行,由企鹅公司记账。这种方式几乎跟我们现实生活中游戏内购的体验一样,不仅结算迅速,而且手续费低廉(相比于以太坊之上需要给矿工支付的手续费)。那么问题来了,如果企鹅公司从中作祟,修改账本,恶意占有我们的资产怎么办?这时我们就可以提交之前每次交易的凭证到以太坊区块链上,如果确实是企鹅恶意篡改了账本,那么我们不但能够成功取回自己的资产,还能获得之前企鹅公司创建 Game Chain 存入的部分或全部押金。
通过上面这个例子是不是已经明白 Plasma 大致是如何工作的了?但上面这个例子还是过于简单,只涉及用户自己和企鹅公司。下面我们使用区块链的语言对上面的例子进行解析。
首先,企鹅公司在以太坊主链之上创建了一系列智能合约作为主链和子链 Game Chain 通信的媒介。这些智能合约中不仅规定了子链中的一些基本的状态转换规则(例如如何惩罚作恶的节点),也记录了子链中的状态(子链中区块的哈希值)。之后企鹅公司可以搭建自己的子链(可以用以太坊搭建一套私链)。子链实际上是一个完全独立的区块链,可以拥有专门的矿工,使用不同于主链的共识算法,例如 PoS(Proof of Stake)等。
当子链创建完毕后,企鹅公司可以使用 ERC721 合约创建 token 作为游戏内的商品(就像 Cryptokitty)。但这里需要注意的是,所有数字资产必须在以太坊主链上创建,并通过 Plasma 子链的智能合约转移到子链中。用户也需要在主链上购买数字资产后转移到子链上。在上面这个例子中,Game Chain 的智能合约将主链上的资产锁定,之后在子链上生成等值的资产。之后用户就可以完全脱离主链,在子链上进行交易。企鹅公司在子链上扮演 operator 的角色,如果一切运行正常,子链中的矿工会正常打包区块,并在需要时由 operator 将区块的哈希值提交到主链作为子链的状态更新证明。在这个过程中,用户完全不需要和主链交互。
我们可以看到,将复杂的计算操作转移到链下确实使得整个交易过程变得简单。但没有强大的共识算法和庞大的参与者,资产在子链上是很不安全的。Plasma 给了我们一种避险机制,即使 operator 作恶,我们也能取回属于自己的资产。下图(来源自 [1] )简单说明了这个过程。图中,在第 4 个区块中的交易被篡改。由于 Alice 本地保存有 Plasma Chain 中所有的区块数据,因此她可以向主链提交一个含有“防伪证明(Fraud Proof)”的交易。如果证明生效,那么主链将状态从 4 号区块回滚到 3 号区块,一切恢复正常。Plasmas Chain 中的参与者也可以随时提交资产证明,返回到主链。
到这里我们应该已经理解了, Plasma 所要做的工作并不是保护子链的安全,而是当有安全事故发生时,保证用户可以安全地取回自己的资产,并返回到主链上。并且采用一系列经济激励的方式减少作恶情况的发生 。
下一篇文章将对 Plasma 运行过程的细节进行剖析。
相关资源 https://plasma.io/ https://ethresear.ch/c/plasma https://medium.com/l4-media/making-sense-of-web-3-c1a9e74dcae https://blog.ethereum.org/2018/01/02/ethereum-scalability-research-development-subsidy-programs/ https://github.com/ethereum/wiki/wiki/Sharding-FAQs https://medium.com/l4-media/making-sense-of-ethereums-layer-2-scaling-solutions-state-channels-plasma-and-truebit-22cb40dcc2f4 https://medium.com/@argongroup/ethereum-plasma-explained-608720d3c60e
本文的作者是盖盖,他的公众号: chainlab
深入浅出区块链 - 系统学习区块链,打造最好的区块链技术博客。
「深度学习福利」大神带你进阶工程师,立即查看>>>
开幕式现场
10月19日,Blockathon(2018)上海在黄浦区P2联合创业办公社举行,本次活动由50名区块链开发者组成9支参赛队伍,来自国内外优秀区块链开发团队的20名技术专家担任导师及裁判。9支队伍通过48小时的竞赛,于10月21日下午进行项目成果路演,角逐比赛奖杯。
Blockathon是全球性的区块链开发者竞赛,中国区的活动已经成功在北京和成都举办,本次上海站的比赛由bitfwd技术社区、HiBlock区块链社区以及区块链兄弟联合主办,邀请区块链技术爱好者进行小组竞赛,在48小时内完成一个区块链项目的开发交付。
区块链涵盖了推动信任和权力下放的新时代的技术,黑客马拉松是来自任何领域的人都可以聚集在一起并在特定时间框架内参与项目的活动。Blockathon通过将两者结合起来,组织现场包括分组、创意演示、开发培训、路演、评奖等多个环节。
HiBlock区块链社区合伙人王登辉主持开幕
在10月19日的开幕式现场,HiBlock区块链社区合伙人王登辉担任开幕式主持人,介绍整体活动,澳洲bitfwd开发者社区创始人Daniel、HiBlock区块链社区创始人Bob和区块链兄弟联合发起人方天叶对Blockathon(2018)上海站的活动进行开幕致辞,澳大利亚驻沪领事馆商务处商务领事 Dane Richmond表达了对活动的支持,他认为中澳的友好关系在这些活动中都能得到体现和发展。
澳大利亚驻沪领事馆商务处商务领事 Dane Richmond
澳洲bitfwd开发者社区创始人Daniel
HiBlock区块链社区创始人Bob
随后,NEM中国地区负责人李世庚、离子链联合创始人方天叶、Olympus协议核心开发者Orange分别介绍对各自代表的项目作了简单介绍,鼓励大家采用本项目的协议及技术,并介绍了活动期间在现场担任导师的技术专家,导师全程陪伴为参赛者提供技术支持与指导。
NEM中国地区负责人李世庚
离子链联合创始人方天叶
Olympus协议核心开发者Orange
Blockathon(2018)上海站的活动为期3天,10月20日上午是区块链开发培训环节,由OlympusLabs、Tenzorum及NEM三个优秀区块链开发团队的核心开发者以降低区块链应用的用户体验门槛为主题,分享各自的开发经验。
NEM技术分享
Tenzorum技术分享
OlympusLabs技术分享
本次活动邀请了《白话区块链》作者蒋勇、Bitcoin SPV开发者喵叔、因特链ChainX创始人岳利鹏、区块链兄弟技术社区创始人 冯翔、NEM中国地区负责人李世庚、铂链联合创始人& CTO王超、美国区块链媒体BTC Media亚太区CTO古千峰、火币区块链研究院 首席区块链分析师朱翊邦、Olympus协议核心开发者Orange、众为资本Venture Partner周欣华、 265 Ventures 创始合伙人刘桐彤、一百亿研究所创始人v女神、LongHash 区块链孵化器中东地区负责人王琴文、M Phase Consulting 联合创始人Queenie、NEM马来西亚Technical Trainer Anthony Law、TENZORUM项目CTO Radek Ostrowski等十多位区块链专家/投资者担任裁判,在各小组开发中给予指导性建议,并在10月21日下午路演环节中对最终的项目成果进行点评。
开发
技术指导
Blockathon(2018)上海站的活动获得了来自NEM、澳中理事会、离子链、Olympus Labs、HPB芯链、Tenzorum等的赞助支持,同时感谢P2联合创业办公社、以太坊爱好者社区、掘金、活动行、it大咖说登链学院等15家合作伙伴以及世链财经、共享财经、铱科技、陀螺财经等20家媒体的支持。
10月21日15:00,9个项目将进行现场路演,开放观众席,欢迎大家前来参加。
「深度学习福利」大神带你进阶工程师,立即查看>>> 本文转载自微信公号“万向区块链”,为慢雾安全负责人海贼王在万向区块链实验室举办的2018上海区块链国际周-技术开放日上的演讲速记整理。
这张图总结了智能合约攻防的各个方面,分为两大部分:链上攻防和链下攻防。
链上攻防
对于链上攻防,选取5个方面进行详细剖析。“Talk is cheap. Show me the code.” 下面开始展示源码详细解读。
1、溢出
因为没有使用 SaceMath导致的溢出造成金额可以在攻击者构造的数据中被任意控制,从而导致条件判断成立最终攻击者成功攻击了该智能合约。
此类问题避免方法:在做数字计算的相关代码处严格使用 SafeMath 进行做算术运算,防止溢出产生。
2、权限控制
此类权限控制属于权限问题中的一种,由于合约开发人员的不专业导致的代理转账函数中未进行授权判断,从而导致任何人都可以转走别人的钱。
此类问题避免方法:找专业的开发人员进行合约开发,同时合约开发人员也需要及时提高自己的开发技能以及专业能力,由于区块链的去中心和Token的特殊性很容易因为一个小的漏洞导致项目方从此身败名裂,所以建议项目上线之前找专业的安全审计团队出职业的审计报告,此类问题慢雾在审计的过程中一定能够发现并帮助项目方避免这种尴尬的情况。
3、条件竞争
此类问题为条件竞争导致的跨合约调用多次恶意转账最终攻击者成功完成攻击,在跨合约调用方面一直存在很大的问题,由于开发者的专业技能不够专业或者是合约设计的不合理等问题都会导致此类条件竞争。
此类问题避免方法:了解 Solidity 语言本身的函数使用场景以及底层实现,并且在业务逻辑上先扣除需要减去的账户金额再添加到对应账户并及时清零中间变量的临时值,避免因为事务的问题导致多入账导致损失,同时也要了解清楚Solidity中someAddress.call.value()方法 和 someAddress.transfer() 方法还有someAddress.send() 方法的区别。非常不建议使用 someAddress.call.value(),具体原因请大家一定要自己动手去查一下。
4、假充值
假充值这类问题是一个系列,比如XRP的假充值和USDT的假充值等,在这里只讲 ERC20 的假充值问题,这种问题是由于合约开发人员的逻辑判断代码不规范导致在以太坊的区块浏览器中可以看到原本一笔失败的转账状态为Success交易所在进行充值入账的时候也没有严格进行状态的判断和金额的校验从而导致了此类问题,此类问题杀伤力强,并且一次足以让一个交易所亏损上百万及千万,无论是开发者还是交易所都需要足够重视假充值的问题。
此类问题避免方法:合约开发中代码判断逻辑的地方使用 require()或者 assert()进行判断,如果条件不满足会直接导致 transfer 的失败同时状态也是 fail ,交易所钱包业务开发人员需要在充值的时候注意严格校验转账状态是成功还是失败,同时对充值金额也进行校验,确认真的到账后此笔交易才算成功。
5、恶意事件
此处需要说明这里的代码仅仅是我们编写作为演示使用的,目前暂时没有发现这种真是的攻击行为。由于区块链的数据都记录在链上,恶意记录 event 的事件可以直接修改对应的参数,如果此代码真是存在则上面讲的假充值就真的成了真充值了。
此类问题避免方法:做好 Code Review 和找专业的代码审计。
链下攻防
对于链下攻防,同样从5个方面详细剖析。
1、WEB
在之前发生的MyEtherWallet发生的域名劫持事件前,实际上相关的安全机构已经给出了中级风险的提示(如下图),但是它并没有对此重视。
专题介绍: https://mp.weixin.qq.com/s/-Yiul1QtSNa9JJAOuXCx3A
2、终端
对于硬件钱包的安全,也可能存在各种的安全隐患如:是否使用加密芯片,工业设计是否安全,做工是否很简陋不考虑丢失以及意外破损和能否以应对低温高温的情况下正常使用,最终需要考虑你到底是买了个硬件还是真正的硬件钱包?
3、节点
比如以太坊黑色情人节事件,攻击者通过在网络上通过 P2P协议发现新的以太坊全节点,然后构造好攻击脚本做好工程化等待时机对新搭建的全节点进行攻击,由于很多小白用户不懂得如何防御此类攻击所以到目前位置还是有很多团队不断被盗ETH。
详见慢雾的专题页:https://4294967296.io/eth214/
专题介绍: https://mp.weixin.qq.com/s/-Yiul1QtSNa9JJAOuXCx3A
慢雾的防御方法: https://mp.weixin.qq.com/s/Kk2lsoQ1679Gda56Ec-zJg
4、矿工
矿工有可能作恶,针对Dapp,进行选择性的打包。针对矿池,针对块代扣攻击等。
5、后端
后端的攻击举例为,USDT 假充值。
攻击步骤为:
1)向交易所钱包构造并发起⽆效(虚假)转账交易;
2)由于逻辑判断缺陷交易所将⽆效交易⼊账并计⼊到⽤户在交易所的资⾦账户;
3)⽤户发起提币;
4)交易所处理⽤户提币将币打到⽤户⾃⼰钱包地址;⽤户⾃⼰充币环节USDT 没有任何损失,提币环节交易所把⾃⼰真实的 USDT 币打给⽤户,造成交易所损失。
这背后的原理是:
USDT 是基于 Bitcoin 区块的 OMNI 协议资产类型,利⽤ Bitcoin 的 OP_RETURN 承载相关交易数据;
Bitcoin 本⾝并不会校验 OP_RETURN 数据的“合法性”,可以是任意数据;
Bitcoin 交易当区块确认数达到 6 的时候,就会被Bitcoin 节点承认;
那么,USDT 的交易在 OMNI 的节点上如何被确认的呢?
int64_t nBalance =
getMPbalance(sender,property, BALANCE);
说明:通过上⾯的代码来看,OMNI内部有⾃⼰的⼀套基于地址的记账模型,通过地址可以获取地址的余额。
因此,为了避免以上问题。⼀笔 USDT 的交易合法的,要⾄少满⾜以下两个条件:
(1)要通过⽐特币的交易来构造,要符合⽐特币的余额验证(BTC)及交易规则验证
(2)要通过 USDT ⾃⼰的余额(USDT)验证
对于USDT 假充值,当余额不足时会发生什么?
{"amount": "28.59995822",
"block": 502358,
"blockhash": "0000000000000000005968fa48c49d7c4fb2363369d59db82897853fd937c71a",
"blocktime": 1514985094,
"confirmations": 37854,
"divisible": true,
"fee": "0.00200000",
"flags": null,
"invalidreason": "Sender has insufficient balance",
"ismine": false,
"positioninblock": 301,
"propertyid": 31,
"propertyname": "TetherUS",
"referenceaddress": "1Po1oWkD2LmodfkBYiAktwh76vkF93LKnh",
"sendingaddress": "18DmsHjHU6YM2ckFzub4pBneD8QXCXRTLR",
"txid": "1b5c80f487d2bf8b69e1bbba2b1979aacb1aca7a094c00bcb9abd85f9af738ea",
"type": "Simple Send",
"type_int": 0,
"valid": false,
"version": 0 }
另外,有些黑客非常有心机,在一些百度回答等贴上错误的代码,如果程序员不仔细检查或者对智能合约不熟悉,直接复制粘贴代码,则容易遭受攻击。要如何提升安全呢?首先开发人员拥有安全开发意识,其次还是要找专业的安全团队做专业的审计。
「深度学习福利」大神带你进阶工程师,立即查看>>>
这一系列文章将围绕以太坊的二层扩容框架,介绍其基本运行原理,具体操作细节,安全性讨论以及未来研究方向等。本篇文章作为开篇,主要目的是理解 Plasma 框架。
Plasma 作为以太坊的二层扩容框架,自从 2017 年被 Joseph Poon(Lightning Network 创始人)和 Vitalik Buterin (Ethereum 创始人)提出以来[1],一直是区块链从业人员关注的焦点[2]。首先需要明确的是,Plasma 实质上是一套框架,而不是一个单独的项目,它为各种不同的项目实际项目提供链下(off-chain)解决方案。这也是为什么很多人对 Plasma 感到疑惑的一个重要原因,因为在缺乏实际应用场景的情况下很难将 Plasma 解释清楚。 因此,理解 Plasma 是一套框架是理解 Plasma 的关键。
1
从区块链扩容谈起
在介绍 Plasma 之前,不得不先介绍区块链扩容。我们都知道,比特币(Bitcoin)和以太坊(Ethereum)作为目前最广泛使用的区块链平台,面临的最大问题就是可扩展性(Scalability)。这里需要注意的是,区块链中的可扩展性问题并不是单独特指某个问题,而是区块链想要实现 Web3.0[3] 的愿景,为亿万用户提供去中心化服务所要克服的一系列挑战。虽然以太坊号称是“世界计算机”,但这台“计算机”却是单线程的,每秒钟只能处理大约 15 条交易,与目前主流的 Visa 和 MasterCard 动辄每秒上万的吞吐量相比实在相形见绌。因此如何在保证区块链安全性的情况下,提高可扩展性是目前区块链发展亟待解决的问题之一。
目前关于区块链扩容的解决方案无外乎两个方向:一层(Layer 1)扩容和二层(Layer 2)扩容[4]。一层扩容也被称为链上(on-chain)扩容,顾名思义,这类扩容方案需要更改区块链底层协议。但同时也意味着需要将区块链硬分叉。这类扩容方案就像将原来的单核 CPU 改装成多核 CPU,从而可以多线程处理计算任务,提高整个网络的吞吐量。
目前最典型的一层扩容方案是 Vitalik 和他的研究团队提出的“Sharding(分片)”,也就是说将区块链划分成不同的部分(shards),每个部分独立处理交易。想要了解更多关于 Sharding 的信息,可以参考以太坊官方的 Wiki[5]。
二层扩容也称链下(off-chain)扩容,同样非常好理解,这种扩容方案不需要修改区块链底层协议,而是通过将大量、频繁的计算工作转移到“链下”完成,并定期或在需要时将链下的计算结果提交到“链上”保证其最终性(finality)。二层扩容的核心思想是将底层区块链作为共识基础,使用智能合约或者其它手段作为链下和链上沟通的桥梁,当有欺诈行为发生时链下的用户仍然可以回到链上的某一状态。虽然将计算转移到链下会在一段时间内损失最终性,但这个代价是值得的,因为这样做不止可以极大提高区块链的灵活性和可扩展性,也极大降低了用户进行交易所需要的代价。将计算转移到链下也并不意味着完全放弃安全性,因为最终的安全性还是由底层所依赖的区块链来保证,因此二层扩容主要关注的问题就在于如何保证链上链下切换过程的安全性。这种思想最早被用在闪电网络(Lightning Network)当中作为比特币的其中一个扩容方案,并取得了很好的效果。
本文所要介绍的 Plasma 就属于基于以太坊二层扩容方案,类似的解决方案还有 State Channels和 Trubit。这些方案虽然面向的问题有所区别,但基本思想都是将复杂的计算转移到链下进行。那么,接下来我们将进入 Plasma 的世界,一窥究竟!
2
理解Plasma
在前文中我们已经明白 Plasma 是一种二层扩容框架,那么该如何进一步理解 Plasma 是什么?它区别于其它二层扩容方案的地方在哪呢?
Plasma 也被称为“链中链(blockchains in blockchains)”。任何人都可以在底层区块链之上创建不同的 Plasma 支持不同的业务需求,例如分布式交易所、社交网络、游戏等。
这里可以举一个例子来理解 Plasma。假如企鹅公司创建了一个 Plasma Chain 叫作 Game Chain。用户通过向 Game Chain 发送一些以太币换取 Token,用于购买皮肤等游戏内的增值商品。加入 Game Chain 的操作是在链上进行的,以太坊区块链将这部分资产锁定,转移到 Game Chain 上。之后每次我们购买虚拟商品的交易就会转移到链下进行,由企鹅公司记账。这种方式几乎跟我们现实生活中游戏内购的体验一样,不仅结算迅速,而且手续费低廉(相比于以太坊之上需要给矿工支付的手续费)。那么问题来了,如果企鹅公司从中作祟,修改账本,恶意占有我们的资产怎么办?这时我们就可以提交之前每次交易的凭证到以太坊区块链上,如果确实是企鹅恶意篡改了账本,那么我们不但能够成功取回自己的资产,还能获得之前企鹅公司创建 Game Chain 存入的部分或全部押金。
通过上面这个例子是不是已经明白 Plasma 大致是如何工作的了?但上面这个例子还是过于简单,只涉及用户自己和企鹅公司。下面我们使用区块链的语言对上面的例子进行解析。
首先,企鹅公司在以太坊主链之上创建了一系列智能合约作为主链和子链 Game Chain 通信的媒介。这些智能合约中不仅规定了子链中的一些基本的状态转换规则(例如如何惩罚作恶的节点),也记录了子链中的状态(子链中区块的哈希值)。之后企鹅公司可以搭建自己的子链(可以用以太坊搭建一套私链)。子链实际上是一个完全独立的区块链,可以拥有专门的矿工,使用不同于主链的共识算法,例如 PoS(Proof of Stake)等。
当子链创建完毕后,企鹅公司可以使用 ERC721 合约创建 token 作为游戏内的商品(就像 Cryptokitty)。但这里需要注意的是,所有数字资产必须在以太坊主链上创建,并通过 Plasma 子链的智能合约转移到子链中。用户也需要在主链上购买数字资产后转移到子链上。在上面这个例子中,Game Chain 的智能合约将主链上的资产锁定,之后在子链上生成等值的资产。之后用户就可以完全脱离主链,在子链上进行交易。企鹅公司在子链上扮演 operator 的角色,如果一切运行正常,子链中的矿工会正常打包区块,并在需要时由 operator 将区块的哈希值提交到主链作为子链的状态更新证明。在这个过程中,用户完全不需要和主链交互。
我们可以看到,将复杂的计算操作转移到链下确实使得整个交易过程变得简单。但没有强大的共识算法和庞大的参与者,资产在子链上是很不安全的。Plasma 给了我们一种避险机制,即使 operator 作恶,我们也能取回属于自己的资产。下图(来源自[1])简单说明了这个过程。图中,在第 4 个区块中的交易被篡改。由于 Alice 本地保存有 Plasma Chain 中所有的区块数据,因此她可以向主链提交一个含有“防伪证明(Fraud Proof)”的交易。如果证明生效,那么主链将状态从 4 号区块回滚到 3 号区块,一切恢复正常。Plasmas Chain 中的参与者也可以随时提交资产证明,返回到主链。
到这里我们应该已经理解了,Plasma 所要做的工作并不是保护子链的安全,而是当有安全事故发生时,保证用户可以安全地取回自己的资产,并返回到主链上。并且采用一系列经济激励的方式减少作恶情况的发生。
下一篇文章将对 Plasma 运行过程的细节进行剖析。
3
相关资源
相关资源 https://plasma.io/ https://ethresear.ch/c/plasma https://medium.com/l4-media/making-sense-of-web-3-c1a9e74dcae https://blog.ethereum.org/2018/01/02/ethereum-scalability-research-development-subsidy-programs/ https://github.com/ethereum/wiki/wiki/Sharding-FAQs https://medium.com/l4-media/making-sense-of-ethereums-layer-2-scaling-solutions-state-channels-plasma-and-truebit-22cb40dcc2f4 https://medium.com/@argongroup/ethereum-plasma-explained-608720d3c60e 内容来源:知乎 原文作者:盖盖
区块链马拉松|Blockathon(2018)上海 邀请你来观看路演啦~
时间:2018年10月21日15:00-17:00
地点:上海市黄浦区柳泉弄1号2楼(P2·露香园)
免费参加,还有礼品哦
报名方式:识别下图二维码或者点击“ 阅读原文 ”即可报名。
北京blockathon回顾:
Blockathon(北京):48小时极客开发,区块松11个现场交付项目创意公开
成都blockathon回顾:
Blockathon2018(成都站)比赛落幕,留给我们这些区块链应用思考
「深度学习福利」大神带你进阶工程师,立即查看>>>
通过本文学习,熟悉了解以太坊智能合约语言Solidity语法中constant,view,pure的区别。
1
区别总结
在Solidity中constant,view,pure三个函数修饰词的作用是告诉编译器,函数不改变/不读取状态变量,这样函数执行就可以不消耗gas了(是完全不消耗!),因为不需要矿工来验证。
在Solidity v4.17之前,只有constant,后来有人嫌constant这个词本身代表变量中的常量,不适合用来修饰函数,所以将constant拆成了view和pure。 view的作用和constant一模一样,可以读取状态变量但是不能改; pure则更为严格,pure修饰的函数不能改也不能读状态变量,否则编译通不过。
大家可以运行以下测试代码来加深这3个关键字的理解。 contract constantViewPure{ string name; uint public age; function constantViewPure() public{ name = "liushiming"; age = 29; } function getAgeByConstant() public constant returns(uint){ age += 1; //声明为constant,在函数体中又试图去改变状态变量的值,编译会报warning, 但是可以通过 return age; // return 30, 但是!状态变量age的值不会改变,仍然为29! } function getAgeByView() public view returns(uint){ age += 1; //view和constant效果一致,编译会报warning,但是可以通过 return age; // return 30,但是!状态变量age的值不会改变,仍然为29! } function getAgeByPure() public pure returns(uint){ return age; //编译报错!pure比constant和view都要严格,pure完全禁止读写状态变量! return 1; } }
2
详细描述
2.1 Constant 状态变量
状态变量可以被声明为 constant。在这种情况下,只能使用那些在编译时有确定值的表达式来给它们赋值。 任何通过访问 storage,区块链数据(例如 now, this.balance 或者 block.number)或执行数据( msg.gas ) 或对外部合约的调用来给它们赋值都是不允许的。 在内存分配上有边界效应(side-effect)的表达式是允许的,但对其他内存对象产生边界效应的表达式则不行。 内建(built-in)函数 keccak256,sha256,ripemd160,ecrecover,addmod 和 mulmod 是允许的(即使他们确实会调用外部合约)。
允许带有边界效应的内存分配器的原因是这将允许构建复杂的对象,比如查找表(lookup-table)。 此功能尚未完全可用。
编译器不会为这些变量预留存储,它们的每次出现都会被替换为相应的常量表达式(这将可能被优化器计算为实际的某个值)。
不是所有类型的状态变量都支持用 constant 来修饰,当前支持的仅有值类型和字符串。 pragma solidity ^0.4.0; contract C { uint constant x = 32**22 + 8; string constant text = "abc"; bytes32 constant myHash = keccak256("abc"); }
2.2 View 函数
可以将函数声明为 view 类型,这种情况下要保证不修改状态。
下面的语句被认为是修改状态: 修改状态变量。 产生事件( https://solidity-cn.readthedocs.io/zh/develop/contracts.html?highlight=view#events)。 创建其它合约( https://solidity-cn.readthedocs.io/zh/develop/control-structures.html#creating-contracts)。 使用 selfdestruct。 通过调用发送以太币。 调用任何没有标记为 view 或者 pure 的函数。 使用低级调用。 使用包含特定操作码的内联汇编。 pragma solidity ^0.4.16; contract C { function f(uint a, uint b) public view returns (uint) { return a * (b + 42) + now; } }
注解: onstant 是 view 的别名。 Getter 方法被标记为 view。 编译器没有强制 view 方法不能修改状态。
2.3 Pure 函数
函数可以声明为 pure ,在这种情况下,承诺不读取或修改状态。
除了上面解释的状态修改语句列表之外,以下被认为是从状态中读取: 读取状态变量。 访问 this.balance 或者
.balance。 访问 block,tx, msg 中任意成员 (除 msg.sig 和 msg.data 之外)。 调用任何未标记为 pure 的函数。 使用包含某些操作码的内联汇编。 pragma solidity ^0.4.16; contract C { function f(uint a, uint b) public pure returns (uint) { return a * (b + 42); } }
警告
编译器没有强制 pure 方法不能读取状态。 本文作者:HiBlock区块链社区技术布道者辉哥
原文发布于简书
区块链马拉松|Blockathon(2018)上海 邀请你来观看路演啦~
以下是我们的社区介绍,欢迎各种合作、交流、学习:)
「深度学习福利」大神带你进阶工程师,立即查看>>>
Py-EVM是用Python编写的以太坊虚拟机的新实现。目前github上695个star,正在积极开发中,但正在通过以太坊/测试提供的测试套件快速推进。我们感谢有Vitalik和现有的PyEthereum代码,使得我们有的快速进步,因为许多设计决策都受到启发,甚至直接从PyEthereum代码库移植。
Py-EVM旨在最终成为EVM的事实Python实现,为公共和私有链提供广泛的用例。开发将侧重于创建具有良好定义的API的EVM,友好且易于理解的文档,可作为功能齐全的主网节点运行。
特别是Py-EVM目标旨在: 提供是一种使用最广泛使用和理解的语言之一Python的EVM的示例实现。 为客户提供低级API,以构建完整或轻量级节点。 易于理解和修改。 高度灵活地支持研究以及私有区块链等替代用例。
Trinity
虽然Py-EVM提供EVM的低级API,但它并不旨在直接实现完整节点或轻节点。
我们提供了一个基于Py-EVM的称为Trinity的完整节点的基本实现。
将来可能会有基于Py-EVM的替代客户端。
第1步:Alpha发布
该计划首先是适用于测试目的的MVP,alpha级发布。我们将寻找早期采用者,以提供有关我们的架构和API选择的反馈,以及一般反馈和错误发现。
开发
Py-EVM依赖于所有客户端的常见测试的子模块,因此你需要使用--recursive标记克隆repo。例如: git clone --recursive git@github.com:ethereum/py-evm.git
Py-EVM需要Python 3。通常,保证干净的Python 3环境的最佳方法是使用virtualenv,例如: # once: $ virtualenv -p python3 venv # each session: $ . venv/bin/activate
然后通过以下方式安装所需的python包: pip install -e .[dev]
运行测试
可以使用以下命令运行测试: pytest
或者你可以安装 tox 来运行完整的测试套件。
Releasing
需要Pandoc才能将markdown README转换为正确的格式,以便在pypi上正确呈现。
对于类似Debian的系统: apt install pandoc
在OSX上: brew install pandoc
要发布新版本: bumpversion $$VERSION_PART_TO_BUMP$$ git push && git push --tags make release
去新建一个docker镜像: make create-docker-image version=
默认情况下,这将创建一个新镜像,其中有两个标记指向它: ethereum/trinity: :(显示版本) ethereum/trinity:latest :(最新的,直到用未来的“最新”覆盖)
然后,推送到docker hub。 docker push ethereum/trinity: # the following may be left out if we were pushing a patch for an older version docker push ethereum/trinity:latest
如何使用bumpversion
此repo的版本格式为 {major}.{minor}.{patch} 表示stable, {patch}.{minor}.{patch}-{stage}.{devnum} 表示unstable(stage可以是alpha或beta))。
要在发布下一个版本,请使用bumpversion并指定要调整的部分,例如bumpversion minor或bumpversion devnum。
如果你处于beta版,则bumpversion stage阶段将切换为稳定版。
要在当前版本稳定时发出不稳定版本,请明确指定新版本,例如 bumpversion --new-version 4.0.0-alpha.1 devnum
学习文档: Documentation hosted by ReadTheDocs
======================================================================
分享一些以太坊、EOS、比特币等区块链相关的交互式在线编程实战教程:
python以太坊 ,主要是针对python工程师使用web3.py进行区块链以太坊开发的详解。
这里是 原文

.png) 大数据引擎
大数据引擎.png) 大数据应用
大数据应用.png) 大数据底层技术
大数据底层技术.png) ForeSpider软件
ForeSpider软件
.png) 采集服务
采集服务.png) 软件学习
软件学习.png) 智能分析
智能分析.png) 特征提取
特征提取.png) 智能计算
智能计算.png) 数据可视化
数据可视化.png) 数据分析应用
数据分析应用.png) 系统集成服务
系统集成服务.png) 代码工具
代码工具.png) 金融方案
金融方案.png) 制造业&物流
制造业&物流.png) 企业数字化
企业数字化.png) 医疗方案
医疗方案.png) 政务方案
政务方案.png) 实时监测
实时监测.png) 智能分析
智能分析.png) 数据智能挖掘
数据智能挖掘.png) 全网自动采集
全网自动采集.png) 场景智慧采集
场景智慧采集.png) 主题识别采集
主题识别采集
 注册即送:30天知析标讯会员权益
注册即送:30天知析标讯会员权益
 022-2345 2937
022-2345 2937 185 2247 0110
185 2247 0110 business@forenose.com
business@forenose.com 客服微信
客服微信 订阅号
订阅号 服务号
服务号








 022-2345 2937
022-2345 2937 185 2247 0110(同微信)
185 2247 0110(同微信) business@forenose.com
business@forenose.com 2779623375
2779623375 前嗅大数据
前嗅大数据